Latent Chain-of-Thought? Decoding the Depth-Recurrent Transformer
This work investigates the internal mechanics of the Huginn depth-recurrent Transformer on arithmetic tasks to find evidence for latent chain-of-thought reasoning.
Read Paper →Method
The internal states of the Huginn 3.5B model are analyzed using an unrolled view of its architecture. Hidden states are decoded using two methods: logit lens and coda lens.
Unrolled View of Huginn Architecture
The model’s architecture consists of 2 Prelude blocks (\(\{P_1, P_2\}\)), 4 Recurrent Blocks (\(\{R_1, R_2, R_3, R_4\}\)), and 2 Coda blocks (\(\{C_1, C_2\}\)). At inference, input embeddings pass through the Prelude blocks, then undergo \(r\) recurrent passes through the Recurrent blocks, and finally pass through the Coda blocks for prediction. This process can be viewed as a single forward pass through \(2 + 4r + 2\) unrolled blocks.
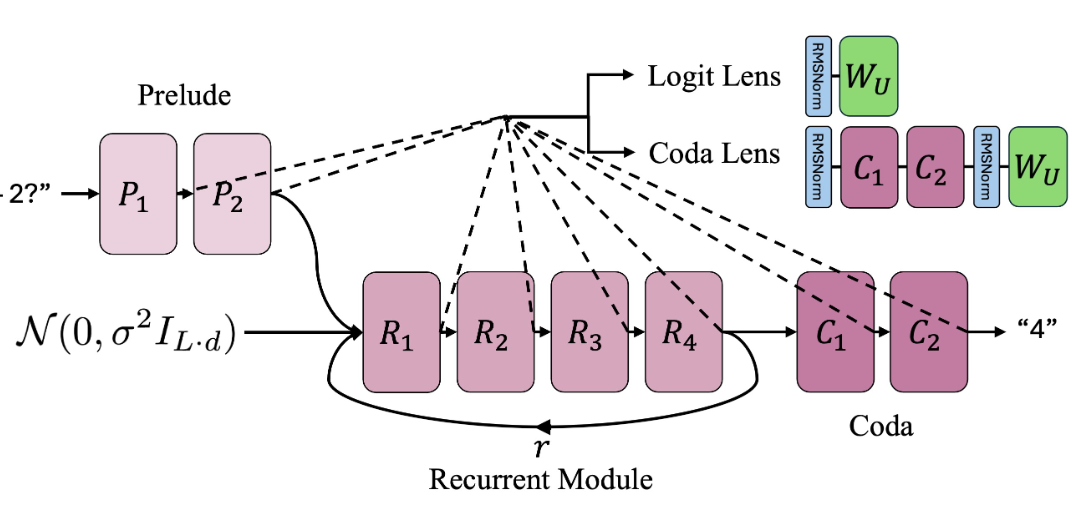
The hidden state \(s_i\) produced by each block \(i\) in this unrolled view is defined as:
\[s_i = \begin{cases} e & i=0 \\ P_i(s_{i-1}) & 1 \le i \le 2 \\ R_1(s_2, n), \quad n \sim \mathcal{N}(0, \sigma^2I_{L \cdot d}) & i=3 \\ R_{(i-3) \pmod 4 + 1}(s_{i-1}) & 4 \le i \le 2+4r, \ i \not\equiv 3 \pmod 4 \\ R_1(s_2, s_{i-1}) & 4 \le i \le 2+4r, \ i \equiv 3 \pmod 4 \\ C_{i-(2+4r)}(s_{i-1}) & 2+4r+1 \le i \le 2+4r+2 \end{cases}\]In the third line, a random vector initializes the recurrence. This unrolled perspective provides access to \(2 + 4r + 2\) intermediate hidden states for analysis.
Decoding Hidden States by Logit Lens and Coda Lens
Two methods are used to decode hidden states \(s_i\) into logits over the vocabulary. Analysis focuses on the logits corresponding to the last token position, \(z_i[-1]\).
