ProofBridge Auto-Formalization of Natural Language Proofs in Lean via Joint Embeddings
ProofBridge is a framework that auto-formalizes natural language proofs into Lean 4 using cross-modal retrieval via joint embeddings, retrieval-augmented fine-tuning, and iterative verifier-guided repair.
Read Paper →Evaluation method
1. Formulating the Problem They translate the equivalence check into a formal Lean task by constructing a logical biconditional statement: \(eTFL \leftrightarrow TFL\). To prove the theorems are semantically equivalent, they must prove this biconditional is true.
2. LLM as a Proof Synthesizer They prompt an LLM (Gemini-2.5-Pro) up to five times to generate a formal Lean proof for this biconditional statement.
3. Bounding the Proof (Restricted Tactics) To ensure the LLM is proving direct equivalence and not making massive, unbounded logical leaps, they restrict the LLM to a specific, limited set of Lean tactics:
-
rfl: Checks for direct definitional equality. -
simp(without arguments): Performs safe, trivial rewrites using Lean’s default simplification lemmas. -
ring: Resolves polynomial and algebraic identities (e.g., proving \(x^2\) is the same as \(x * x\)). -
constructor,intro,nlinarith: Allowed specifically to handle cases where human experts and models might differ in how they structure a proof (e.g., one uses an auxiliary variable like \(v\) for volume, while the other directly embeds the formula).
Method
The goal is to learn a mapping from a natural language (NL) theorem and proof pair \(M_{NL} = \langle T_{NL}, P_{NL} \rangle\) to a corresponding formal language (FL) Lean theorem and proof pair \(M_{FL} = \langle T_{FL}, P_{FL} \rangle\). The method relies on three components: a joint embedding model for cross-modal retrieval, retrieval-augmented fine-tuning, and an iterative proof repair mechanism.
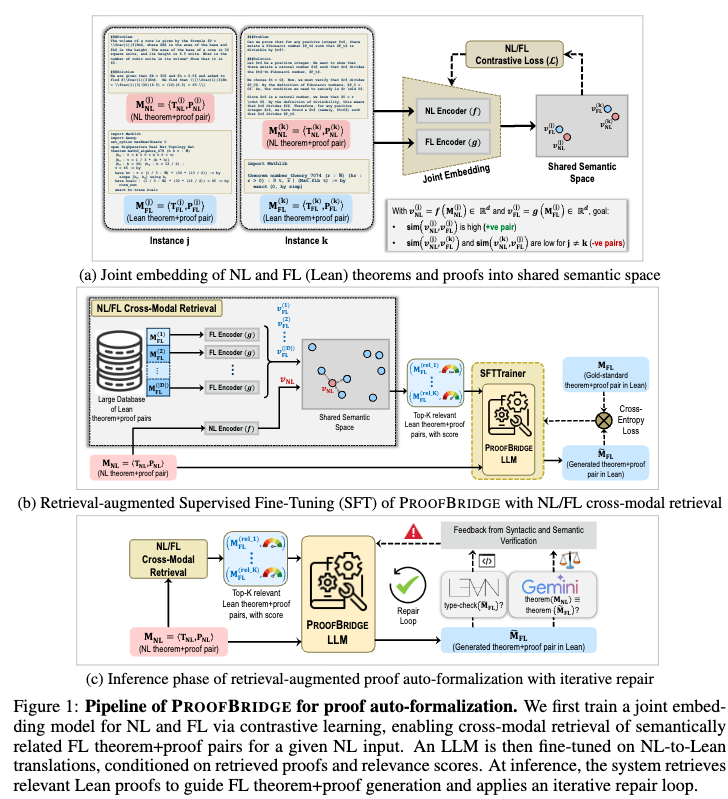
Joint Embedding of NL and Lean Proofs
The joint embedding model represents NL and FL counterparts in a shared semantic space to enable cross-modal retrieval. Given a database \(\mathcal{D} = \{M_{FL}^{(i)}\}_{i=1}^N\), the model retrieves a subset \(\mathcal{R}(M_{NL}, \mathcal{D})\) of size \(K\) to serve as in-context demonstrations for the downstream generation.
The models use modality-specific encoders to map inputs to vectors of dimension \(d=512\):
- NL Encoder: Uses a pre-trained sentence transformer to map \(M_{NL}^{(i)}\) to a vector \(v_{NL}^{(i)} = f(M_{NL}^{(i)}, \theta_f \parallel \phi_f) \in \mathbb{R}^d\).
