What do we learn from inverting CLIP models?
summary of What do we learn from inverting CLIP models?
https://arxiv.org/pdf/2403.02580v1 how to use CLIP as a text to image? by doing this optimization:
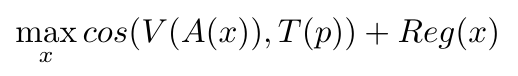
V is the vision part of CLIP, T is the test part of CLIP, A(x) is a random augmentation of x and Reg(x) is a regularization of x.