TheoremLlama Transforming General-Purpose LLMs into Lean4 Experts
This paper proposes an end-to-end framework and dataset generation pipeline to train large language models for formal mathematical theorem proving in Lean 4.
Read Paper →Method
The framework consists of three main components: a dataset generation pipeline that produces aligned Natural Language (NL) and Formal Language (FL) data, a set of training methods tailored for LLM formal theorem proving, and an iterative proof-writing strategy.
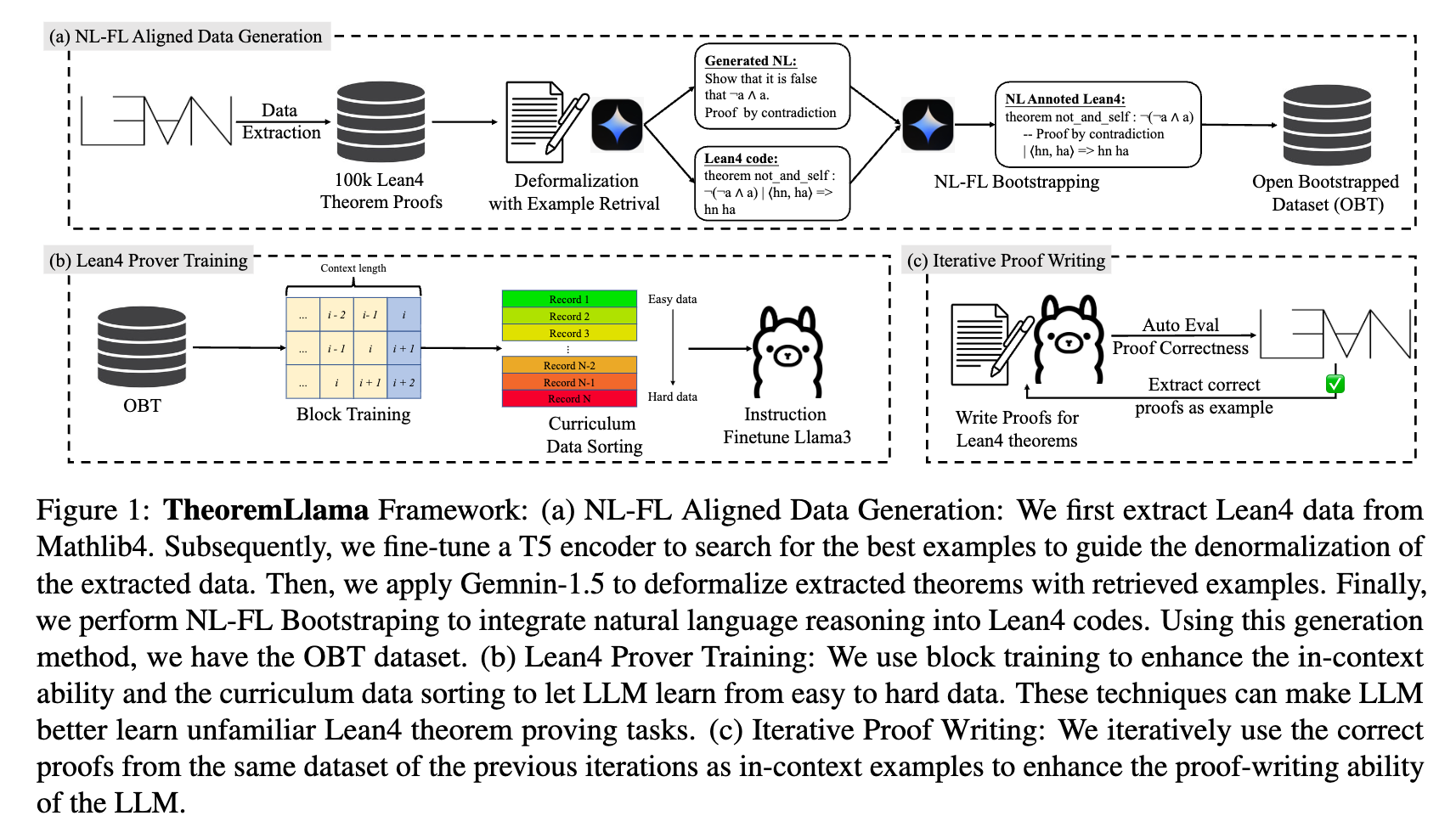
NL-FL Aligned Data Generation
To address the lack of aligned NL-FL theorem-proving data for Lean 4, the framework produces a dataset called Open Bootstrapped Theorems (OBT) containing 106,852 aligned and bootstrapped theorems.
