LeanAgent, Lifelong Learning for Formal Theorem Proving
A lifelong learning framework for formal theorem proving that combines curriculum learning and progressive training to maintain and extend performance across multiple Lean repositories.
Read Paper →A very interesting idea. They use the LLMs to guid the tacktic selection. At each step they embed the proof state (goal, assumptions) along some previously proven theorems that are similar to the current state and ask the model to come up with the next tacktic. They use bean search to explore some different paths.
Method
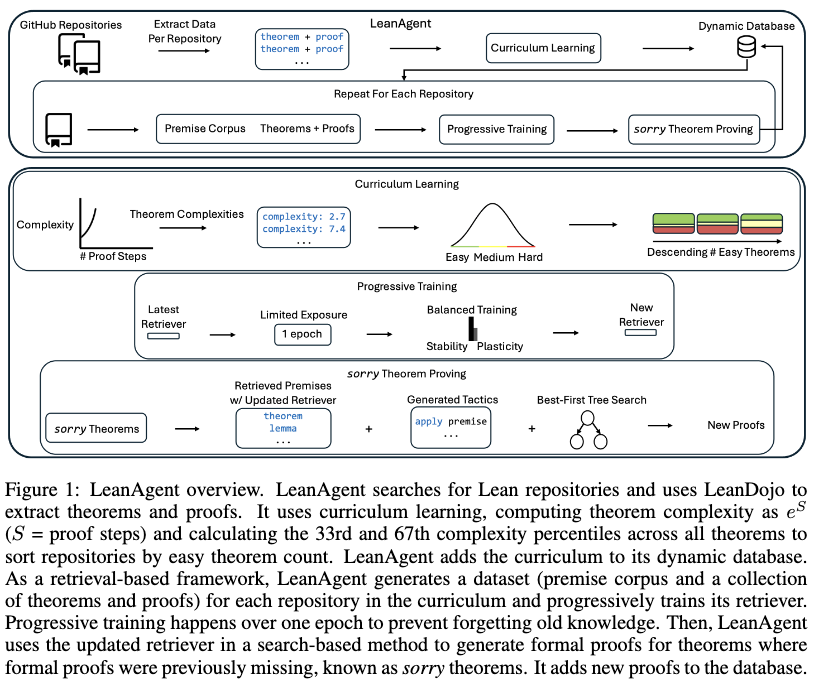
The framework consists of a repository sorting strategy based on curriculum learning, a progressive training procedure for the retriever model, and a search-based theorem prover. A dynamic database manages extracted theorems, proofs, and dependencies across repositories.
Curriculum Learning
Theorem complexity is calculated using an exponential scaling based on the number of proof steps \(S\): $ e^S $. Unproven theorems (labeled as sorry) are assigned infinite complexity. The 33rd and 67th percentiles of this complexity metric are computed across all theorems in all repositories to divide the data into three bins: below the 33rd percentile, between the 33rd and 67th percentiles, and above the 67th percentile. Repositories are then sorted in descending order by the total count of theorems falling in the lowest complexity bin. This sorting determines the curriculum sequence for training.
Progressive Training
A retrieval model is trained incrementally on datasets generated sequentially from the sorted repositories. To mitigate catastrophic forgetting, training is restricted to one epoch per repository dataset.
At the end of each progressive training run, embeddings for all premises in the current corpus are precomputed. The system tracks raw plasticity by recording the model iteration with the highest validation recall for the top ten retrieved premises (R@10). Stability is measured by computing the average test R@10 across all previously seen datasets.
Theorem Proving
For each unproven theorem, a proof is generated using a best-first tree search. The process operates as follows:
- The current proof state is represented as a context embedding.
- Relevant premises are retrieved from the corpus and filtered using a dependency graph to restrict selection to premises accessible from the current file.
- Retrieved premises are appended to the current state, and tactic candidates are generated using beam search.
- Each candidate tactic is passed to Lean to compute potential next states. Valid tactic applications become edges in the search tree.
- The search selects the tactic with the maximum cumulative log probability. If a dead-end is reached, the search backtracks.
The search procedure repeats until a proof is found, all paths are exhausted, or a 10-minute time limit is reached.
Experiments
Experiments evaluate the framework on 23 Lean repositories using a ByT5-based retriever. Performance is compared against a static ReProver baseline, and an ablation study examines different lifelong learning configurations.
