Physics of Language Models
Understanding LLMs by training smaller LMs in controlled environment
Read Paper →Part 1
They trained a model on a synthetic grammar.
like
S -> AB
S -> BA
A -> 12
B -> 31
This is an actual example:

They trained an LM on this and showed the model has good accuracy/diversity/everything. Then they showed that when the model is probed, it has the knowledge of related dp states that we use to calculate and see if the string belongs to that language. By DP states, I mean the state that we are in the middle of which upper layer variable. It also stores if the upper layer variable is finished.
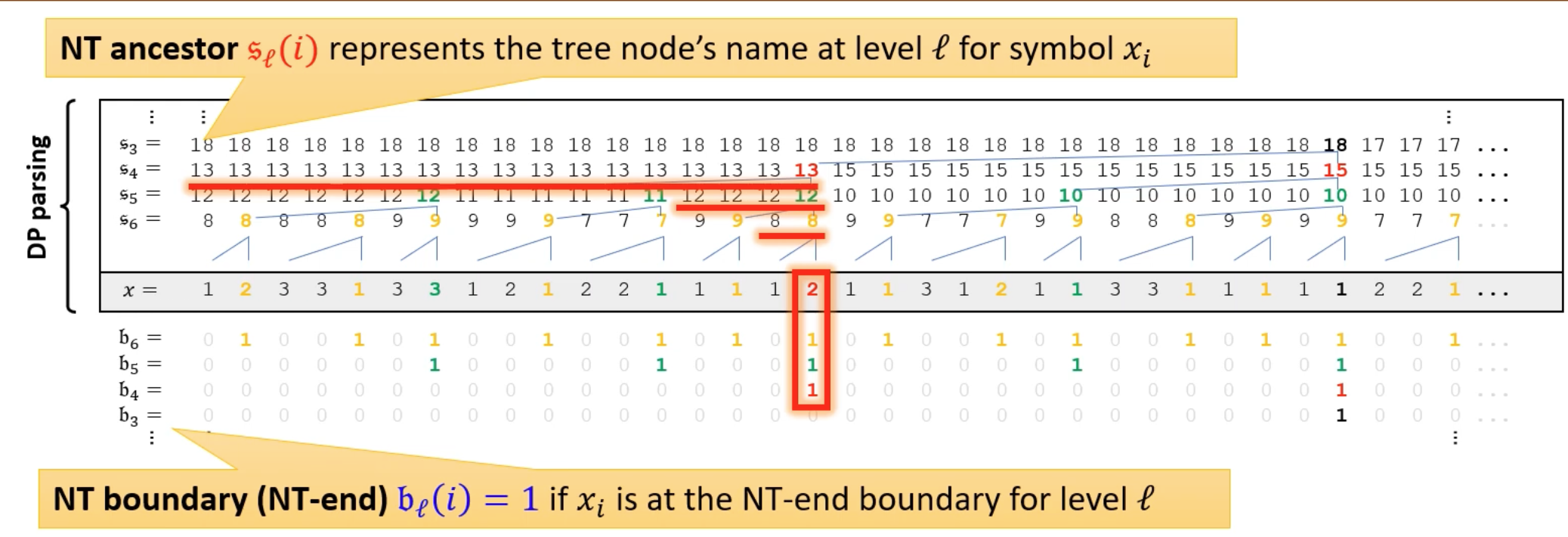
They also show that the model looks at those previous tokens that are really matter for updating these states. So it really updates its DP states properly.
Corrupted data: if you want to test your model with corrupted data, you should obviously add corrupted data to its training dataset. They showed this work but with a catch. The model learns that the training data has two mode: correct and corrupt. It your inference data is too much corrupt it continues to complete it with corrupt data.
Part 2.1
- We need to train smaller LMs to understand them because if we didn’t train an LM, we are not sure about the training data, and we can even be sure that the abilities we see are memorization or generalization.
- They build iGSM that is a synthetic GSM8K-like dataset. It has a few fixed objects that have some fixed relationships together.