Logit Lens: Each hidden state \(s_i\) is normalized and then projected into the vocabulary space using the unembedding matrix \(W_U \in \mathbb{R}^{d \times \lvert V \rvert}\).
\[z_i = \text{RMSNorm}(s_i) W_U\]Coda Lens: Hidden states are decoded using the model’s Coda module, \(C = \{C_1, C_2\}\), which consists of two transformer blocks. Normalization is applied before and after the Coda module.
\[z_i = \text{RMSNorm}(C(\text{RMSNorm}(s_i))) W_U\]Experiments
The model’s behavior is examined on arithmetic tasks where explicit chain-of-thought (CoT) is suppressed.
Experimental Setup
Datasets: The primary dataset is the one-digit composite arithmetic task from Brown et al. (2020), which contains 2k questions (e.g., “What is (9 + 8) * 2? Answer: 34”). The model’s performance is also evaluated on the GSM8K math word problem dataset.
Suppress Explicit CoT: To encourage latent reasoning, explicit CoT is suppressed by instructing the model to output only the final answer. This is done via a system message (“You are a concise and helpful assistant. Always return only the final answer straightway.”) and four in-context examples showing the direct question-to-answer format. For all probing experiments, the number of recurrent steps is set to 16, resulting in a total of 68 unrolled blocks.
Discontinuities in Hidden State Interpretability
The interpretability of hidden states across the unrolled layers is examined by decoding them with both logit lens and coda lens. The average rank of the final correct token is tracked across all 68 blocks for 100 arithmetic questions.
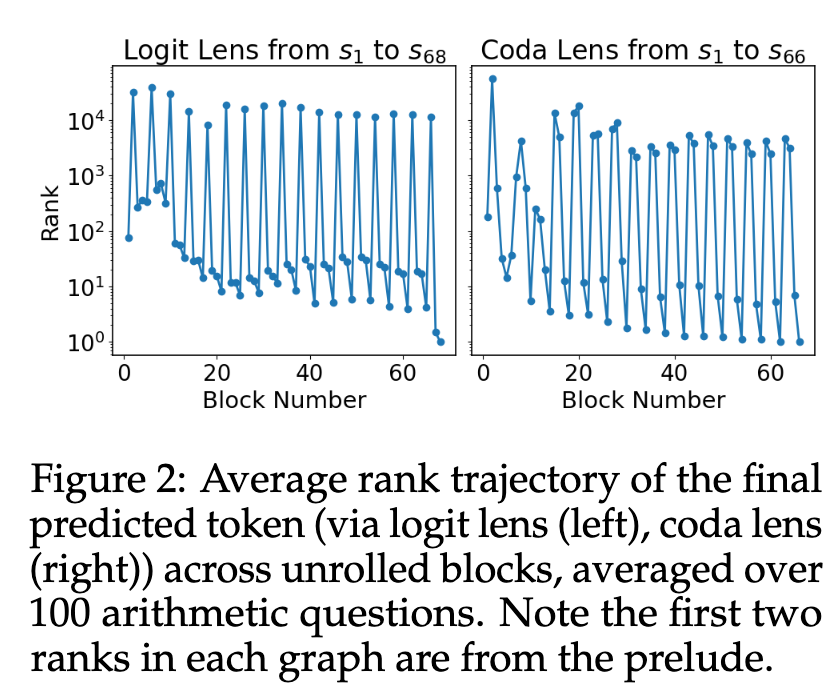
The rank trajectories show periodic oscillations. Using the logit lens, the token rank spikes upwards (becomes worse) at each \(R_4\) block. Conversely, using the coda lens, the rank spikes downwards (becomes better) at each \(R_4\) block.
I don’t know why they use logit lens. It doesn’t make that much sense here. The Coda lens method in my oppinion is much better and should have been the sole interpretability method used.
Tracing Final and Intermediate Tokens
To search for evidence of multi-step reasoning, the rank trajectories of intermediate and final result tokens are traced across recurrent steps. The analysis is performed on a filtered subset of 67 correctly answered questions where the intermediate and final results are distinct single-digit tokens. To reduce the effect of oscillations, the analysis focuses on outputs from block \(R_3\) (for logit lens) and \(R_4\) (for coda lens).
