Zebra-CoT A Dataset for Interleaved Vision Language Reasoning
Zebra-CoT is a large-scale dataset with 182,384 interleaved text-image reasoning traces across 18 domains for training multimodal models.
Read Paper →Method
The Zebra-CoT dataset is constructed by sourcing data from real-world problems and generating synthetic examples. The dataset contains 182,384 interleaved text and image reasoning traces across four main categories: scientific questions, 2D visual reasoning, 3D visual reasoning, and visual logic/strategic games.
Data curation begins by sourcing problems from online resources for domains like mathematics, physics, and chess. Raw reasoning traces containing text and images are extracted and cleaned. For synthetic data, images are generated or sourced online, and corresponding reasoning templates are created. To enhance the logical coherence and narrative of these traces, frontier Vision Language Models (VLMs) like Gemini-2.5 and GPT-4.1 are used to populate templates and refine raw text traces. The models are provided with images and raw text and tasked with generating a clean, pure-text trace with placeholders for images. The resulting data is filtered to remove invalid samples, such as those with unreferenced or improperly referenced images, to ensure it can be parsed for training.
The dataset is organized into the following categories:
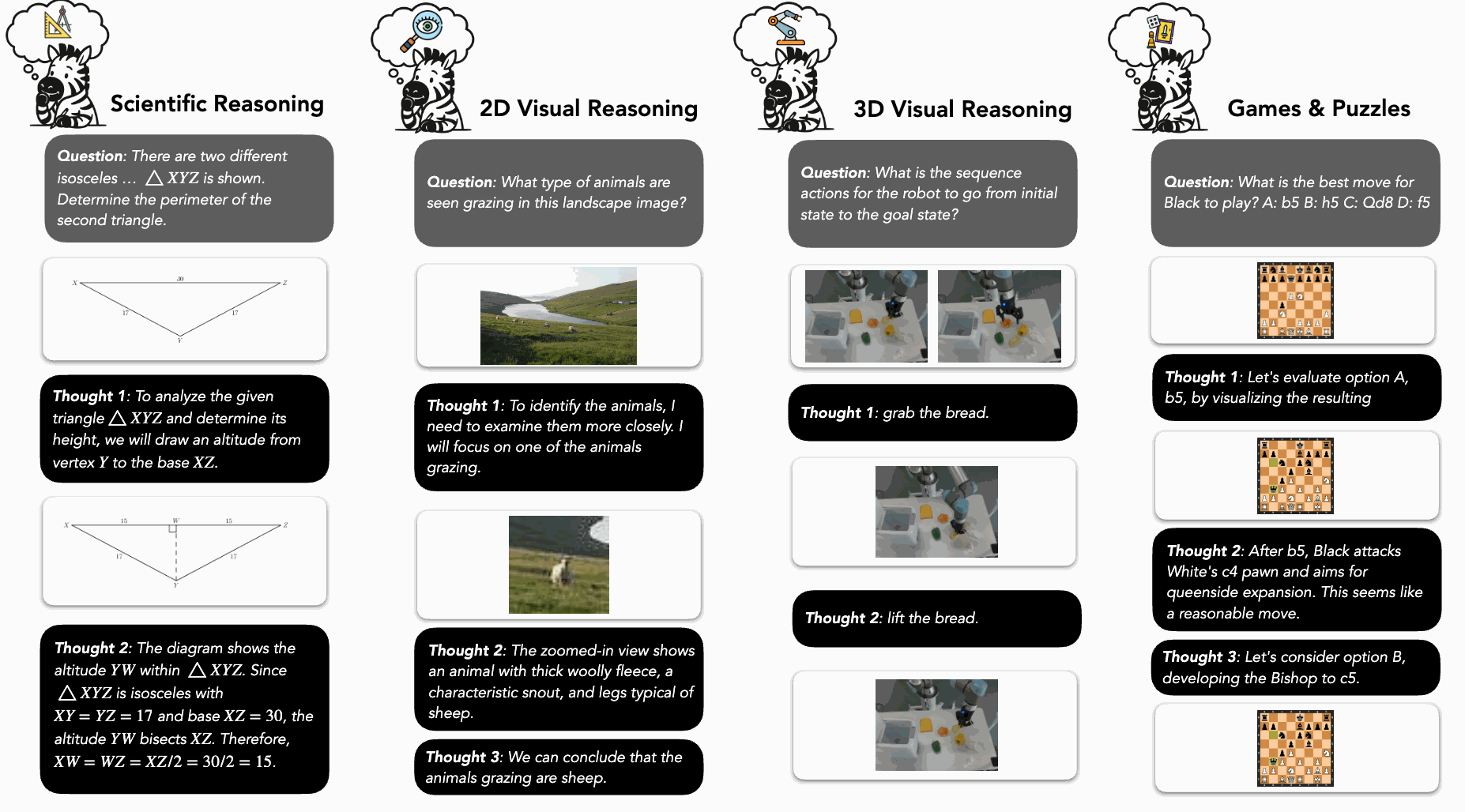
- Scientific Questions: This category includes subdomains such as geometry, physics, chemistry, algorithmic problems, and graph problems. Data is derived from openly licensed datasets and textbooks. Gemini-2.5 is used to parse and structure the data into visual CoT formats. For algorithmic tasks, a GPT-4.1 based agent is used to produce detailed reasoning traces.