- They trained a GPT-2 model which learned the data (For an example, look at the image in Part 2.2)
- They defined the level of reasoning skills
- level-0: Go in circles and check if you can calculate a variable and if you can, calculate it.
- level-1: uses topological sort + gives shortest CoT.
- they showed GPT does level-1 reasoning -> it never computes unnecessary variables.
- How does the model know what variables are important before start answering? Using probing, they showed these:
- the model knows what variables are required for answering the question, (right after the question finishes)
- In the solution, it knows what variables can be computed next (their dependencies are calculated already)
- Before the question, the model knows whether variable A depends on variable B, for all A and B.
- Unlike humans, it doesn’t track back from the question. It keeps its knowledge updated after each new sentence.
- They showed that Depth matters for reasoning: The accuracy depends on dept more that on its width.
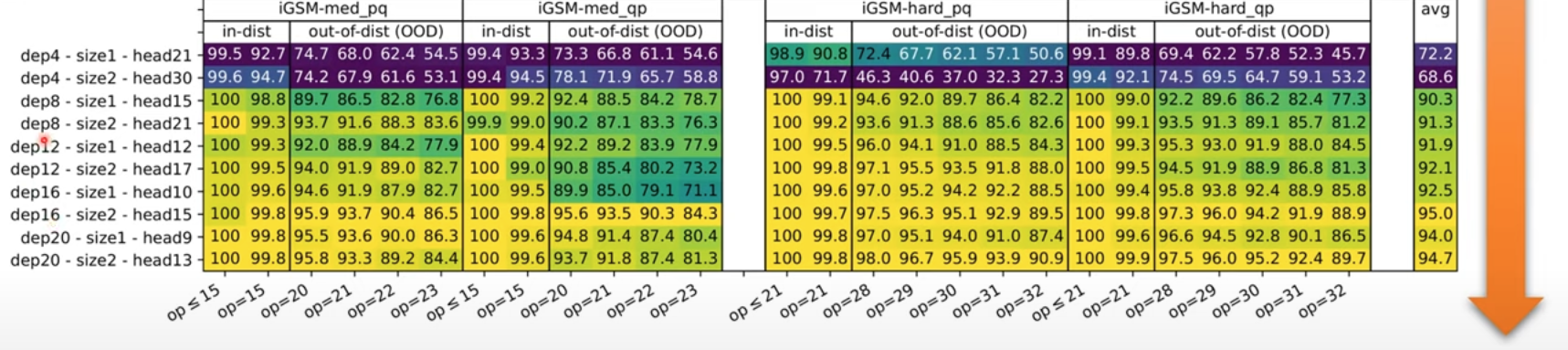
- Only Deeper layers can be probed so that we get a high accuracy on “whether variable A is necessary for computing the answer.”
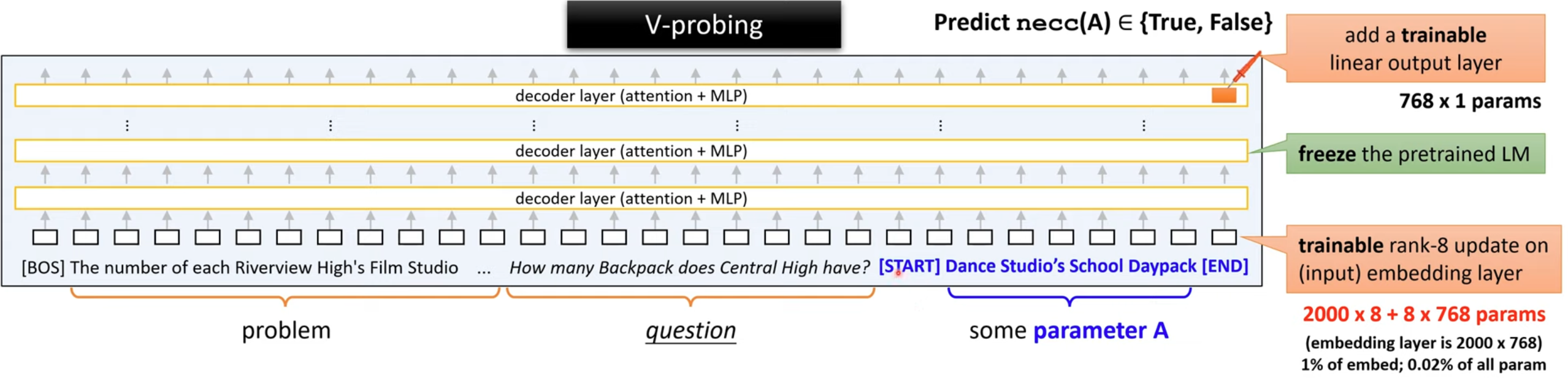
How they probed?
