LLMs are Single-threaded Reasoners, Demystifying the Working Mechanism of Soft Thinking
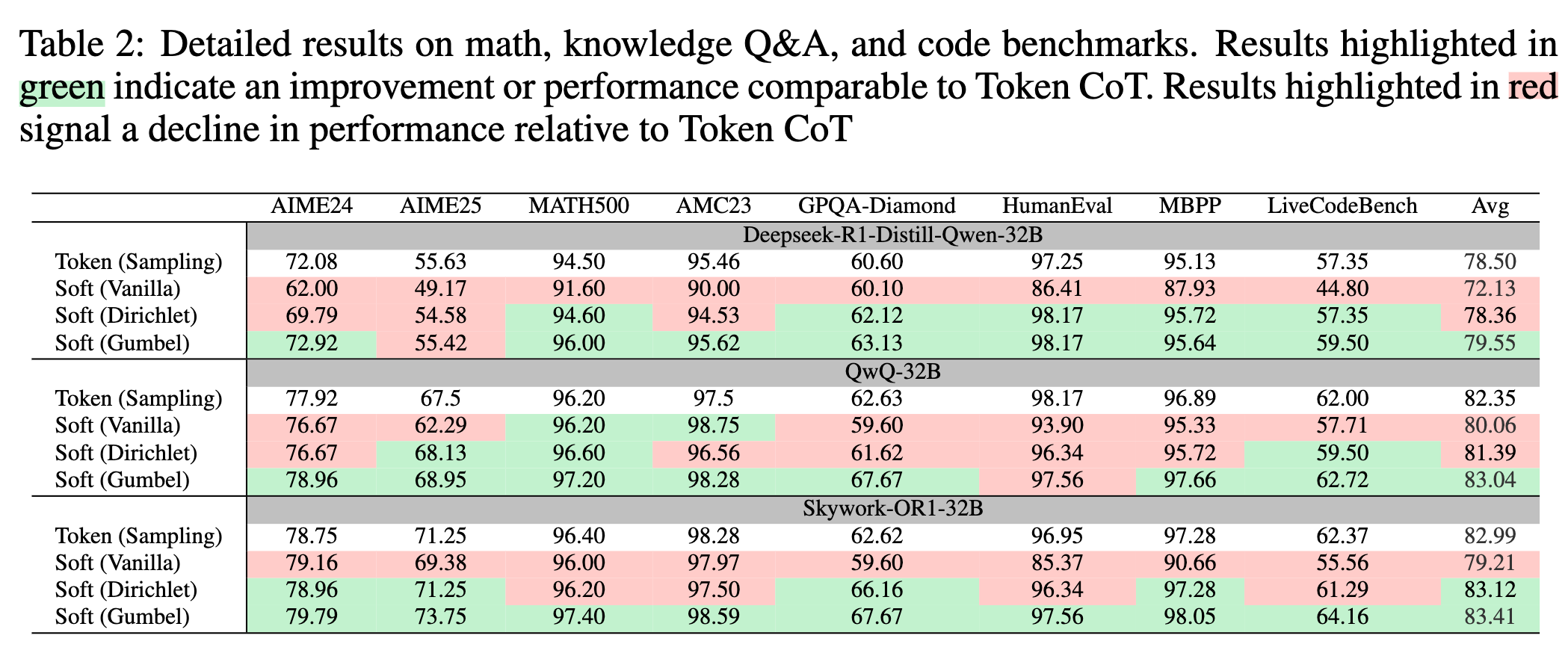
Vanilla Soft Thinking pushes the model to the greedy token sampling internally. They showed that the model usually continues to work only with the most probable next token. To mitigate this issue they suggest adding noise to logits and get better performance.
Read Paper →They first use soft thinking in some benchmarks and show that it gets worse performance compared to normal thinking.