- 2D Visual Reasoning: This includes visual search and visual jigsaw tasks. For visual search, existing datasets are adapted to incorporate two types of visual aids: bounding boxes and zoomed-in regions. For visual jigsaw tasks, puzzles are created by cropping images from ImageNet with a random number of missing pieces. The visual CoT for these tasks involves either iteratively filling in the missing pieces or reconstructing the original image.

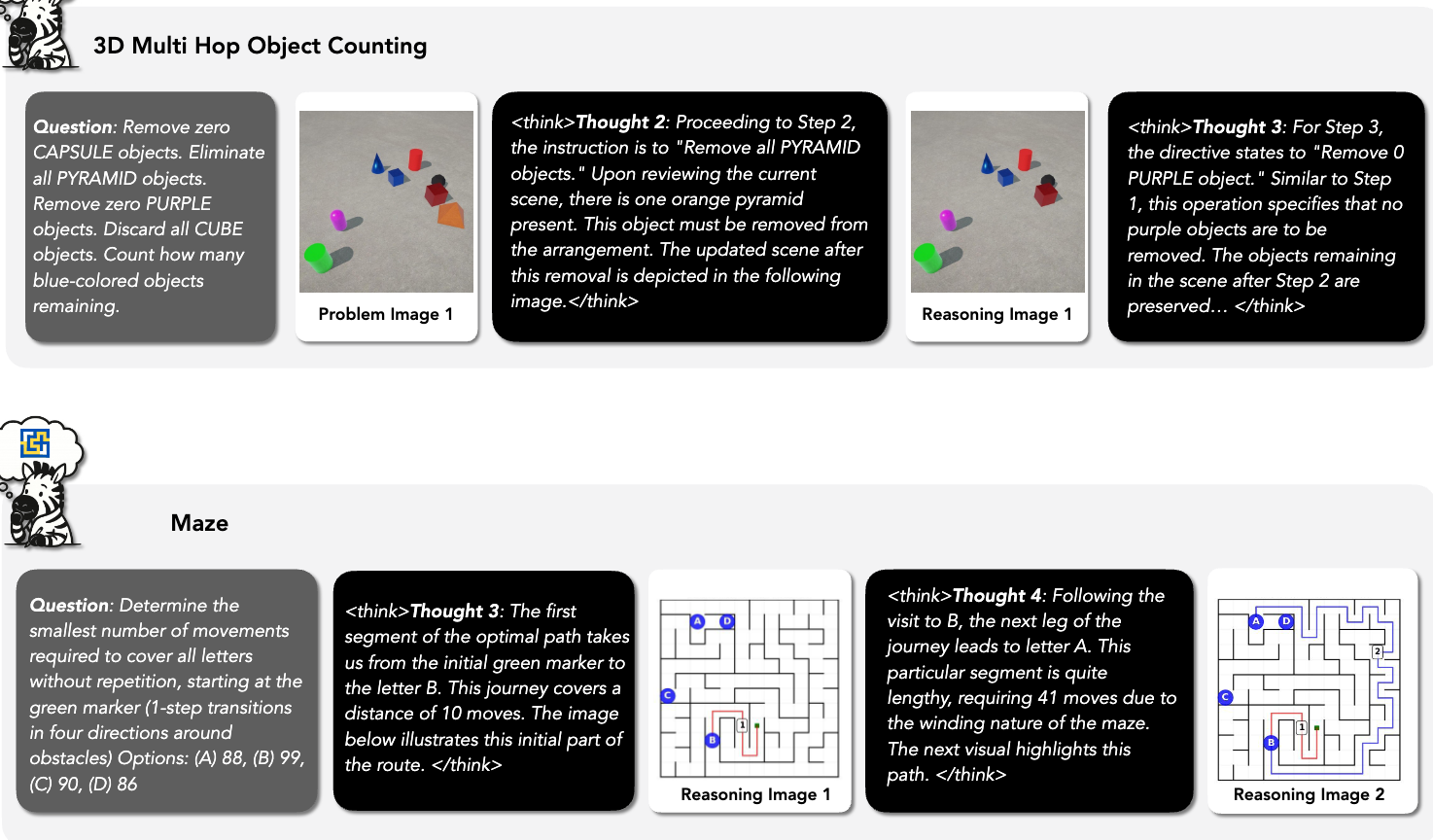
- 3D Visual Reasoning: This area focuses on embodied reasoning/robotic planning and understanding 3D transformations. For planning, the ALFRED and RoboMIND benchmarks are adapted into image goal-conditioned planning tasks where models generate step-by-step plans. For 3D transformations, multi-hop object counting tasks are designed, requiring models to reason through sequential modifications to a scene.