Lean 4 Proof Extraction The process begins by extracting approximately 100k formal theorems and proofs from Mathlib4, a repository containing Lean 4 formalizations for various mathematical disciplines.
Deformalization with Example Retrieval Because Mathlib4 lacks corresponding natural language statements for most theorems, the formal statements are “deformalized” into natural language. To provide high-quality in-context examples for the LLM performing this deformalization, an example retrieval method is used. A ByT5-Tacgen model is fine-tuned to align the cosine similarity of natural language theorem statements with Lean 4 code. Sentence-level encodings are obtained via mean pooling. In-batch negative sampling is applied, yielding the following fine-tuning loss function:
\[\mathcal{L} = 1 - \cos(\boldsymbol{x}_{NL}, \boldsymbol{x}_{FL}) + \frac{1}{2}(\cos(\boldsymbol{x}_{NL}^{(-)}, \boldsymbol{x}_{FL}) + \cos(\boldsymbol{x}_{NL}, \boldsymbol{x}_{FL}^{(-)}))\]where \(\boldsymbol{x}_{NL/FL}\) represents the sentence encoding and \(\boldsymbol{x}^{(-)}\) denotes an unaligned NL/FL statement in the same batch used as a negative sample. Examples with the highest similarity are retrieved and used as in-context prompts for Gemini-1.5-Pro to generate the natural language statements and proofs for the Mathlib4 theorems. Repeated or over-length generations are filtered out during a quality check.
NL-FL Bootstrapping To connect natural language reasoning with Lean 4 execution, natural language steps are integrated directly into the Lean 4 proofs as comments. An LLM is provided with both the NL and FL versions of a theorem and prompted to document the natural language proof steps as comments within the Lean 4 code. A verification algorithm strips these comments and compares the underlying code to the original Mathlib4 code to ensure structural correctness.
LLM Prover Training
The LLM is fine-tuned to generate whole proofs based on natural language guidance. Two specific techniques are applied during instruction fine-tuning.
Block Training To incorporate in-context learning during training, the dataset is processed as a continuous sequence of text. The context length of the LLM is filled with consecutive examples from previous records. The formatted training data for the \(i\)-th record is:
{"Instruction": "$NL_{i-k}, FL_{i-k}; \dots FL_{i-1}; NL_i$", "Target": "$FL_i$"}
where \(k\) is the number of prior examples that fill the context window.
Curriculum Data Sorting The generated training dataset is reorganized by difficulty. Difficulty is measured by the number of steps required to solve all goals in a Lean 4 proof. Training records are sorted such that the model processes simpler proofs first and progresses to more complex proofs, which helps stabilize the training loss curve.
Instruction Fine-tuning The Llama3-8B-Instruct model is fine-tuned autoregressively using the block training and curriculum data sorting techniques on the OBT dataset. The input instruction consists of a natural language statement, a natural language proof, and a Lean 4 theorem statement. The target output is the Lean 4 proof bootstrapped with natural language explanations.
Iterative Proof Writing
An iterative inference strategy is used to refine the model’s proof-writing capability. The prover first generates proofs for as many theorems in the target dataset as possible. The correctly generated, Lean-verified proofs are then appended as additional in-context examples for the next generation iteration. This process stops when a maximum number of steps is reached or when no new theorems are successfully proved.
