Reasoning Within the Mind Dynamic Multimodal Interleaving in Latent Space
Training-free latent reasoning. Optimize latent reasoning tokens to maximize model confidence, which correlates with accuracy.
Read Paper →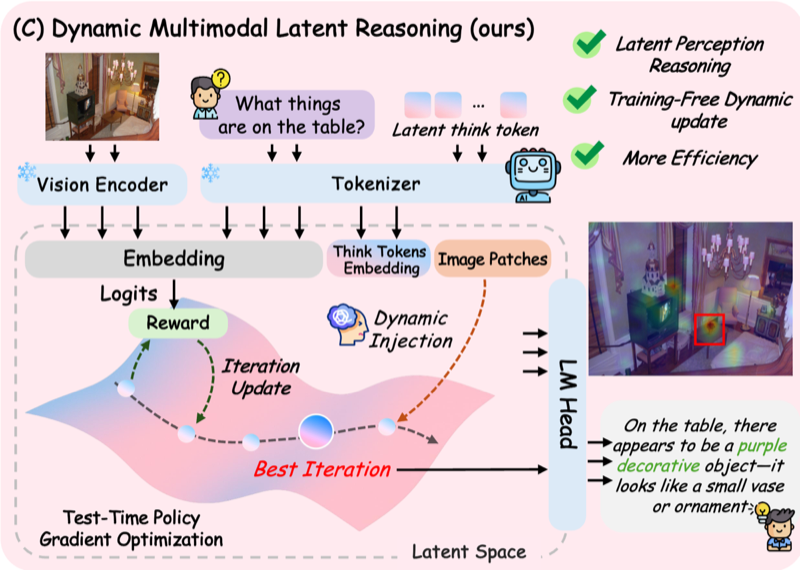
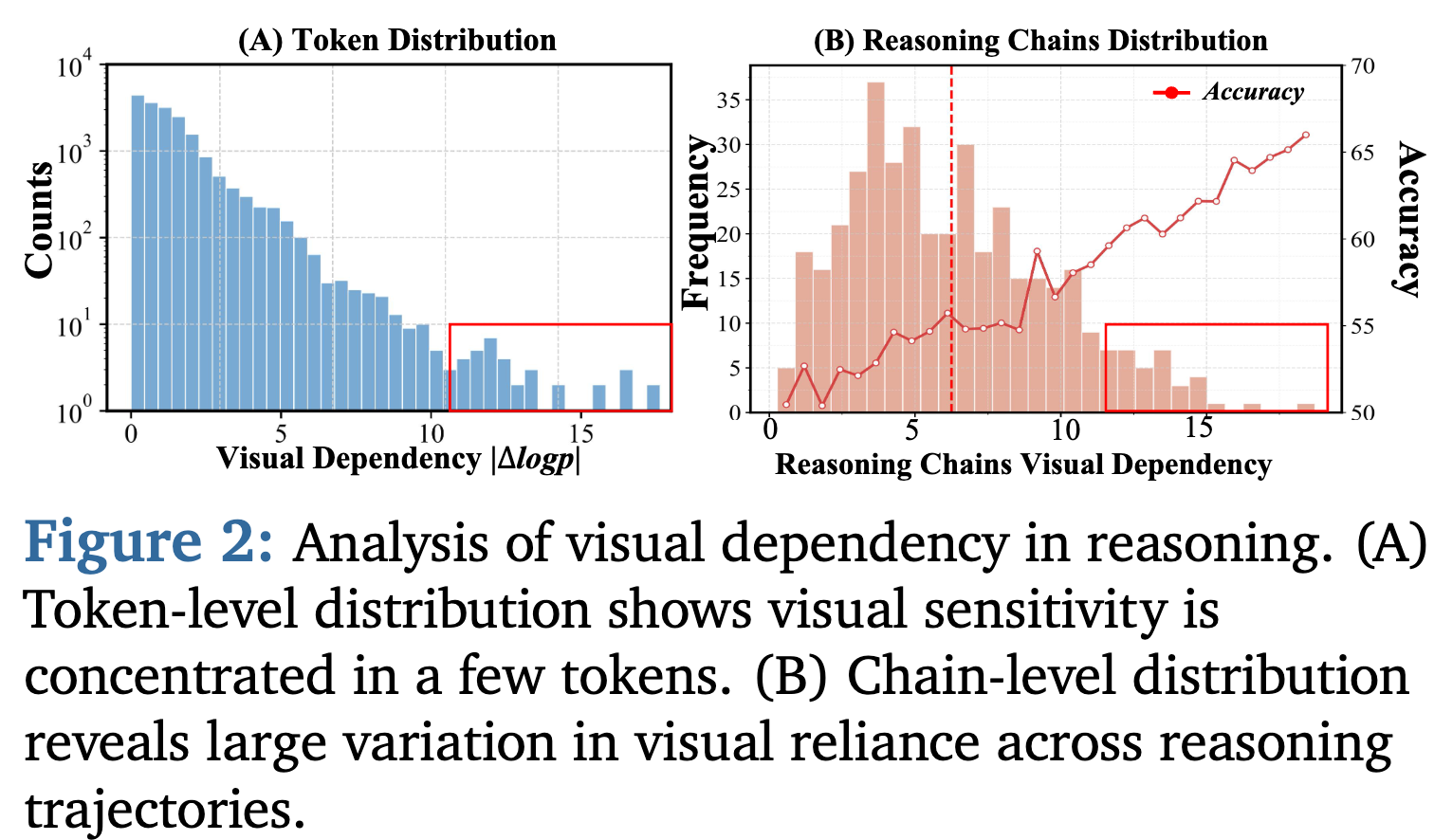
To measure whether a token depends on the image, they add noise to the image and measure whether the probability of that token drops.
\[S_{i,t} = \log \pi_{\theta}(x_{i,t} \mid x_{i,<t}, I, q) - \log \pi_{\theta}(x_{i,t} \mid x_{i,<t}, \tilde{I}, q)\]They show that:
1) Only a small subset of tokens really depends on the image.
