Multiplex Thinking Reasoning via Token wise Branch and Merge
Make soft-thinking a bit random. Then train with GRPO.
Read Paper →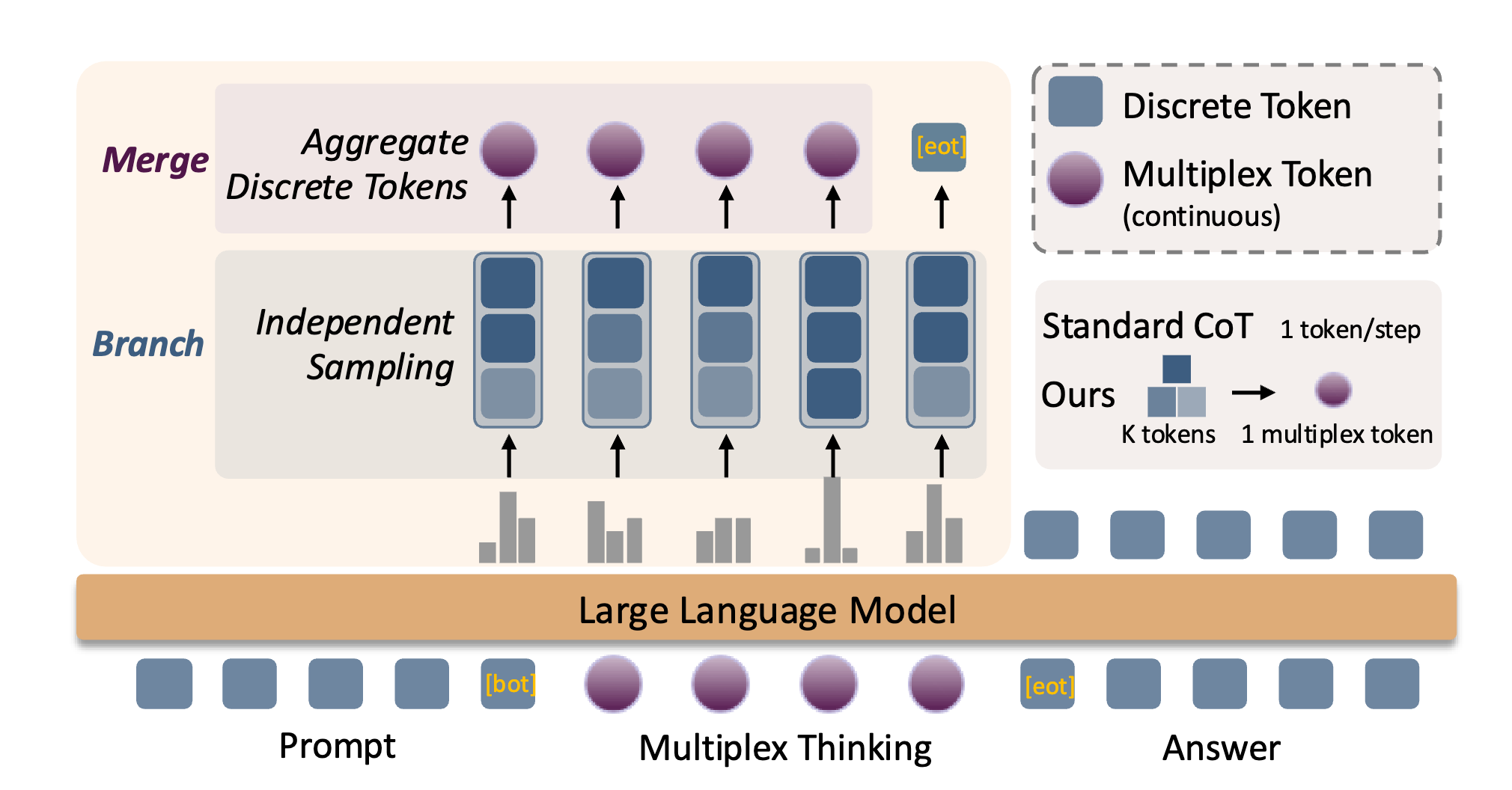
LM-Head Reweighting
The process initiates with the model’s probability distribution \(p\) over the entire vocabulary \(\mathcal{V}\). From this distribution, \(K\) independent token samples, denoted as the multiset \(\{k_1, k_2, \dots, k_K\}\), are drawn. A set of unique candidate tokens, \(\mathcal{S}\), is then formed from these samples, where \(\mathcal{S}\) contains every token that was sampled at least once. The frequency of any given token’s appearance in the initial draw is ignored.
The core of the reweighting calculation involves deriving a new weight, \(w(v)\), for each token \(v\) belonging to the unique set \(\mathcal{S}\). This weight is computed by renormalizing its original probability \(p(v)\) exclusively over the candidates present in \(\mathcal{S}\). So \(w(v) = p(v) / \sum_{u \in \mathcal{S}} p(u)\).
The final soft input token is weighted average of token embeddings with \(w(v)\) weigths.
Analysis
1) Multiplex representations help without training. (Multiplex Thinking-I)

2) K>1 is enough. K=2,3,6 they all work.