Experiments
Experiment Setup
Dataset and Task The models are evaluated on the Lean 4 version of the MiniF2F-Test and Validation datasets. MiniF2F contains 488 problems drawn from the MATH dataset, high-school mathematics competitions (AMC, AIME, IMO), and manually crafted problems. The task requires the LLM to generate complete Lean 4 proofs for these mathematical problems based on their Lean 4 statements, accompanied by natural language statements and proofs. A maximum of 16 in-context examples are used per query.
Implementation Details The OBT dataset was generated using Gemini-1.5-Pro-0409. Instruction fine-tuning on Llama3-Instruct-8B was performed using 1,000 warm-up steps and a learning rate of \(1\times 10^{-5}\). During evaluation, 128 uniform generations are performed per theorem. Iterative proof writing is stopped at the second round.
Baselines The method is compared against tree-search methods (Expert Iteration, ReProver) and un-finetuned few-shot LLMs (GPT-4-Turbo, Gemini-1.5-Pro, and Llama3-Instruct 8B).
Results
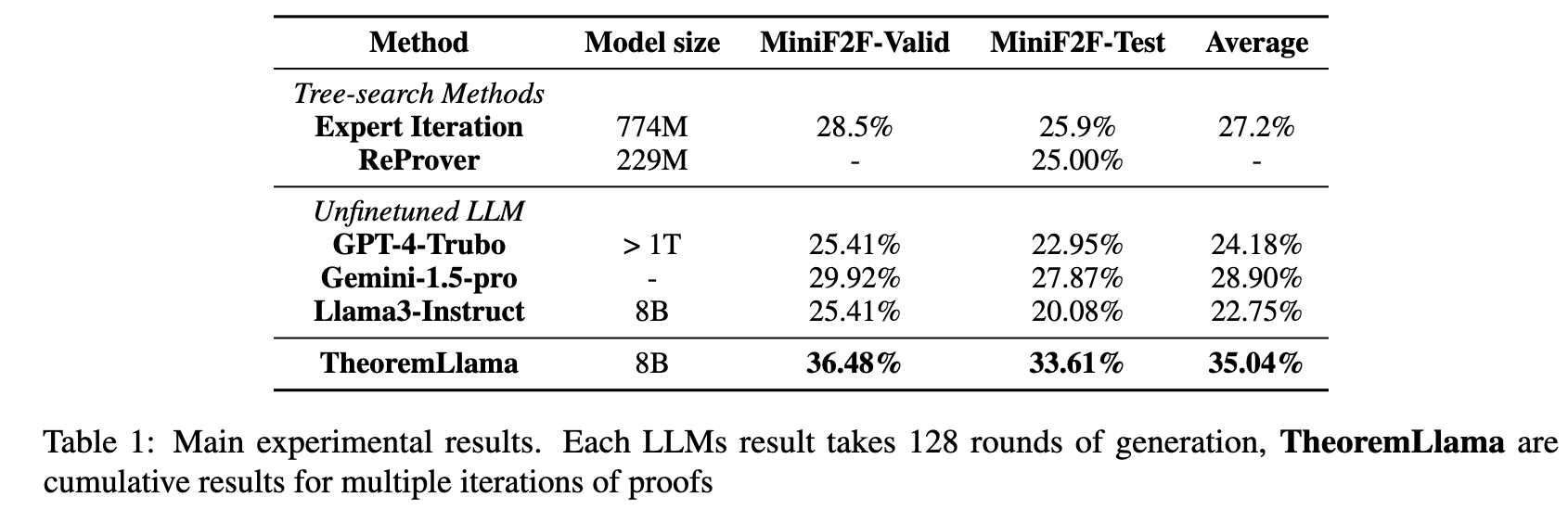
The proposed framework achieves cumulative accuracies of 36.48% on MiniF2F-Valid and 33.61% on MiniF2F-Test, outperforming the tested baselines. Among the un-finetuned LLM baselines, Gemini-1.5-Pro yields an accuracy of 29.92% on Valid and 27.87% on Test, while GPT-4-Turbo and Llama3-Instruct-8B show similar performance ranges around 20% to 25%.
