Latent Sketchpad Sketching Visual Thoughts to Elicit Multimodal Reasoning in MLLMs
A framework that equips Multimodal Large Language Models with an internal visual scratchpad to generate visual latents during autoregressive reasoning, which can be translated into interpretable sketches.
Read Paper →Method
The framework extends existing Multimodal Large Language Models (MLLMs) with two components: a Context-Aware Vision Head integrated into the MLLM backbone and an independently operating Pretrained Sketch Decoder for visualization.
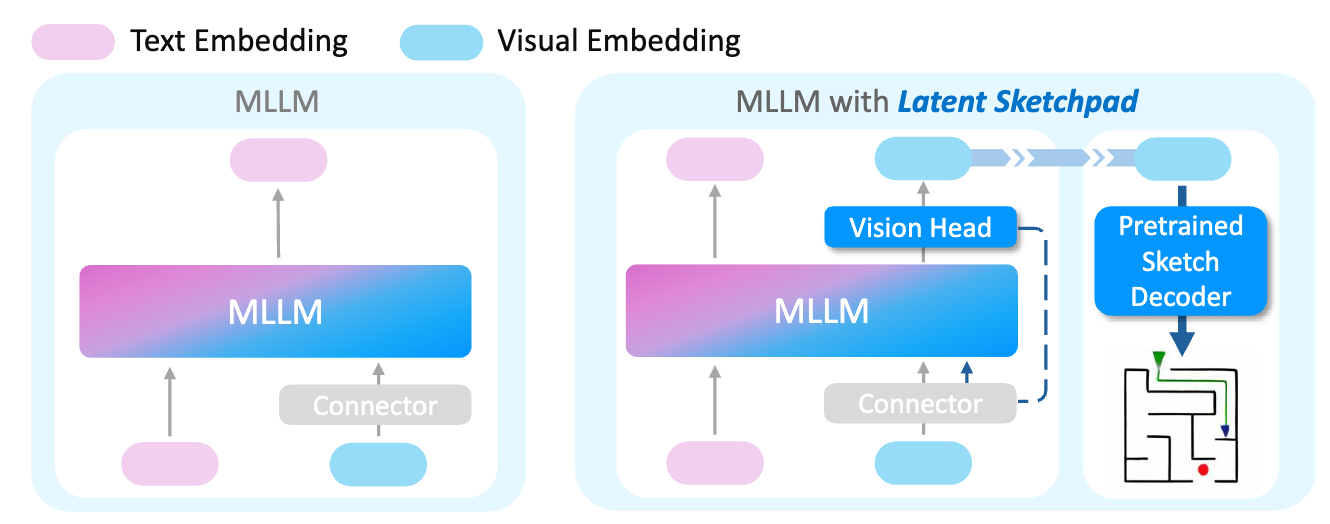
In a standard connector-based MLLM, a vision encoder \(G\) maps an input image \(X_0\) to a sequence of visual tokens \(l_{x_0} = G(X_0) \in \mathbb{R}^{n_v \times d_v}\). A connector module \(C\) then projects these tokens into the language model’s embedding space, \(h_{x_0} = C(l_{x_0}) \in \mathbb{R}^{n_v \times d_h}\). The framework enables the MLLM to autoregressively generate sequences of such visual latents interleaved with text.
Context-Aware Vision Head
The Context-Aware Vision Head generates visual latents autoregressively, conditioned on previous visual and textual context. The generation process for a new image \(X_k\) is initiated by a special <start_of_image> token. To generate each subsequent visual token, the Vision Head leverages both:
- Global Context: Latents of all preceding images in the sequence, providing long-range visual memory.
- Local Context: Latents already generated for the current image \(X_k\), providing short-term visual continuity.
