Soft Tokens, Hard Truths
They add Gaussian noise to the soft-thinking embeddings, then train with RL using RLOO.
Read Paper →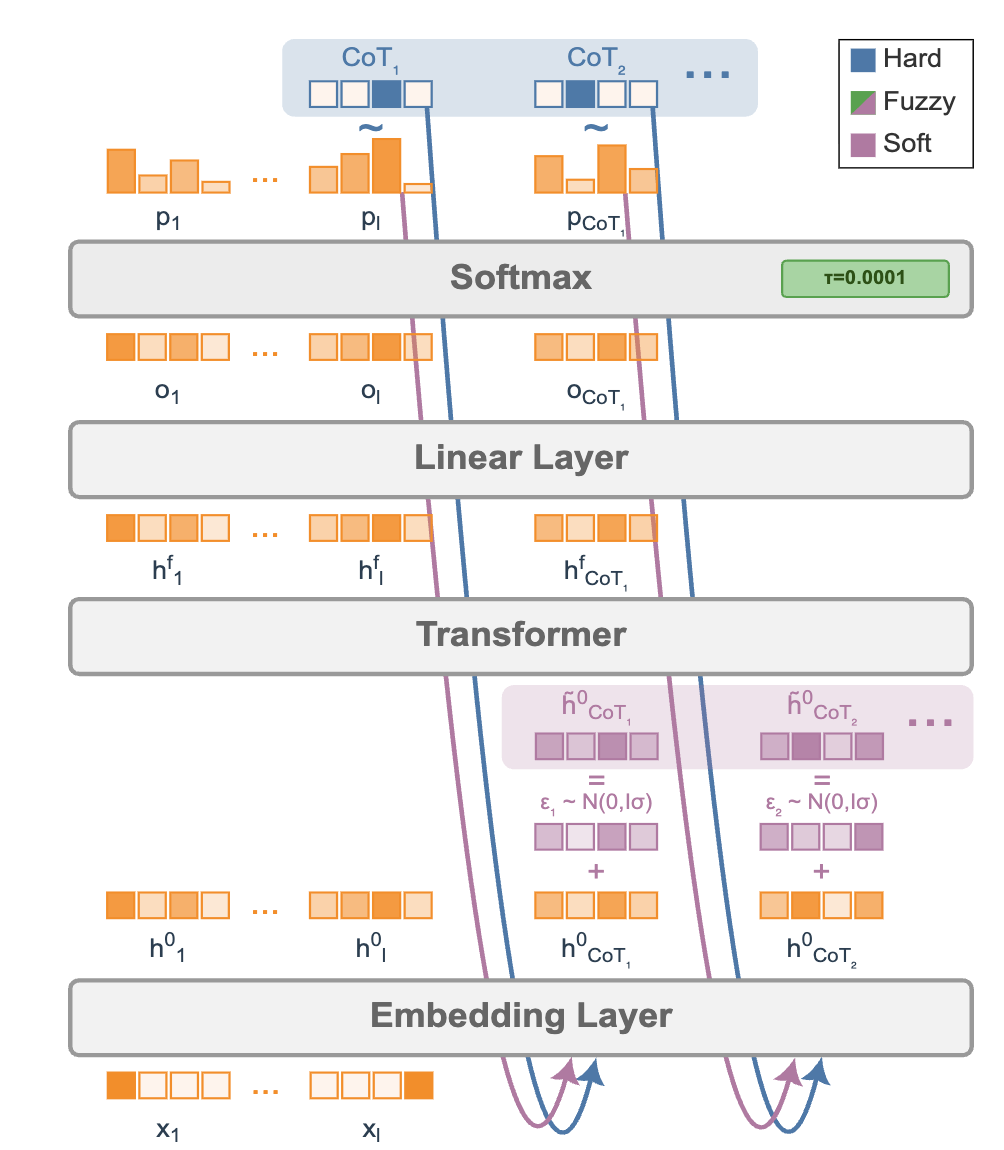
Training of continuous-token reasoning models has proven to be difficult, either due to computational constraints from full backpropagation through all steps of continuous reasoning (this limited the CoT to 6 steps in COCONAT), or due to the necessity of strongly grounding the continuous reasoning into ground-truth discrete reasoning traces (CODI)
The fuzzy tokens are just soft tokens with added Gaussian noise.
In soft thinking, if the probabilities of the next token (token \(t\)) are \(p_{t-1,i}\), then standard soft thinking computes \(h_t^0 = p_{t-1}E\), where \(E\) is the token embedding matrix.
In fuzzy thinking they have:
\[h_t^o = p_{t-1}E + \sigma N(0, I_D)\]RL (they didn’t use GRPO, they used RLOO)
The goal is to maximize
\[\mathbb{E}_{(\tilde{h}^o, a) \sim \pi}[R(a)]\]which is equivalent to maximizing
\[\mathbb{E}_{(h^o, a) \sim \pi^{\text{sg}}}[-R(a)(\log \pi({h}^o) + \log \pi(a\mid{h}^o))]\]For the first part, we can decompose over time and write:
\[\log \pi({h}^o) = \sum_t \log \pi({h}_t^o \mid {h}_{<t}^o)\]Calculating this is straightforward: we can compute the non-noisy version and then evaluate the probability using normal-distribution formulas.
For inference, they found that normal CoT works better even when trained with soft thinking. Soft-thinking training with normal inference even beats normal-training with normal inference.