Ablation Studies
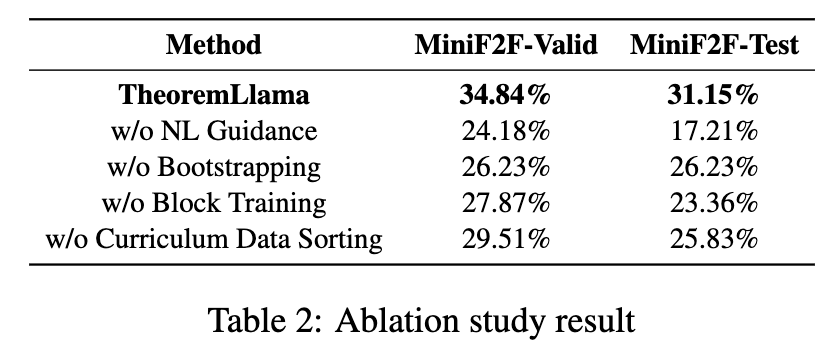
An ablation study evaluates the contribution of individual framework components on the MiniF2F-Valid and Test datasets using a single iteration configuration:
- w/o NL Guidance: Training without natural language data reduces accuracy to 24.18% (Valid) and 17.21% (Test).
- w/o Bootstrapping: Removing the NL-FL bootstrapped comments decreases accuracy to 26.23% (Valid) and 26.23% (Test).
- w/o Block Training: Removing block training drops performance to 27.87% (Valid) and 23.36% (Test).
- w/o Curriculum Data Sorting: Training without difficulty sorting results in 29.51% (Valid) and 25.83% (Test).
Effectiveness of Example Retrieval
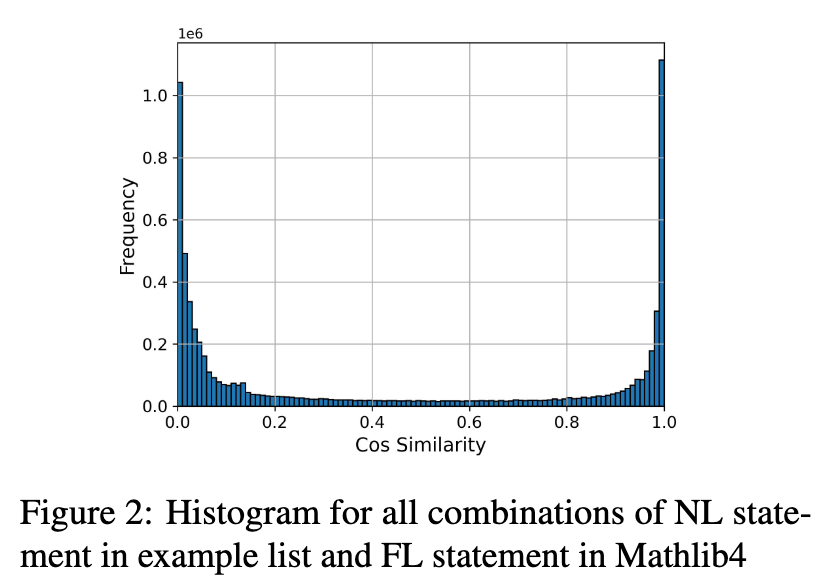
To evaluate the fine-tuned T5 model for example retrieval, cosine similarities were computed for all combinations between formal theorem statements in Mathlib4 and natural language statements in the example list. The resulting distribution exhibits distinct peaks at similarities of 1.0 and 0.0, indicating the model differentiates between matching and non-matching statement pairs.