Reinforcement Learning via Self-Distillation
Self-Distillation Policy Optimization (SDPO) leverages a model's in-context learning capabilities to convert tokenized environment feedback into dense, logit-level reinforcement learning signals.
Read Paper →Method
This work addresses Reinforcement Learning with Rich Feedback (RLRF), where the environment provides tokenized feedback \(f\) (such as runtime errors, compiler outputs, or judge evaluations) rather than just a scalar reward \(r\). The proposed method, Self-Distillation Policy Optimization (SDPO), utilizes the model’s own in-context learning capabilities to assign dense credit to generated trajectories.
The Self-Teacher
The core mechanism of SDPO is the self-teacher. Given a question \(x\), the policy \(\pi_\theta\) acts as the “student” to generate a response \(y\). Upon receiving feedback \(f\) from the environment, the same policy acts as the “teacher” when conditioned on the feedback: \(\pi_\theta(\cdot \mid x, f)\).
Because the teacher sees additional information (the feedback explaining why \(y\) might be incorrect or how it relates to the environment state), it effectively evaluates the student’s actions in hindsight. SDPO distills the teacher’s next-token distribution into the student’s policy.

Optimization Objective
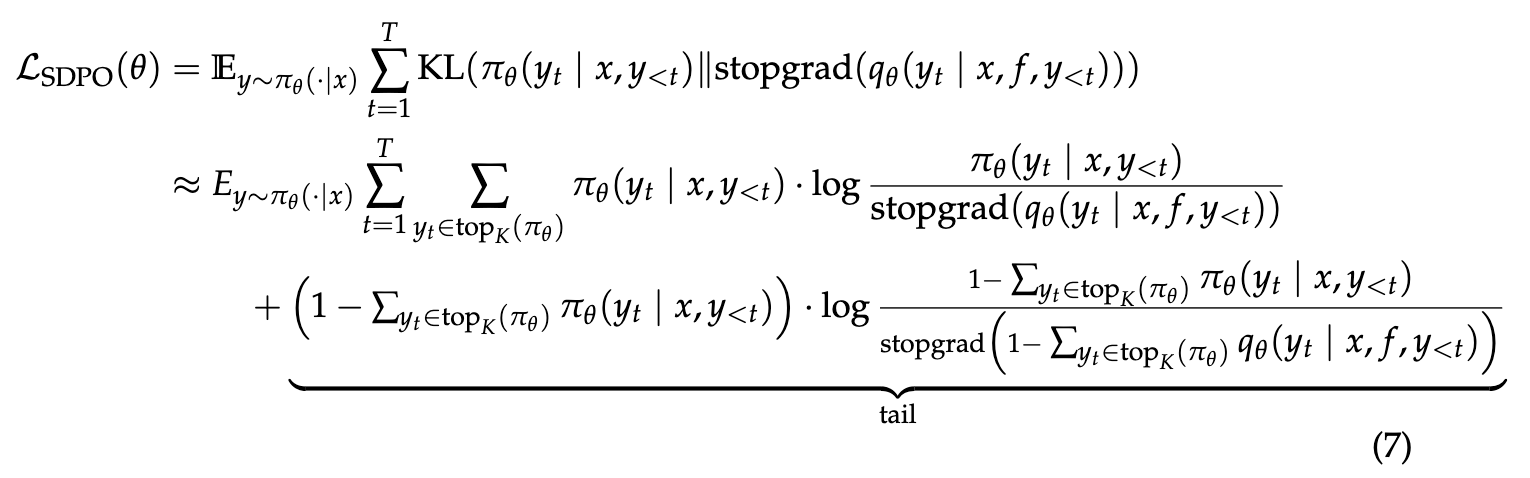
SDPO minimizes the Kullback-Leibler (KL) divergence between the student’s current policy and the self-teacher’s distribution. The loss function is defined as:
\[\mathcal{L}_{\text{SDPO}}(\theta) := \sum_t \text{KL}(\pi_\theta(\cdot | x, y_{<t}) \| \text{stopgrad}(\pi_\theta(\cdot \mid x, f, y_{<t})))\]The gradient of this objective takes the form of a policy gradient update:
\[\nabla_\theta \mathcal{L}_{\text{SDPO}}(\theta) = \mathbb{E}_{y \sim \pi_\theta(\cdot|x)} \left[ \sum_{t=1}^{|y|} \sum_{\hat{y}_t \in \mathcal{V}} \nabla_\theta \log \pi_\theta(\hat{y}_t | x, y_{<t}) \cdot \log \frac{\pi_\theta(\hat{y}_t | x, y_{<t})}{\pi_\theta(\hat{y}_t | x, f, y_{<t})} \right]\]Comparison to GRPO
SDPO advantages can be compared to Group Relative Policy Optimization (GRPO). While GRPO assigns a constant advantage to an entire trajectory based on a scalar outcome reward, SDPO computes a dense, token-level advantage:
\[A^{\text{SDPO}}_{i,t}(\hat{y}_{i,t}) = \log \frac{\pi_\theta(\hat{y}_{i,t} | x, f_i, y_{i,<t})}{\pi_\theta(\hat{y}_{i,t} | x, y_{i,<t})}\]This advantage is positive when the teacher assigns higher probability to a token than the student, and negative otherwise. This allows the model to identify specific tokens that contributed to errors identified by the feedback.