When they wanted to know what knowledge the model has about a variable, they attached that variable name to the end of the sentence like the following image and then probed at that point. They trained a rank-8 update on input embedding and a trainable linear layer on the output embedding.
Part 2.2
LLMs are not perfect in reasoning. Sometimes by just saying that they made a mistake somewhere, they can correct themselves. They tried to improve their LLM reasoning model. Using the iGSM, they found out that in that dataset the main reason an LLM returned the wrong answer was that the model tries to compute a variable that is not ready for computation.

- The model sometimes knows it made a mistake 50%-70% of the time.
- Error detection is easy. You can train a model on error-free data, and it already knows when some data is wrong.
- You can improve reasoning using this, when the model regrets and knows it made a mistake role back and generate that step again. From 78% -> 80%. Note that beam search doesn’t improve reasoning.
But it is better if the model corrects itself. To investigate this, they wanted a dataset that solutions sometimes have error, but it corrects itself later. This is an example of this dataset.

- Doesn’t this encourage model to make mistake? Shouldn’t we mask the labels of mistake? so that the model doesn’t learn the mistake but only to correct it mistake? Answer: even with p=0.5 the accuracy of the model increases.
- When p increases, the model doesn’t make more mistakes that much (it actually makes more mistakes by a little bit.) with temp=0.
- LoRA on error-free models with the new dataset with error doesn’t help.
- Full fine-tuning works if you use lots of data.
- So Error correction is harder than Error detection.
data with error generation
The method that works is that you move a later step of reasoning back, and the model midway of this reasoning step should understand that it is not yet ready for this step and output the [BACK] token. This encourages that model to not skip reasoning steps.
Beam search
Beam search is not that good. beam search with 32 tokens increases accuracy from 78% to 79%.
Part 3
Intelligence has many levels like grammar → in-context learning → memory → manipulate knowledge → math/logic reasoning’s → world models.
The working example:
[User] Was Barack Obama born in an even day?
[GPT-4o] No. Barack Obama born on August 4, 1961. So yes Obama was born on an even day.
The question is that why this happened? The problem can arise from two places. 1) the model can’t extract the birth year (Part 3.1) 2) Model knows the birth year but can’t reason (Part 3.2) 1) Model doesn’t know what Even means 2) Model knows 1961 is odd but can’t answer 3) Even if the model correctly answers the question, we might have two cases: (the model memorizes this question, or the model reasons its way to the correct answer).
Part 3.1
In Part 3.1 they investigate memory storage and extraction.
They generated two datasets 1) bioS dataset is a set of synthetic random biographies each with a random name, degree, birth info, work and working place in a story like template 2) bioR dataset they rewrited bioS dataset with Llama to seem more diverse.
