Towards Monosemanticity Decomposing Language Models With Dictionary Learning
How SAE works
Given a transformer network, the researchers aim to understand the MLP activations. Their learn an autoencoder, as illustrated in the image below:
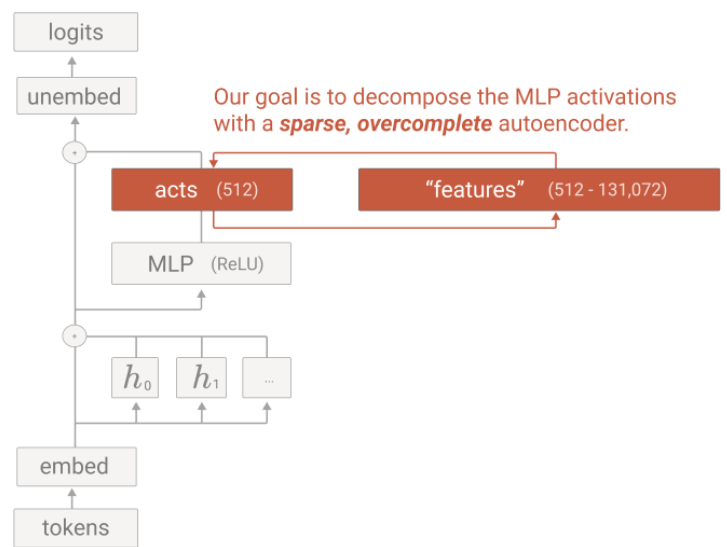
In this approach, a linear layer +ReLU projects the activations to a much larger space and then projects them back to the MLP activation space. These two layers are trained to minimize the reconstruction error while maximizing the middle layer sparsity. Which they do with a MSE loss for reconstruction and a L1 loss for sparsity. The sparse autoencoder reconstructs MLP activations using a network with one hidden layer. Thus, the process is as follows:
MLP activations —(linear+ReLU)—> hidden layer (sparse features) —(linear)—> MLP activations.
The Theory About the Neural Network
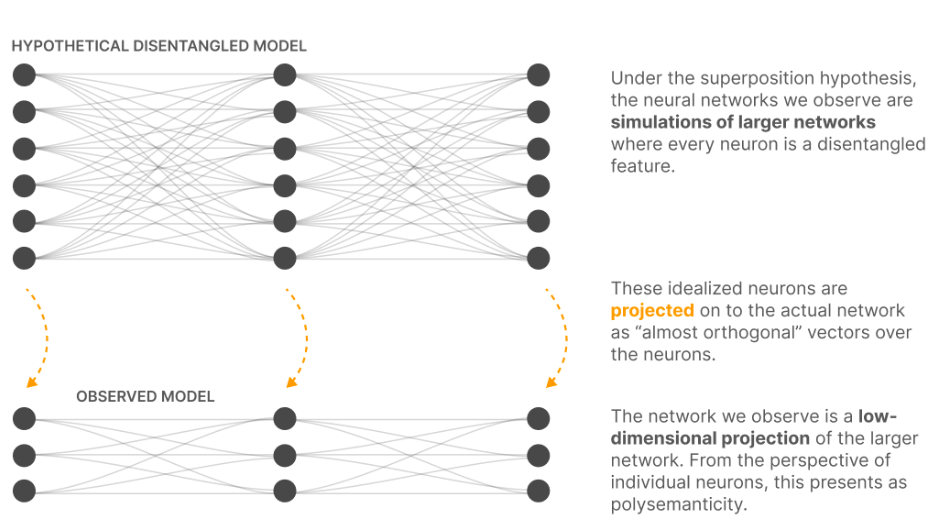
The researchers hypothesize that our neural networks simulate much larger, much sparser neural networks.
Checking one of the learned features (Arabic Script)
The study investigates four features, but I will only explain the Arabic script feature.
When this feature is active, the context is Arabic. Arabic text is relatively rare in the overall data distribution, constituting just 0.13% of the training tokens. However, it accounts for 81% of the tokens where this feature is active.
They noted some gaps in this feature’s functionality. For instance, it does not activate on “ال,” which means “the” in Arabic. However, there is another Arabic feature that primarily activates on “ال.” By combining these features, the model can effectively detect Arabic script.
They also tested the causal effect of this feature by activating it manually, observing that the score for Arabic characters increases for the next token prediction.
They found that the this feature is kinda universal between different models. It means, when training the network with a different seed, the same feature emerged.
How Do They Know These SAE Features Are Interpretable?
The researchers employed several methods.
Manual Human Analysis
The first method involves presenting several samples where a feature or neuron is active and asking one of the co-authors to guess the function of this feature/neuron. They recorded the co-author’s confidence level—higher confidence indicates that the feature/neuron is more likely meaningful. They found that the confidence on the median neuron is 0, suggesting that the co-author couldn’t form a hypothesis about the neuron’s function. However, the median confidence on features is higher, indicating that meaning can be easily discerned in randomly chosen features. This shows that many of the learned features are probably interpretable.
Automated Interpretability – Activations
An LLM is used to analyze many samples where a feature is activated and produce an explanation. Then, using this explanation, the model predicts feature activation on other samples. The effectiveness of this method is measured by the Spearman correlation coefficient between the predicted activations and the true activations for 60 dataset examples.
How Much of the Model Does SAE Explain?
They demonstrated that replacing the original activations with SAE reconstructions allows them to recover 94.5% of the log-likelihood loss.
Feature Splitting
When the number of features (hidden layer size) is increased, the existing features split into multiple features.