- FL Encoder: Extracts a linearized directed acyclic graph (DAG) traversal of proof states and tactics from \(P_{FL}^{(i)}\). This sequence of state transformations is encoded and mean-pooled to produce \(v_{FL}^{(i)} = g(M_{FL}^{(i)}, \theta_g \parallel \phi_g) \in \mathbb{R}^d\). This approach encodes structural similarities between proof DAGs.
The encoders are optimized using a symmetric contrastive loss over a mini-batch \(\mathcal{B}\) of size \(n\):
\[\mathcal{L}(\mathcal{B}) = -\frac{1}{2n} \sum_{i=1}^{n} \left[ \log \left( \frac{\exp([\widehat{v}_{NL}^{(i)}, \widehat{v}_{FL}^{(i)}]/\tau)}{\sum_{j=1}^{n} \exp([\widehat{v}_{NL}^{(i)}, \widehat{v}_{FL}^{(j)}]/\tau)} \right) + \log \left( \frac{\exp([\widehat{v}_{FL}^{(i)}, \widehat{v}_{NL}^{(i)}]/\tau)}{\sum_{j=1}^{n} \exp([\widehat{v}_{FL}^{(i)}, \widehat{v}_{NL}^{(j)}]/\tau)} \right) \right]\]where \([\cdot, \cdot]\) denotes cosine similarity, \(\widehat{v}\) indicates \(\ell_2\)-normalized embeddings, and \(\tau\) is a temperature hyperparameter.
Retrieval-Augmented Fine-Tuning
A language model is fine-tuned to translate \(M_{NL}\) to \(M_{FL}\), conditioned on the top-\(K\) retrieved FL demonstrations \(\mathcal{R}(M_{NL}, \mathcal{D}) = \{M_{FL}^{(k)}\}_{k=1}^K\) and their corresponding relevance scores. The model is trained via supervised learning using the standard auto-regressive cross-entropy loss:
\[\mathcal{L}_{CE} = -\frac{1}{|\mathcal{T}|} \sum_{t=1}^{|\mathcal{T}|} \log P_{\theta} (\tau_t \mid \tau_{<t}, \mathcal{C})\]where \(\mathcal{T}\) represents the tokenized generated formalization and \(\mathcal{C}\) is the input context containing both the NL input and the retrieved FL examples.
Iterative Proof Repair
During inference, the generated FL output \(\widetilde{M}_{FL} = \langle \widetilde{T}_{FL}, \widetilde{P}_{FL} \rangle\) undergoes a bounded repair loop (maximum \(R_{max} = 5\) attempts) using two feedback mechanisms:
- Syntactic Verification: \(\widetilde{M}_{FL}\) is compiled using the Lean type checker. Error messages and locations are extracted upon failure.
- Semantic Verification: An LLM-based equivalence judge attempts to construct a Lean proof of the logical biconditional \(\widetilde{T}_{FL} \leftrightarrow T_{NL}\) using a restricted set of tactics (e.g.,
rfl,simp,ring) to ensure definitional and bounded propositional equality.
Experiments
Experimental Setup
- Datasets: The joint embedding model and the generation LLM are trained on NUMINAMATH-LEAN-PF, which consists of 38.9k NL-to-Lean 4 theorem and proof pairs. Evaluation is conducted on MINIF2F-TEST-PF, an updated Lean v4.15.0 benchmark with 244 test instances.
- Evaluation Metrics:
- Retrieval: Recall Rate @ \(K\), Mean Reciprocal Rank (MRR), and cosine similarity properties.
- Auto-Formalization: Type Correctness (TC) measures if the proof compiles without
sorry. Semantic Correctness (SC) measures if the generated theorem is verifiable as bi-directionally equivalent to the target theorem. Metrics are reported atpass@kfor \(k \in \{1, 2, 4, 8, 16, 32\}\).