Using their datasets they generated some QA questions (6 per biography) like what is the birth year, what is the work place etc. they divided this into two equal sets randomly (all questions related to one person goes to one group)
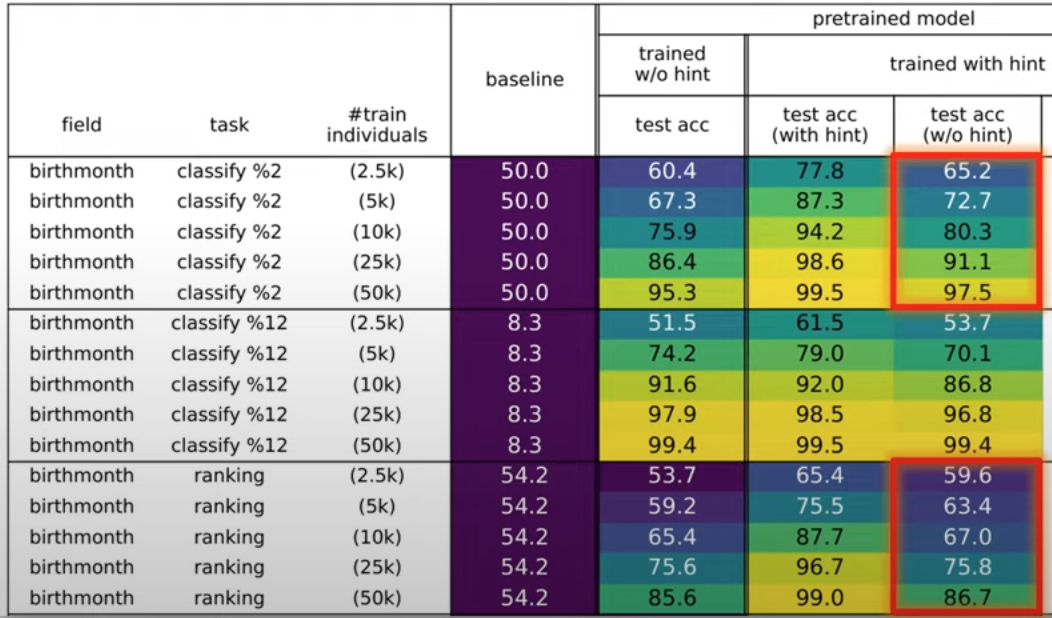
So they have bioS_in bioS_out QA_in QA_out. They trained their model with the first three groups (mixed training) and said that the accuracy increases like this:
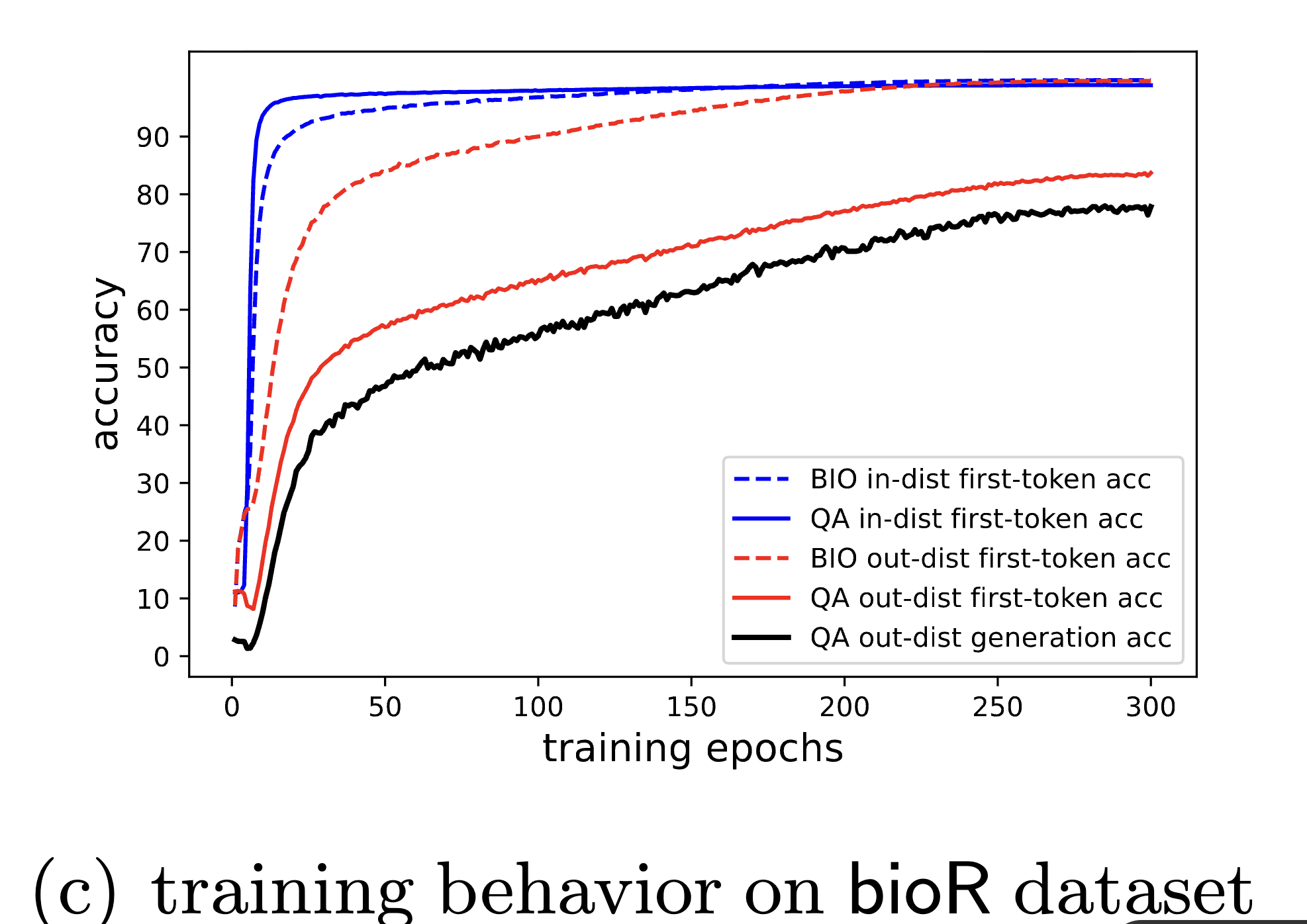
They see that questions really helped the model memories biographies. They claimed it is very odd (people read biograohies to remember questions not the other way around), but the questions are cleaner data (only name → brith year) and it is natural that helped a lot.
First using biographies and then using the QA performed terribly. Both LoRA and full-tuning. They added augmentations that made bioraphies more similar to QA data and it helped the QA performance, no joke!
They probed the model last layer right before the knowledge (born on October 2, 1996. .. worked in Google. ) The question is that can probing on on result in predicting Google?
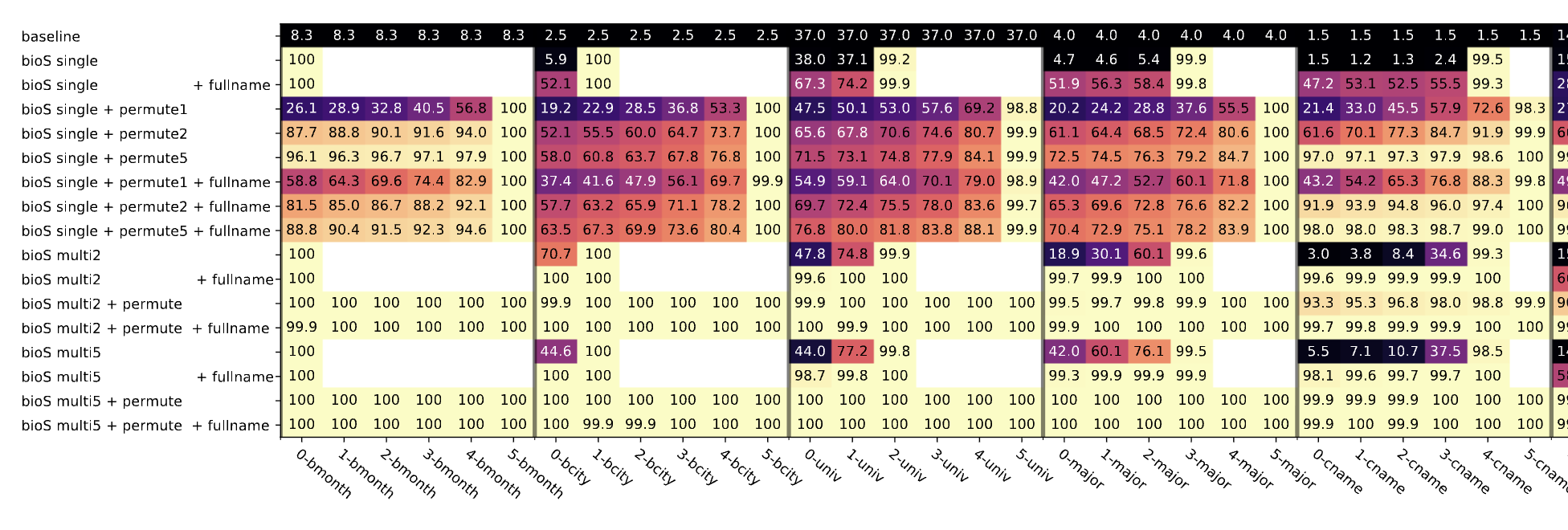
P-Probing: They showed that if they augment data the model will fetch all data. This makes total sense, if you make the data like Name do this, Name do that, Name …, after putting the Name the model learns to fetch all data. Q-Probing: they only feed the persons name and prob the last token hidden state. Again makes total sense.