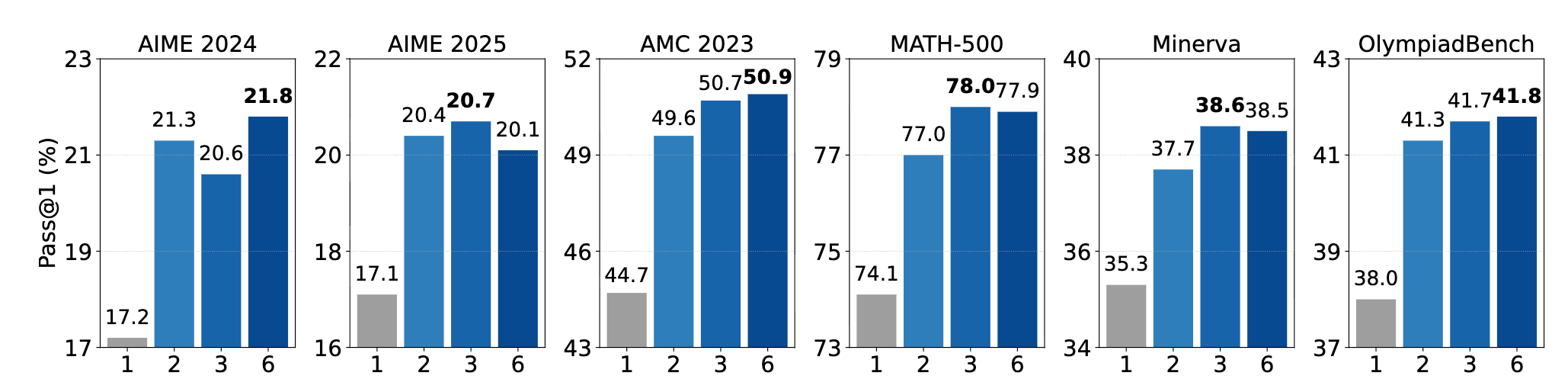
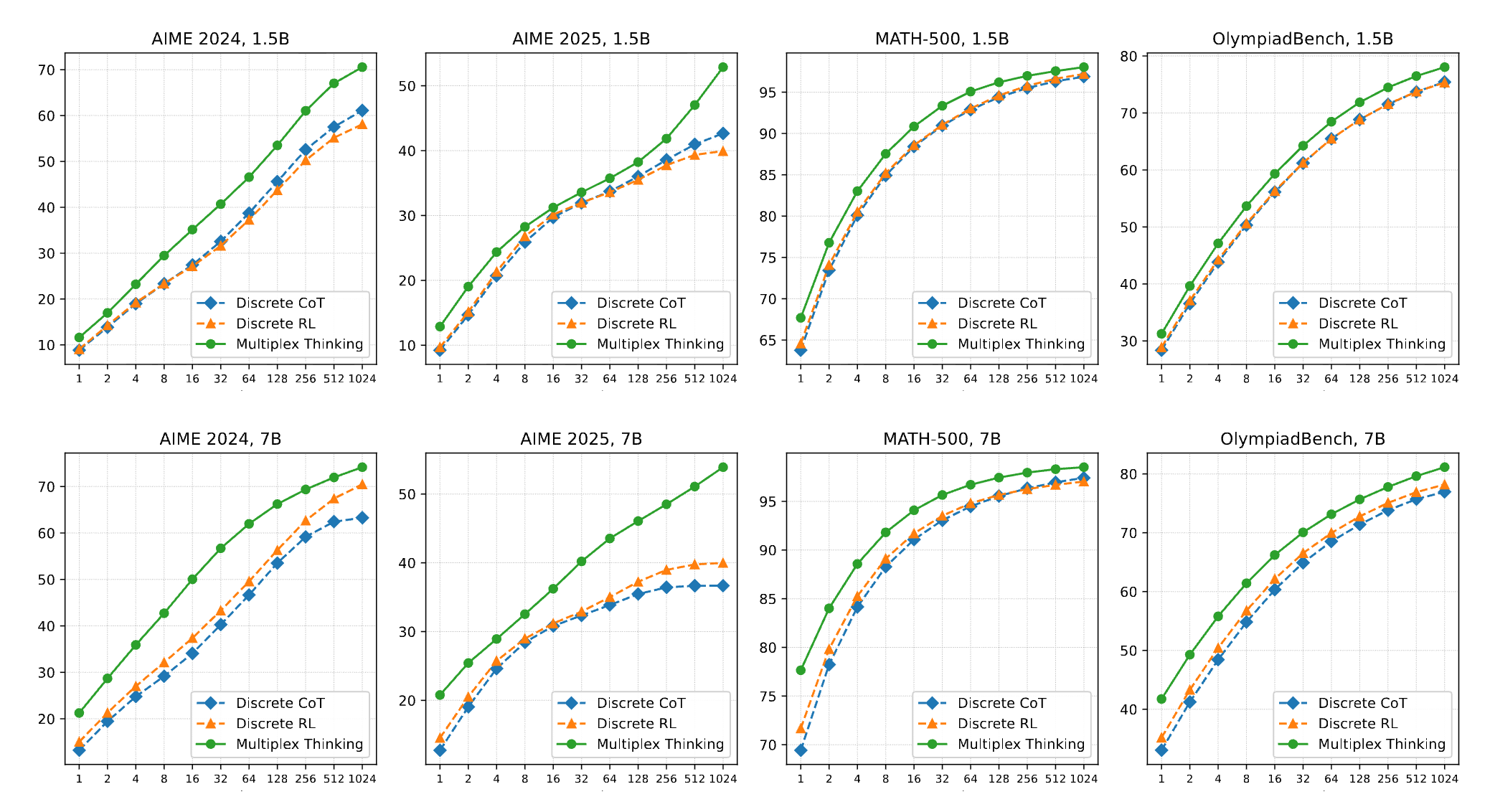
3) They improve both Pass-1 till Pass-1024