2) Reasoning sequences that depend more on the image have higher accuracy.
They make these additional observations:
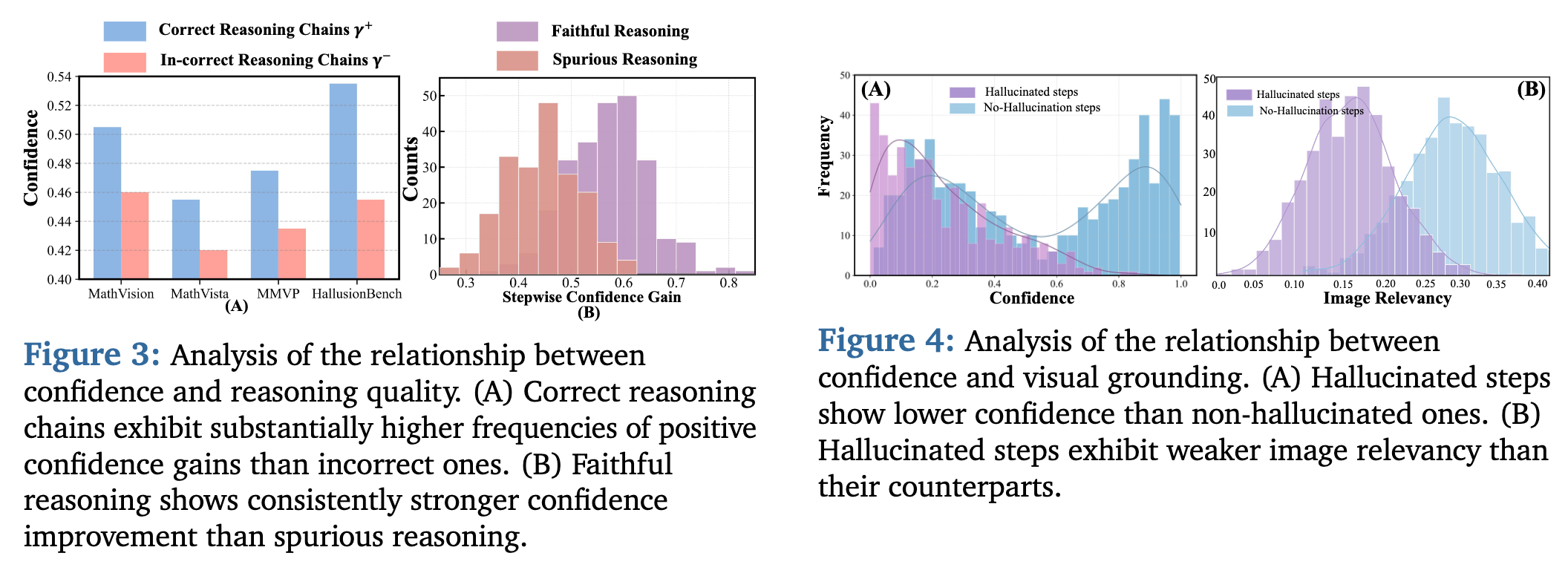
1) Higher confidence tends to indicate higher reasoning accuracy.
2) Confidence reflects reasoning chain quality.
3) High confidence aligns with stronger visual grounding.
Method
Their method is training-free, but at inference time they run an optimization that might be heavy. They add \(L\) latent tokens to the start of generation and update their embeddings to improve performance. So the input sequence becomes:
\[[\text{Image embeddings}, \text{question embeddings}, V_{best}, L_1,L_2,\cdots, L_L]\]The embeddings of the \(L\) latent tokens are learned in such a way that the model’s confidence is maximized. So they optimize the \(L_i\) embeddings to maximize model confidence. They measure model confidence using:
\[H_k(P_i^{(t)}) = - \sum_{w \in \text{Top}_k(P_i^{(t)})} P_i^{(t)}(w) \log(P_i^{(t)}(w))\] \[R(T^{(t)}) = 1 - \frac{1}{L} \sum_{i=1}^{L} H_k(P_i^{(t)})\]So the more confident the model, the better. They do the latent optimization and image patch selection \(T\) times, then decode using both.
Optimization of latent embeddings
They use a REINFORCE-based optimization.
\[T^{(t)} \leftarrow T^{(t)} + \eta \nabla_{T^{(t)}} J(T^{(t)})\]where:
\[\nabla_T J(T) = \mathbb{E}_{T' \sim \pi(\cdot\lvert T)} [R(T') \nabla_T \log \pi(T' \rvert T)] = \mathbb{E}[R(T') \frac{\epsilon}{\sigma^2}]\]and
\[T'^{(t)} = T^{(t)} + \epsilon^{(t)}, \quad \epsilon^{(t)} \sim \mathcal{N}(0, \sigma^2 I)\]Optimization of \(V_{best}\)
They move over latent tokens one by one. For each latent token, they find the top \(m\) visual tokens it attends to (based on the attention pattern). They add those to \(V_{best}\) and check whether the reward increases. If it does, they update \(V_{best}\); otherwise they don’t.