Interesting finding: They augment few people biographies a lot (they call them celebrities) they helped the model to better perform everyone not just celebrities. Why? Not sure but the model learns to fetch all data early on (P-Probing experiment).
Part 3.2
In this part they investigate knowledge manipulation
They trained the model like the previous part, but they tested the model like this:
partial retrieval
What is the birth day in the month for Anya Briar Forger? [answer] 2
What is the birth year for Anya Briar Forger? [answer] 1996
Dual retrieval
1. Where was Anya Briar Forger born and which company did this person work for? [answer] Princeon, NJ; Meta.
...
They saw that although the model’s performance on name → birthdate is 100% its performance on birth year is terrible.
They saw that dual-retrieval performance is good except on name → (company city, then, company name). Obviously company city is a function of company name, and then obviously performance is higher on person name → (company name, then, company location). They used this evidence and said CoT is good!
They generated a dataset for knowledge manupilation like
Manipulation
Is obama birth year odd? [answer] No
They finetuned model normally on this dataset. In addition they trained model with CoT like the samples are like
Is obama birth year odd? [answer], 1961 No
The result is interesting, if the model trained with CoT but in inference can’t do CoT the performance is better compared to without CoT training but very worse than CoT in inference.
Inverse knowledge search: they asked model who was born on October 2, 1996? or provide more knowledge. For training they first pretrained model on all biographies and then fined tuned model on inverse knowledge search for some people. They couldn’t do knowledge inverse search at all. They tested this in GPT-4. They asked GPT the sentence after a sentence in a famous book and sentence before a sentence in a famous book, and the performance was veryyy different. Like 70% for forward and 1% for backward. They check this also for Chinese idioms, which are four-character sentences.
Chain of Though can solve inverse knowledge search. The model when asked about the verse before something (A1) in bible it says A1 is verse Gensis 9:5 and verse before that is Gensis 9:4 and Genis 9:4 goes as this: … So with enough augmentations you can achieve knowledge inverse search and its advantages.
Part 3.3
1) Through multiple controlled datasets, they establish that language models can and only can store 2 bits of knowledge per parameter, even when quantized to int8, and such knowledge can be flexibly extracted for downstream applications. 2) Prepending training data with domain names (e.g., wikipedia.org) significantly increases a model’s knowledge capacity. Language models can autonomously identify and prioritize domains rich in knowledge, optimizing their storage capacity.
Part 4
They investigated architecture design in an academia scale and suggested a new layer that helped transformers. If you want to do architecture design but are limited by the academia hardware, this can be a great entry point.