- Visual Logic and Strategic Games: This category includes tasks like IQ matrices, Tetris, ciphers, ARC-AGI, chess, checkers, Connect Four, and mazes. Visual CoT traces are constructed with explicit intermediate visual transformations. For strategic games like chess, this involves rendering board states for different potential moves to aid in planning.
Experiments
Analysis with Proprietary Models
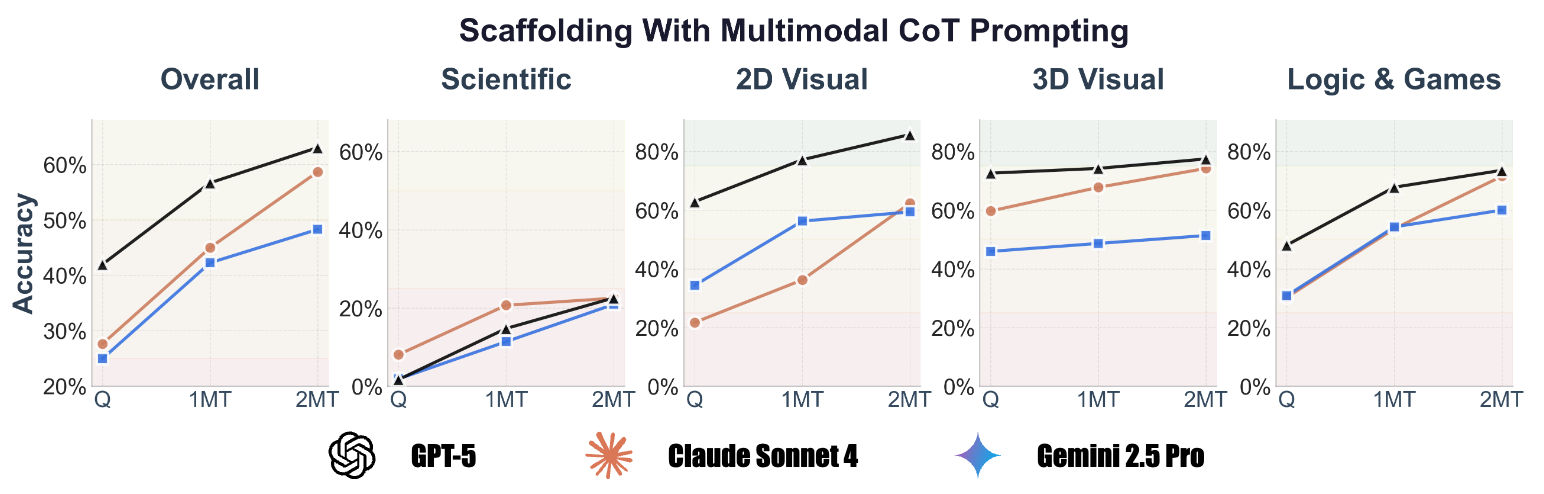
A scaffolding experiment was conducted to evaluate the performance of proprietary models (GPT-5, Gemini-2.5 Pro, Claude-4 Sonnet) on a subset of 512 questions from Zebra-CoT. The dataset’s reasoning traces are structured as a sequence: <question> → <text-reasoning-1> → <visual-reasoning-1> → ... → <answer>.
