Learning to Repair Lean Proofs from Compiler Feedback
A supervised learning approach and dataset for repairing erroneous Lean proofs using compiler feedback and structured natural-language diagnoses.
Read Paper →Method
The APRIL dataset is constructed by systematically introducing errors into correct Lean proofs and pairing them with compiler feedback and corrective targets.
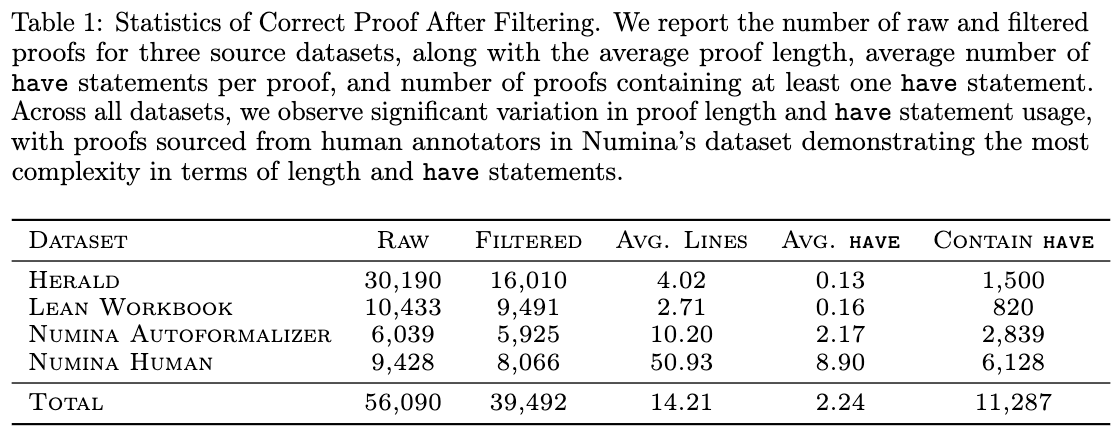
Data collection begins with verified proofs sourced from the Herald, Lean Workbook, and NuminaMath-Lean datasets, filtering for proofs that compile successfully under Lean 4.22.0-rc4. To generate failing proofs, four controlled mutation strategies are applied:
- Theorem Mutation Errors: A theorem identifier in the proof is replaced with a semantically related alternative. Candidates are retrieved via the LeanExplore semantic search engine and filtered to exclude trivial or namespace-only variants.
- Tactic Mutation Errors: A tactic is substituted with an incorrect alternative from the same functional equivalence class (e.g., swapping arithmetic solvers like