Implementation Details
To stabilize training and manage computational costs, SDPO employs two specific techniques:
- Regularized Self-Teacher: The teacher is not fixed but updates throughout training. To prevent instability, the teacher’s parameters are maintained as an Exponential Moving Average (EMA) of the student’s parameters, or constrained within a trust region of the initial policy.
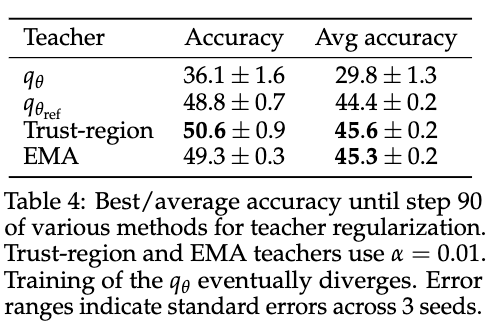
Trust region works like this:
\[q^*(y_t \mid x, f, y_{<t}) \propto \exp \left( (1 - \alpha) \log q_{\theta_{\text{ref}}}(y_t \mid x, f, y_{<t}) + \alpha \log q_\theta (y_t \mid x, f, y_{<t}) \right).\]EMA works like this: \(\theta'_k = (1 - \alpha)\theta'_{k-1} + \alpha\theta_k, \quad \alpha \in (0, 1).\) They used EMA by default.
- Top-K Distillation: To reduce memory overhead, the method does not store or compute gradients for the full vocabulary (which can be very large). Instead, it splits the distribution into two parts Top-K Tokens and The Tail Term (sum of probabilities for all remaining tokens).
Experiments
The method is evaluated in three distinct settings: standard verifiable rewards (no rich feedback), coding tasks with rich feedback, and test-time optimization.
Learning without Rich Feedback
In standard RLVR environments like Science Q&A and Tool Use, the environment only returns a scalar reward (success/failure). SDPO adapts to this by treating successful attempts within a rollout group as the “feedback” \(f\) for failed attempts.
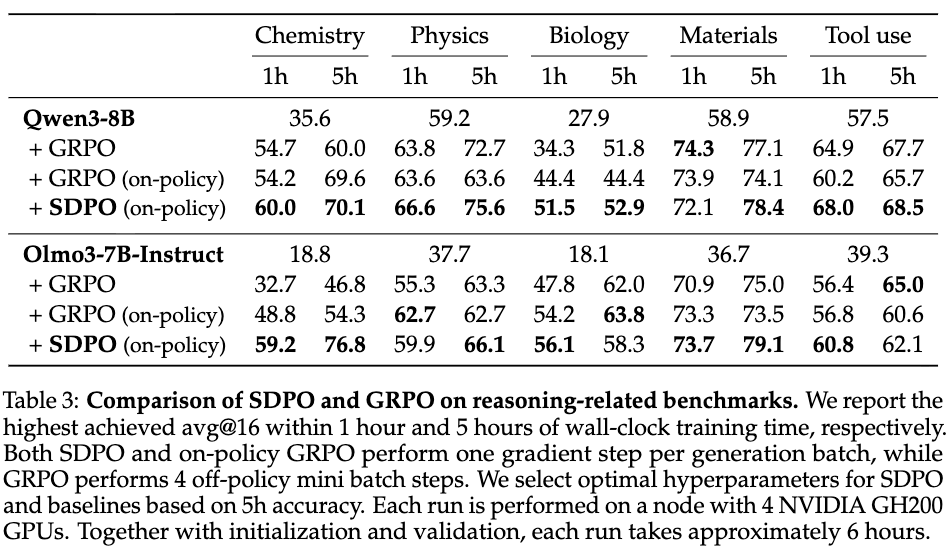
- Performance: On average, SDPO outperforms GRPO (68.8% vs. 64.1% final accuracy).