Models were evaluated in three settings:
- Zero-shot (Q): Models are given only the
<question>. - 1MT (\(k=1\)): Models are given the context of the first multimodal reasoning step:
<question> + <text-reasoning-1> + <visual-reasoning-1>. - 2MT (\(k=2\)): Models are given the context of the first two steps:
<question> + <text-reasoning-1> + <visual-reasoning-1> + <text-reasoning-2> + <visual-reasoning-2>.
Fine-tuning Experiments
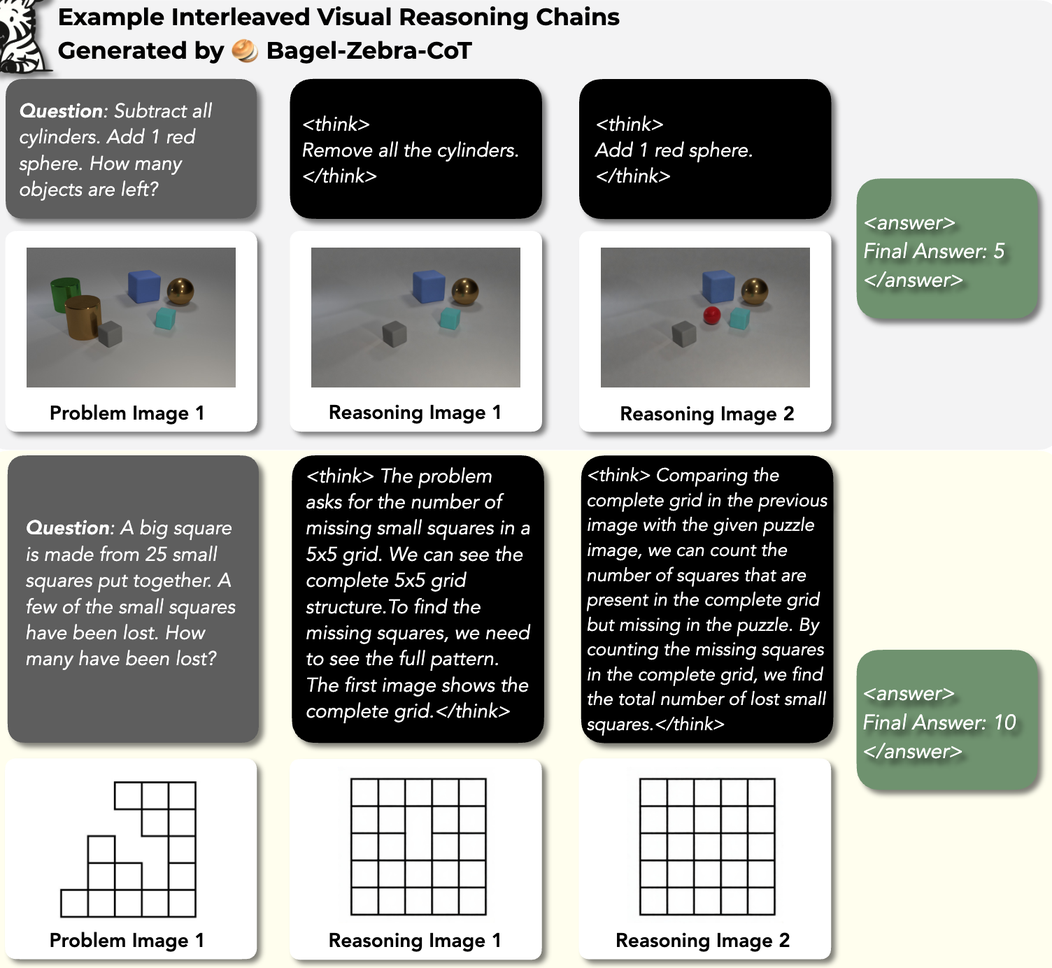
Two models were fine-tuned on the Zebra-CoT dataset.
-
- On the in-distribution test set, accuracy improved from 4.2% to 16.9%.
- When evaluated on seven external visual reasoning benchmarks, the fine-tuned model showed an average performance improvement of 4.9%, with a gain of up to 13.1% on a visual logic benchmark compared to the base Anole model with CoT prompting.

- Bagel-Zebra-CoT: The Bagel-7B model was fine-tuned for 1,000 steps with a learning rate of \(2 \times 10^{-5}\) using packed sequences. The training loop was modified to include a loss term at the
<|vision_start|>token to enable native generation of interleaved text and images.- The fine-tuned model is capable of generating interleaved visual CoT traces for problem-solving, including on tasks outside its training distribution.
Model is Chameleon to be able to generate reasoning traces.
They used 8xH200 for 12 hours for fine-tuning.