nlinarithwithnorm_num, or structural tactics likeintrowithrintro). - Line Mutation Errors: A single proof line after the main
byis replaced with aREDACTEDtoken. DeepSeek-V3 is then prompted to generate an incorrect completion for the redacted line. - Multi-Line Mutation Errors: Up to half of the proof lines are redacted starting from a randomly selected line, and DeepSeek-V3 is prompted to generate incorrect multi-line completions.
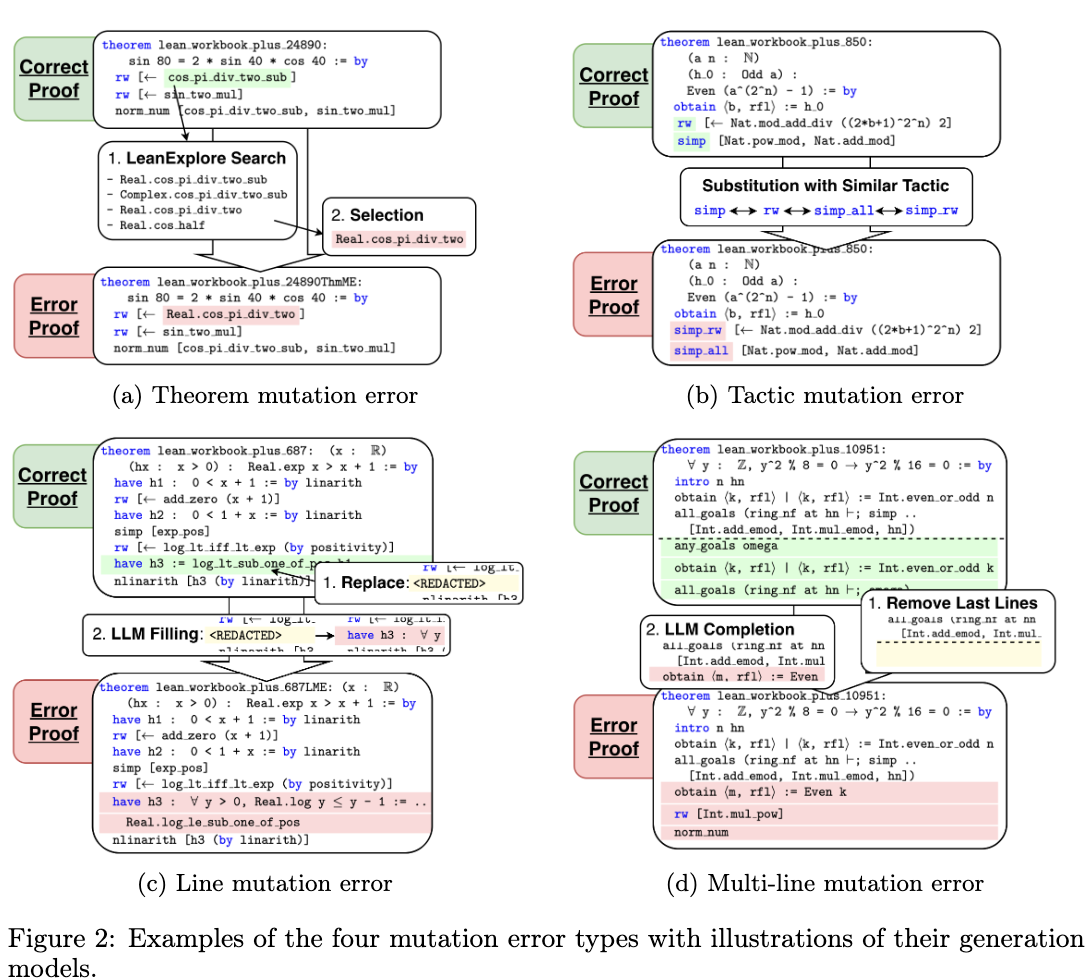
Mutated proofs are compiled in Lean, and only those that produce a compiler error are retained. The data collection pipeline extracts the specific compiler error message and the local goal state at the point of failure. A separate language model (DeepSeek-V3) generates a natural-language explanation of the failure and a suggested fix, conditioned on the original proof, the mutated proof, the compiler error message, and contrastive mutation metadata.
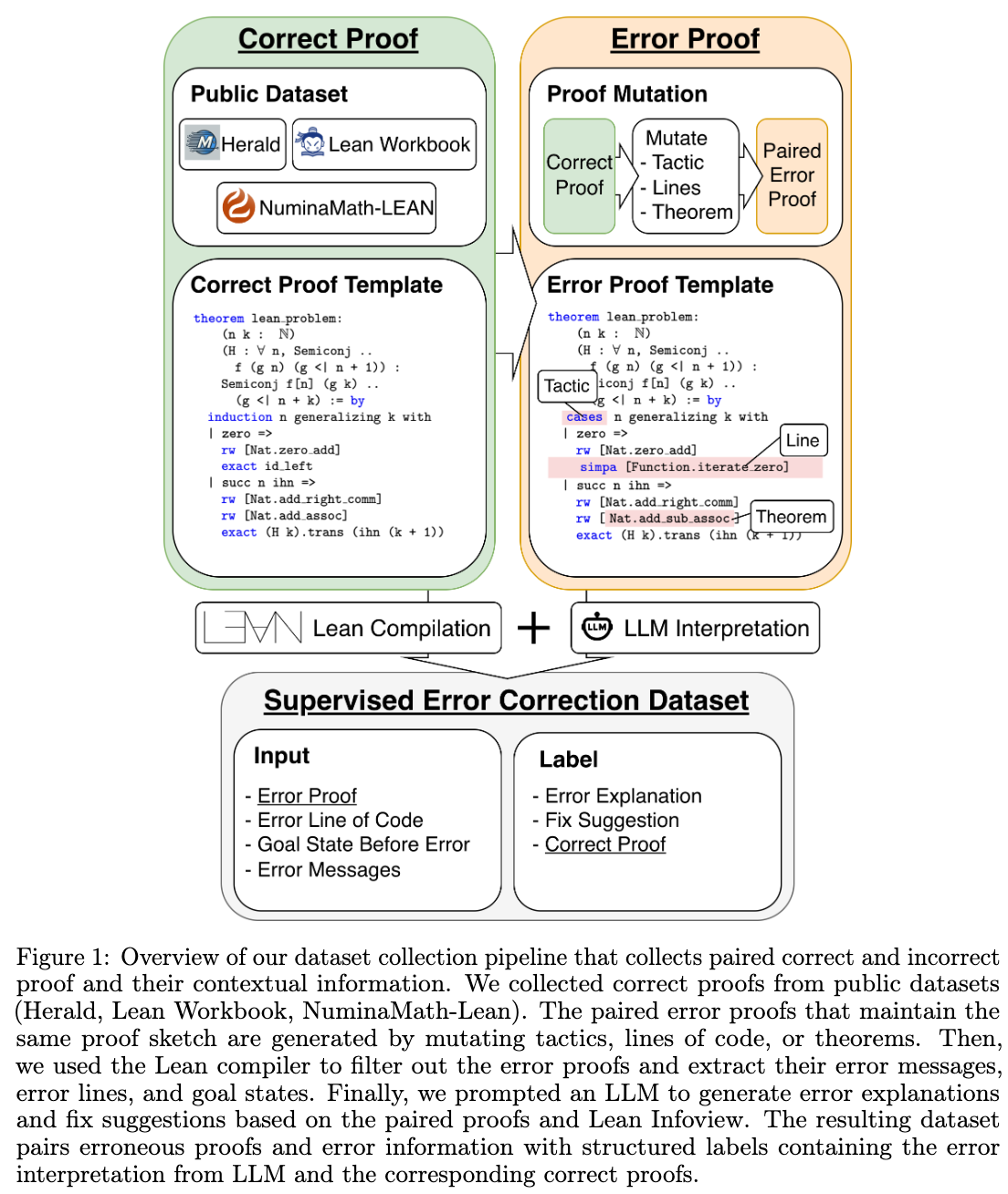
To prevent data leakage during model training, the dataset is split at the level of the original theorems rather than individual mutated proofs. All theorem declarations are anonymized to a canonical lean_problem identifier. The splits are stratified by source dataset, proof length, and mutation type.
The supervised finetuning (SFT) process uses Qwen3-4B-Instruct, Kimina-Prover-Distill-8B, and Goedel-Prover-V2-8B as base models. Training applies Low-Rank Adaptation (LoRA) to both attention and MLP projection layers with rank \(r=32\). The training input consists of a system message and a user message that concatenates the prover error, the local proof state, and the failing proof. The training target is a structured completion containing an explicit diagnostic explanation followed by the corrected code.
Experiments
Model evaluation is conducted on a held-out test set of 1,835 erroneous proofs that span all four mutation types. The primary metric is single-shot repair accuracy, defined as the percentage of model outputs that compile successfully under Lean 4.22.0-rc4 on the first attempt, without relying on inference-time search, multi-sample exploration, or iterative feedback.