- Efficiency: SDPO tends to produce significantly shorter generations than GRPO (up to \(7\times\) shorter on specific tasks) while maintaining or improving accuracy. This contrasts with GRPO, which often learns to generate verbose “filler” text to improve reasoning reliability.
Learning with Rich Feedback
This setting evaluates SDPO on LiveCodeBench v6 (LCBv6), where the environment provides public unit test results and runtime error messages.
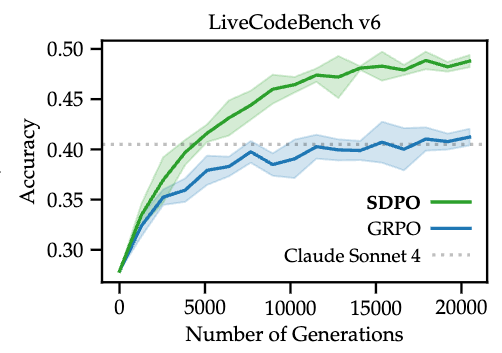
- Accuracy: SDPO achieves a final pass@1 accuracy of 48.8% compared to GRPO’s 41.2%.
- Convergence: SDPO reaches GRPO’s final accuracy in approximately \(4\times\) fewer generations.
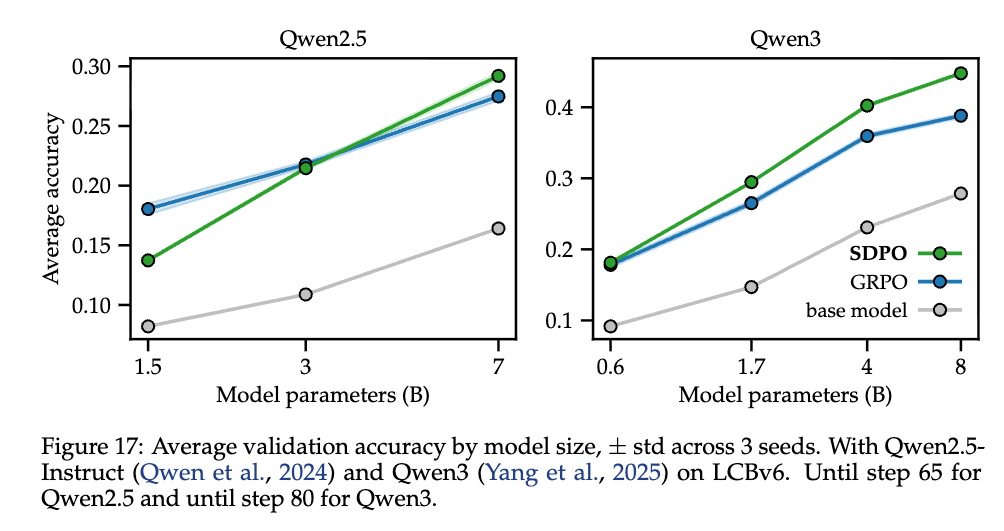
- Model Scaling: Improvements are correlated with model size. SDPO shows marginal gains on Qwen2.5-1.5B but substantial gains on Qwen3-8B, suggesting that the self-teacher’s effectiveness depends on the emergence of strong in-context learning capabilities in larger models.
Test-Time Self-Distillation
SDPO is applied at test-time to solve difficult binary-reward problems where the base model has a near-zero pass rate. The model iteratively updates its weights on a single question using the feedback generated from its own attempts.