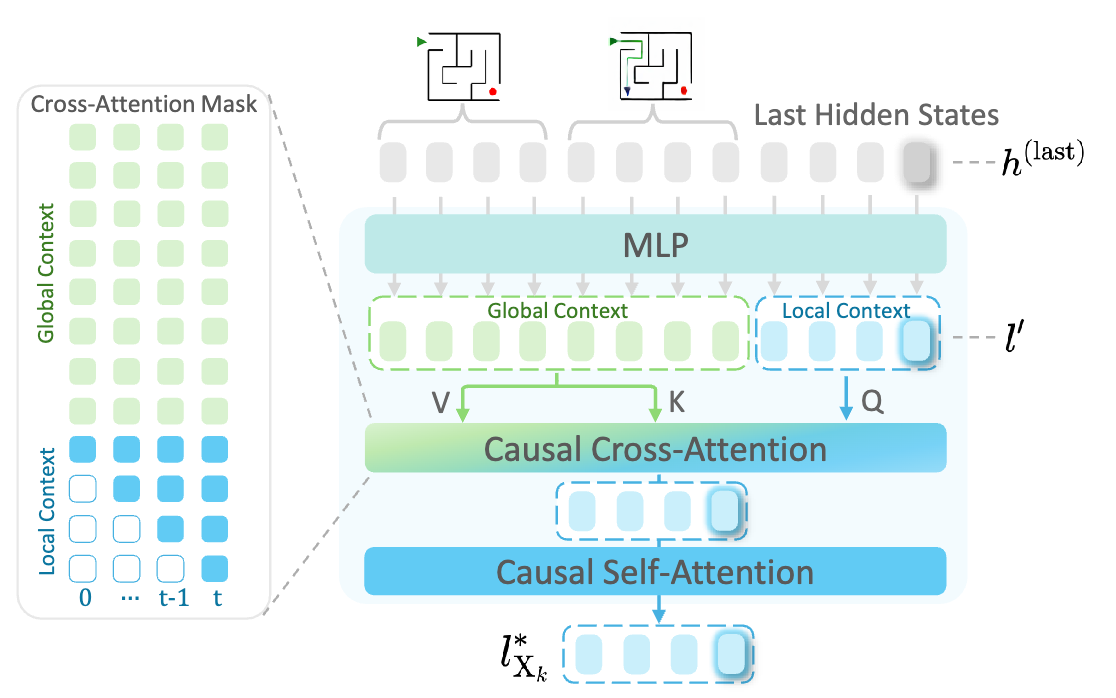
When generating the \(t\)-th visual token for image \(X_k\), the Vision Head collects the last hidden states from the MLLM corresponding to the global and local contexts. These states are projected into a visual latent space. Causal cross-attention is applied over the local and global latent sequences, followed by causal self-attention over the local context latents. This produces a context-enriched latent token \(\hat{l}_{x_k,t}\). This token is projected back into the MLLM’s embedding space to predict the next token. The process repeats for a fixed number of tokens (\(n_v\)) to form the complete visual representation \(l_{x_k}\), and concludes with an <end_of_image> token.
Loss and Training: The Vision Head is trained using a regression loss between the predicted latents \(\hat{l}_{x_k}\) and target latents \(l_{x_k}\) obtained from the MLLM’s pretrained vision encoder.
\[L_{reg} = D(\hat{l}_{x_k}, l_{x_k})\]where \(D(\cdot, \cdot)\) is a distance function, such as L1 distance or cosine similarity. During training, only the Vision Head’s parameters are updated, while the MLLM backbone remains frozen.
Pretrained Sketch Decoder
The Pretrained Sketch Decoder is a standalone module that translates visual latents into human-interpretable sketch images. Its core is a Transformer-based alignment network, AlignerNet, which maps a sequence of visual latents \(l_{x_k}\) from the vision encoder’s feature space to the latent space of a pretrained Variational Autoencoder (VAE). The resulting VAE-compliant latent codes \(z\) are then passed to a frozen VAE decoder to generate a pixel-space image \(\hat{X}_k\).
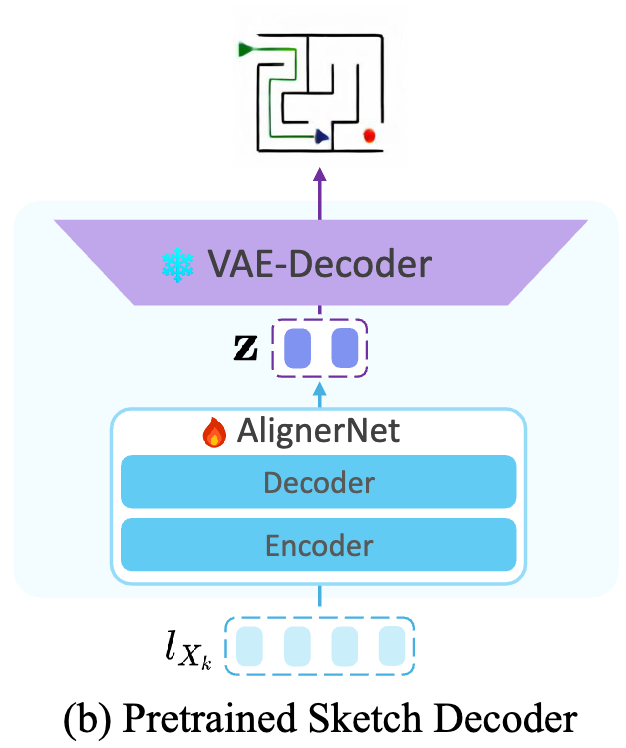
Loss and Training: The Sketch Decoder is trained from scratch with the vision encoder and VAE frozen. It uses a composite loss function:
\[L = L_{rec} + L_{latent} + L_{emb}\]where \(L_{rec}\) is a focal reconstruction loss focusing on foreground pixels, \(L_{latent}\) is a negative log-likelihood loss that aligns the predicted latent distribution with the VAE encoder’s posterior, and \(L_{emb}\) is a mean squared error loss on patch embeddings. The decoder is pretrained on the Quick, Draw! dataset.