Theorem Proving Evaluation
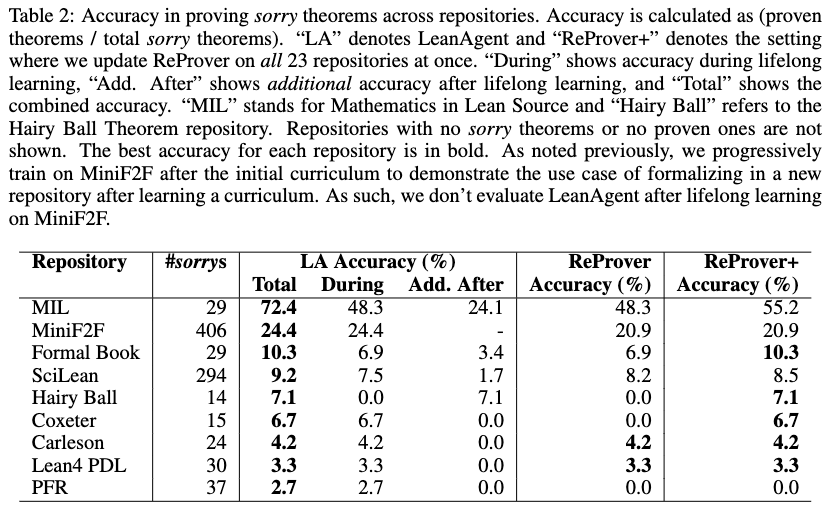
The framework generated formal proofs for 155 previously unproven statements and identified 7 type-system exploits across the 23 repositories. The system was compared against the standard ReProver model and ReProver+, which was updated on all 23 repositories simultaneously rather than sequentially.

Lifelong Learning Ablation
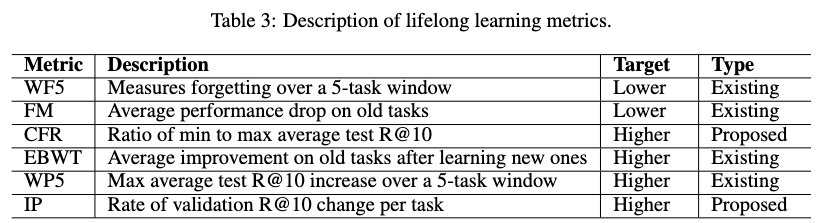
The framework’s handling of the stability-plasticity tradeoff was measured using six metrics evaluated over the sequence of training tasks.
The ablation compared seven configurations varying the data processing order (Curriculum vs. Popularity/Star count), the dataset construction method (Single Repository vs. Merge All historical data), and the training objective (Standard vs. Elastic Weight Consolidation).
Elastic Weight Consolidation (EWC) modifies the loss for task \(B\) to constrain parameters based on the Fisher Information Matrix \(F\) and parameters \(\theta_A\) from the previous task \(A\):
\[L(\theta) = L_B(\theta) + \frac{\lambda}{2} \sum_i F_i(\theta_i - \theta_{A,i})^2\]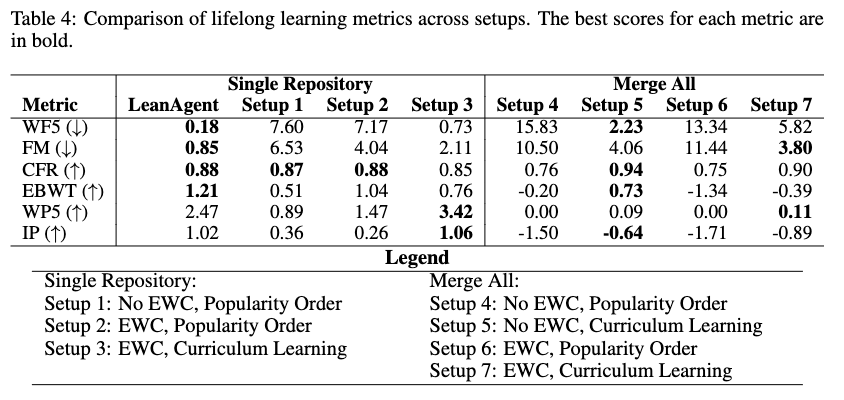
Results from the ablation study indicate:
- The Single Repository setup with Curriculum Order and without EWC yielded the lowest Windowed-Forgetting 5 (WF5) and Forgetting Measure (FM) scores among the Single Repository methods, and output a positive Expanded Backward Transfer (EBWT) score.
- Incorporating EWC increased the WP5 and IP (plasticity) metrics but resulted in higher catastrophic forgetting (higher FM) and lower EBWT.
- Merge All setups generally demonstrated lower FM and higher Catastrophic Forgetting Resilience (CFR) than Single Repository setups. However, all Merge All configurations produced negative Incremental Plasticity (IP) scores, indicating decreasing validation R@10 over time as the aggregated dataset grew.