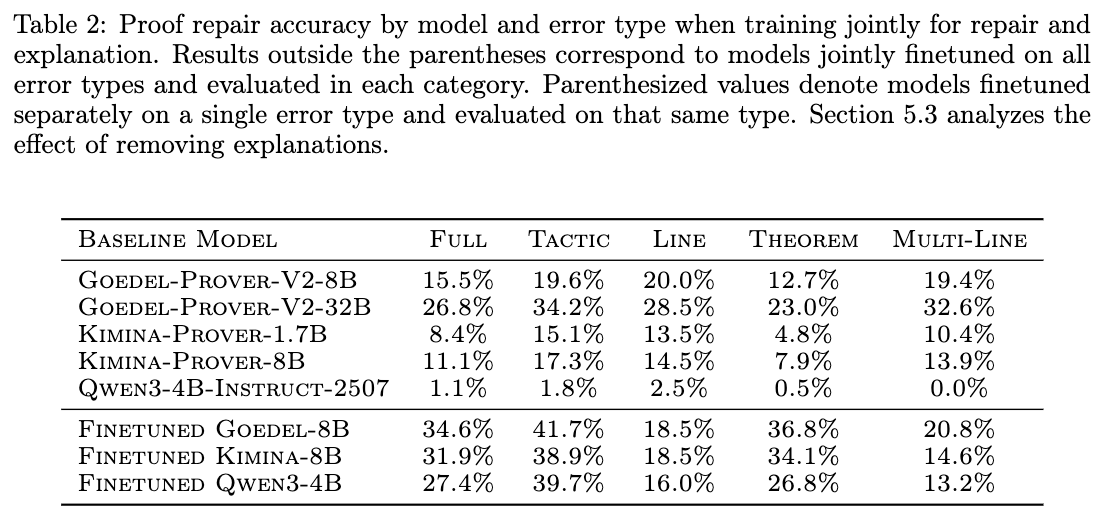
Finetuning on the APRIL dataset increases single-shot repair accuracy. The base Qwen3-4B-Instruct model achieves \(1.1\%\) accuracy, while the finetuned version achieves \(27.4\%\). For 8B parameter models, finetuned Kimina-Prover-8B and Goedel-Prover-8B achieve \(31.9\%\) and \(34.6\%\) accuracy, respectively, compared to baseline performances of \(11.1\%\) and \(15.5\%\). The finetuned 8B models surpass the performance of the base Goedel-Prover-V2-32B (\(26.8\%\)) under the same single-shot protocol.
Repair accuracy varies systematically by mutation type. Tactic mutations exhibit the highest repair rates, reaching \(39.7\%\) to \(41.7\%\) across the finetuned models. Line mutations yield the lowest repair rates, peaking at \(18.5\%\). Models trained jointly on the full dataset containing all error types perform comparably on individual error categories to models trained exclusively on specific error types.
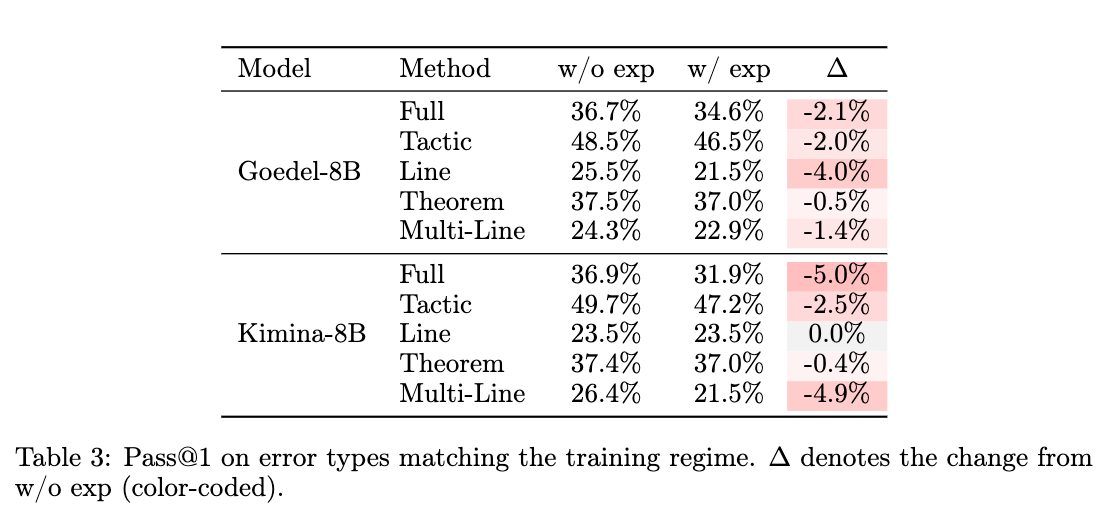
An ablation study evaluates the effect of removing the natural-language explanation from the supervised target. Specializing the objective exclusively on code repair increases the Qwen model’s single-shot repair accuracy from \(27.4\%\) to \(31.2\%\).
However, generating explanations provides downstream utility for other models. In an evaluation where a base DeepSeek model is provided with the failing proof alongside a generated explanation, its repair success rate measures \(4\%\) when using explanations from the base Qwen model, and increases to \(29\%\) when using explanations produced by the model finetuned to predict both diagnoses and repairs.