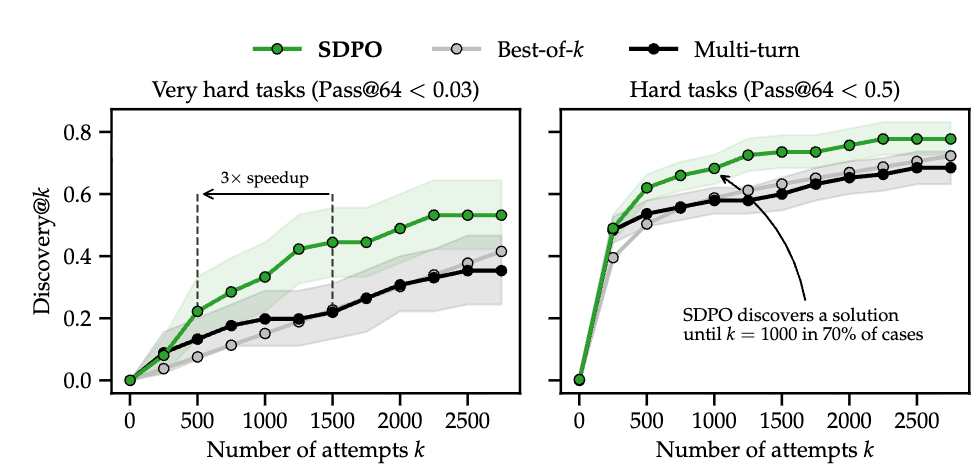
- Discovery Time: On “very hard” tasks (pass@64 < 0.03), SDPO accelerates the discovery of a correct solution by \(3\times\) compared to best-of-\(k\) sampling and multi-turn conversational baselines.
- Context Compression: Unlike multi-turn prompting, which is limited by context window size, SDPO compresses the interaction history into the model weights, allowing it to “remember” failures and corrections over longer horizons (tested up to 2750 attempts).
SDPO works better for larger models
Since SDPO depend on the model in-context learning it works better for stronger models.
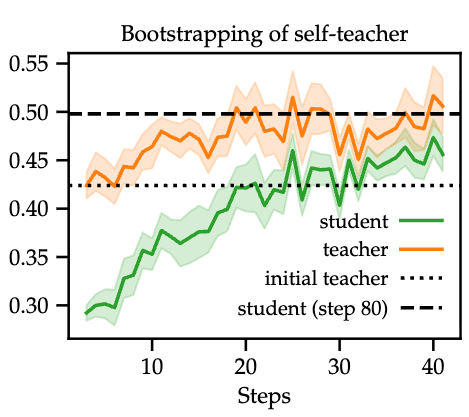
Teacher improves during training
Given the question, hint how likely is it that the teacher generates a correct answer? it increases during training so teacher is becoming better.
Which feedback is most informative?
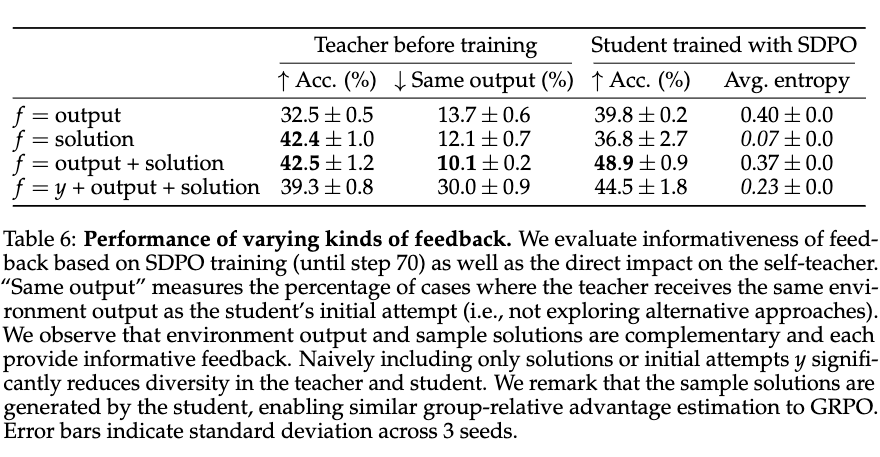
- Do not include the student output in the hint.
- Having the solution and the error (output) is the best combination.