Experiments
Experimental Setups
Data: A new dataset, MAZEPLANNING, was constructed for evaluation. It contains 47.8K training mazes (sizes 3x5 to 5x5) with corresponding interleaved text and image reasoning steps. The test set includes 500 in-distribution mazes and a 200-maze out-of-distribution (OOD) set of 6x6 mazes.
Models: The framework was applied to Gemma3-12B and Qwen2.5-VL-7B backbones. These models were evaluated in both text-only Chain-of-Thought (CoT) and multimodal CoT modes. Several proprietary models, including GPT-4o, were also evaluated for comparison.
Evaluation Metrics:
- Success Rate (SR): The percentage of test cases where the model generates a complete and correct action sequence.
- Progress Rate (PR): The ratio of consecutively correct actions before the first error, averaged over all test cases.
Results
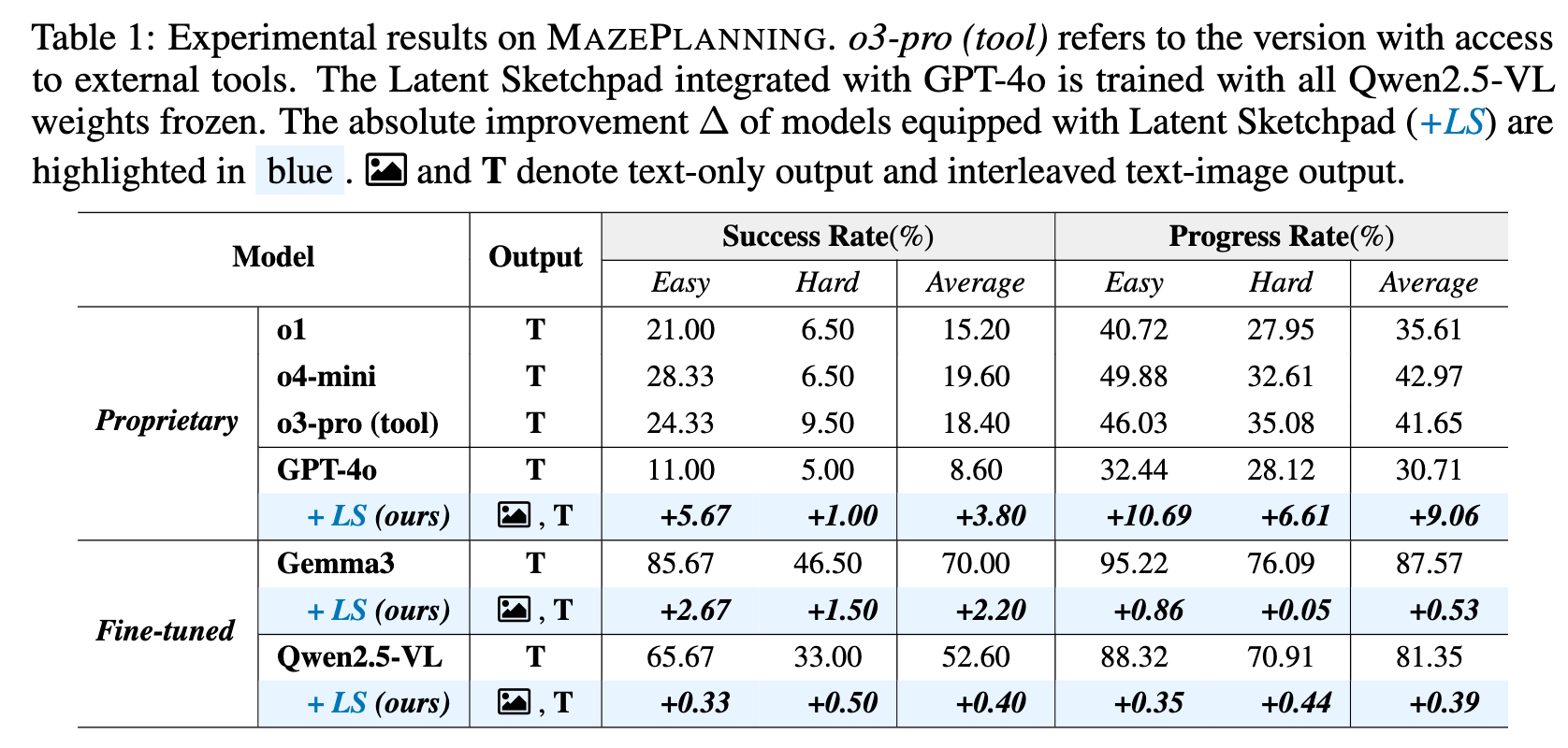