NL/FL Cross-Modal Retrieval Performance
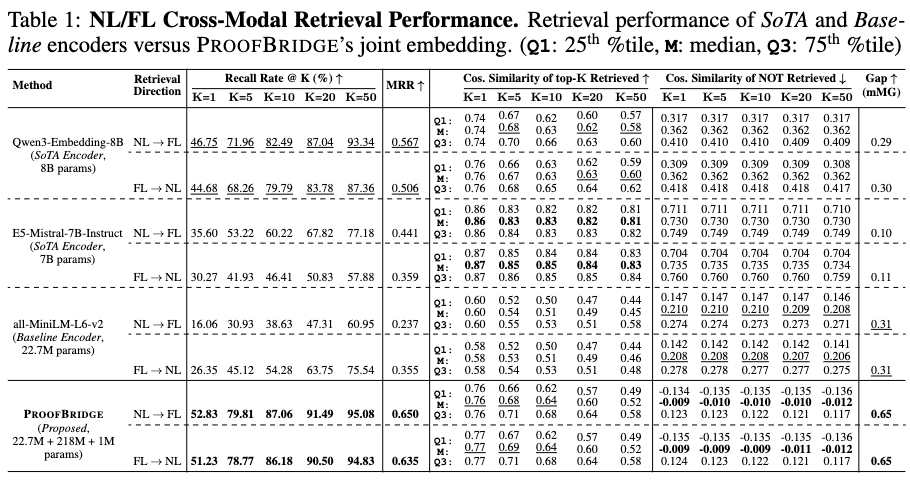
The joint embedding approach is compared against plain-text embedding encoders (Qwen3-Embedding-8B, E5-Mistral-7B-Instruct, all-MiniLM-L6-v2). Relying on the DAG structure of FL proofs instead of plain text, the method records a Recall@1 of 52.83% for NL \(\rightarrow\) FL and 51.23% for FL \(\rightarrow\) NL. For NL \(\rightarrow\) FL, this represents a 3.28\(\times\) improvement in Recall@1 and a 2.74\(\times\) increase in MRR compared to the baseline sentence transformer.
Proof Auto-Formalization Performance
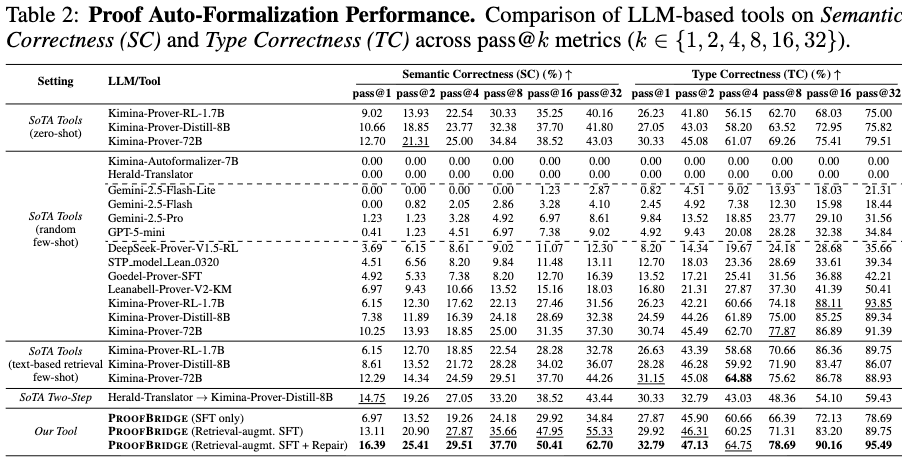
Evaluations include comparisons against 13 language models across foundation models and automated proof synthesis models. In a zero-shot setting, the baseline Kimina-Prover-RL-1.7B achieves 40.16% SC and 75.00% TC at pass@32. The full framework utilizing retrieval-augmented fine-tuning and iterative repair achieves 62.70% SC and 95.49% TC, improving on the baseline by +22.54% SC and +20.49% TC respectively.
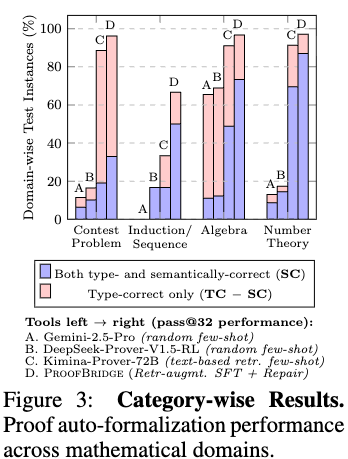
An ablation across mathematical domains demonstrates that the system records the highest semantic correctness on number theory problems (>85% SC). Contest problems from sources like AIME and IMO observe a lower performance threshold (~35% SC). Furthermore, comparisons indicate that substituting the DAG-aware joint embeddings with text-based retrieval (Qwen3-Embedding-8B) reduces SC from 40.16% to 32.38%, pointing to semantic misalignment when retrieving on superficial keyword overlap rather than structural proof properties.