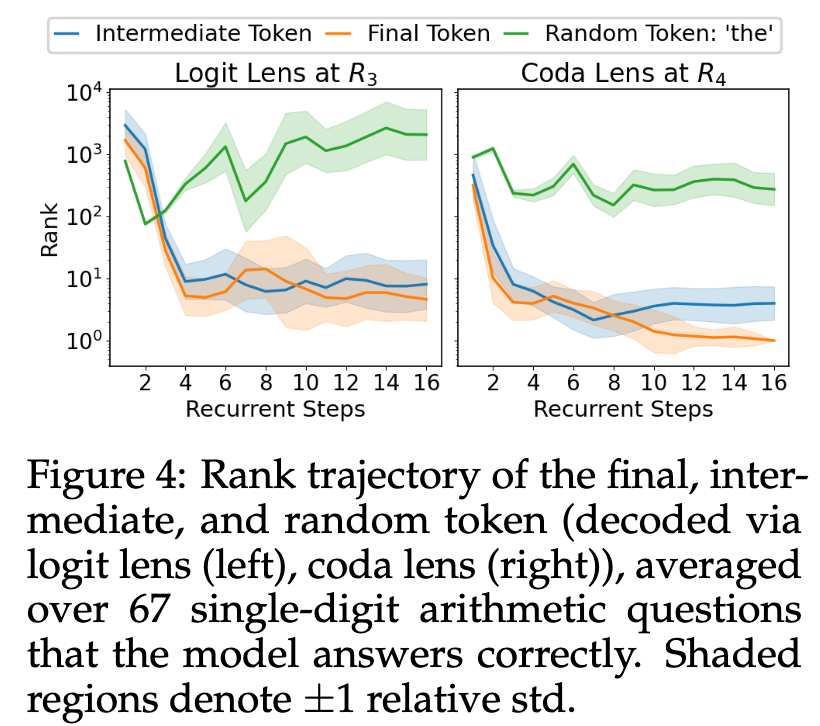
The results show that the ranks of both final and intermediate tokens decrease early in the recurrence. The final token consistently maintains a lower rank than the intermediate token. There is no clear delay between the drop in rank for the intermediate token and the final token, which would be expected in a sequential reasoning process. A rank reversal is observed around step 6, where the intermediate token’s rank briefly drops below the final token’s rank in some examples.
Scaling Recurrent Steps
The model’s performance on the GSM8K dataset is evaluated as the number of recurrent steps is varied, with explicit CoT suppressed.
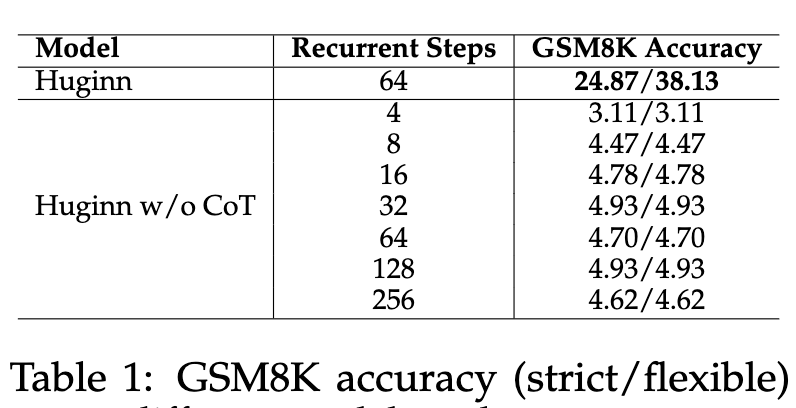
As shown in the results, increasing the number of recurrent steps from 4 to 32 yields a modest increase in accuracy (from 3.11% to 4.93%), after which performance plateaus. In contrast, the same model with explicit CoT prompting achieves a much higher accuracy of 24.87%/38.13%. This suggests that increasing computational depth through recurrence alone is insufficient to match the performance of externalized reasoning steps.