Experiments on the MAZEPLANNING dataset show that proprietary models achieve less than 20% SR. Attaching the Latent Sketchpad to GPT-4o improved its performance. The Vision Head can be trained and attached to different MLLMs (Gemma3, Qwen2.5-VL) while their backbones are frozen, enabling the generation of visual traces during reasoning. The performance of the MLLM backbones with the Latent Sketchpad is comparable to their fine-tuned text-only performance.
Analysis
Quality of Visualizations: Qualitative analysis shows that the generated sketches maintain high structural stability, which is attributed to the Context-Aware Vision Head enforcing consistency during generation.
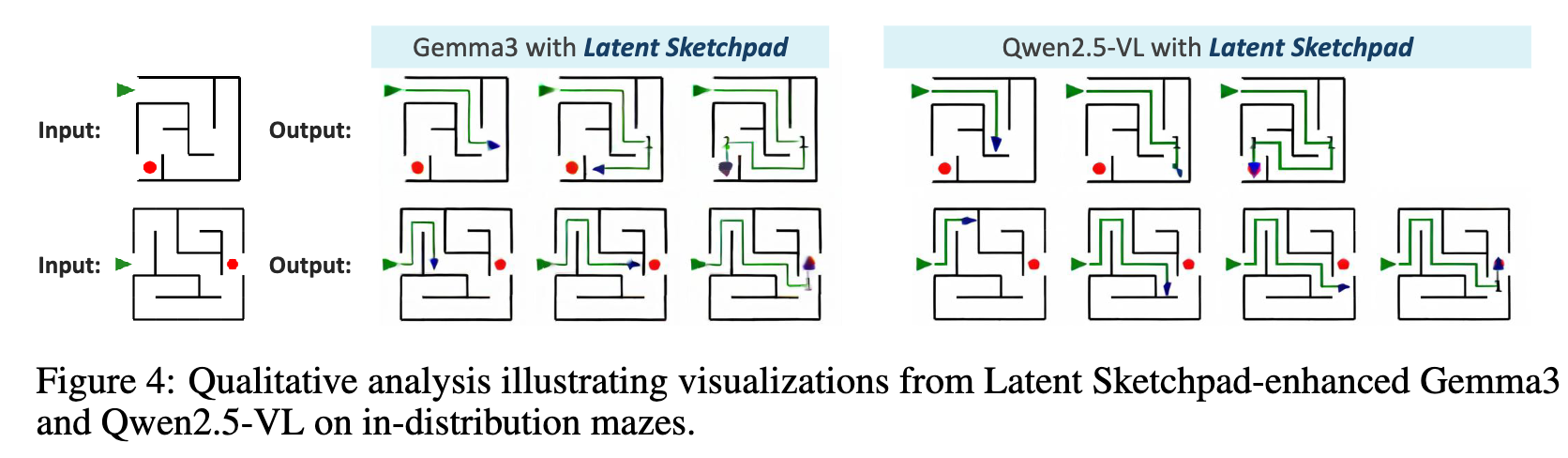
Ablations
- Connector Adaptation: Keeping the MLLM’s connector module frozen during fine-tuning was found to impair spatial understanding and degrade performance.
- Data Augmentation: An augmentation technique involving repeated reconstruction of visual inputs was shown to improve visual accuracy and task success rates.
- Regression Loss: For training the Vision Head, using an L1 distance loss function yielded better results than using cosine similarity.