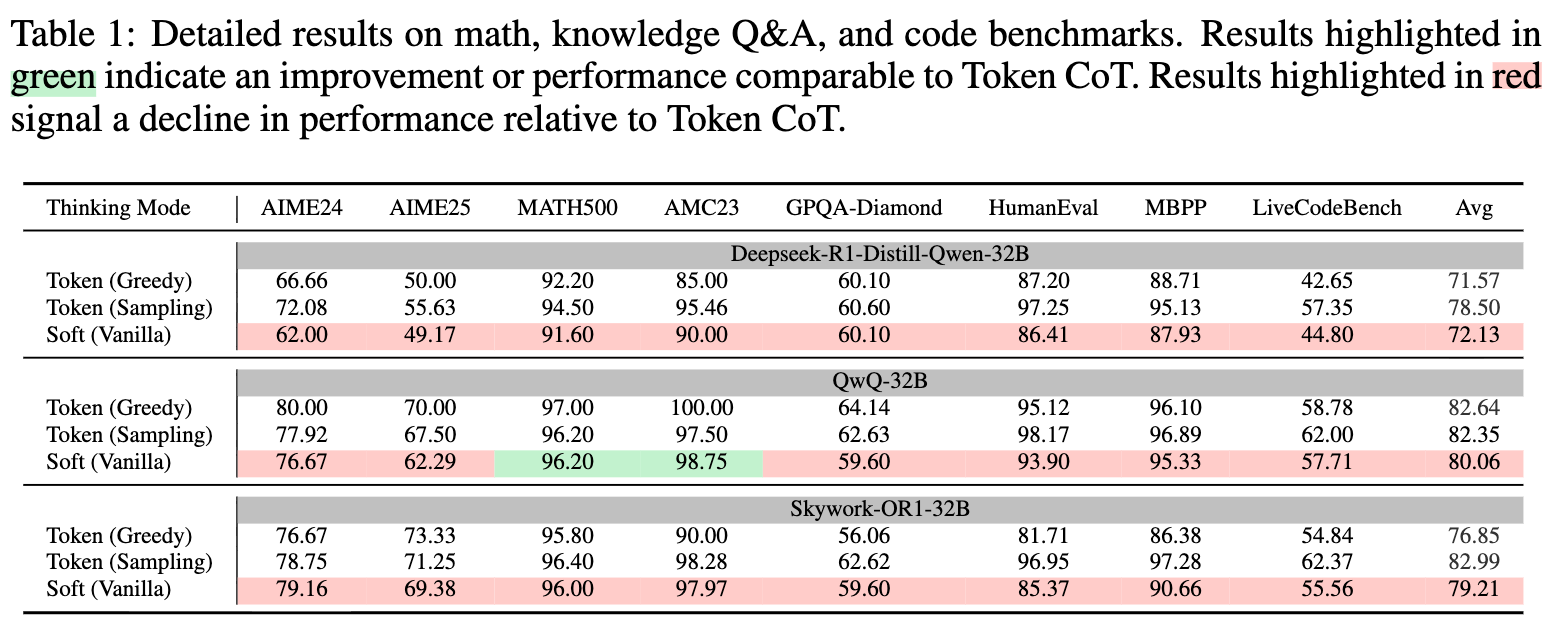
To investigate this, they propose the hypothesis that the model takes the most likely token and continues with that. If this is true, it means soft thinking is just greedy decoding.
Hypothesis: LLMs are Single-Threaded Reasoners
LLMs lack the ability to process multiple different semantic trajectories in parallel. When a Soft Token is fed into an LLM, the generation process is typically dominated by the majority component of the Soft Token.
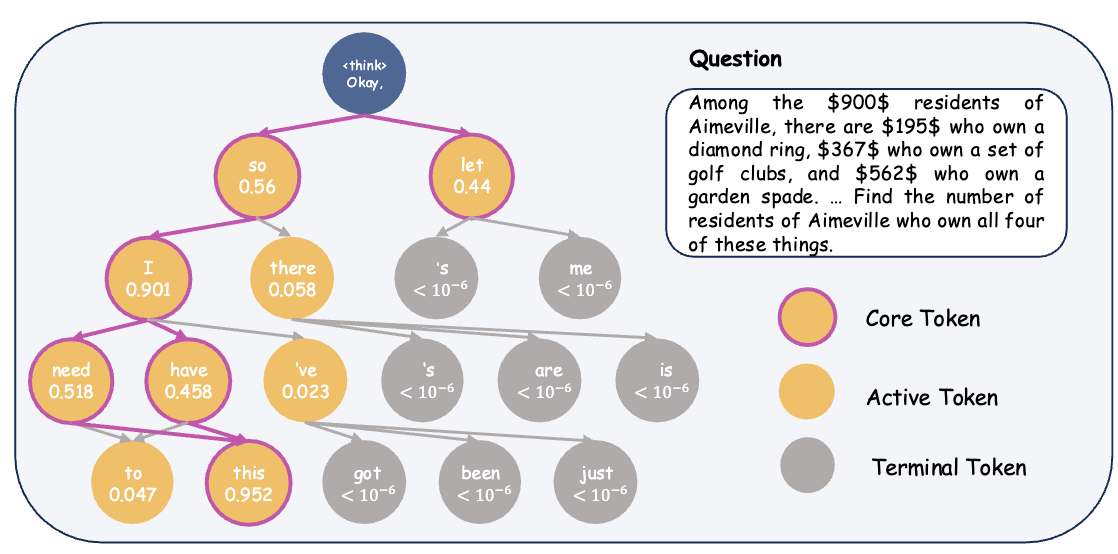
To test this, they replace a soft token with a discrete token, either the 1st dominant token in the soft thinking or the 2nd dominant token in the soft thinking. Then they measure the divergence in the predicted probabilities. For instance, assume we have question \(X\) and a soft thinking reasoning of \([S_1, S_2, \cdots, S_n]\). We investigate the i-th token, so we replace it with 1st dominant token \(T_i^1\) or second dominant token \(T_i^2\). We measure the JS Divergence of \(S_{i+1}\) with the model prediction when given: \([X, S_1, S_2, \cdots, S_{i-1}, T_i^1]\) and \([X, S_1, S_2, \cdots, S_{i-1}, T_i^2]\). They showed that for most cases the JS Divergence between \(S_{i+1}\) and replacement of \(T_i^1\) is very low and very high with replacement of \(T_i^2\).
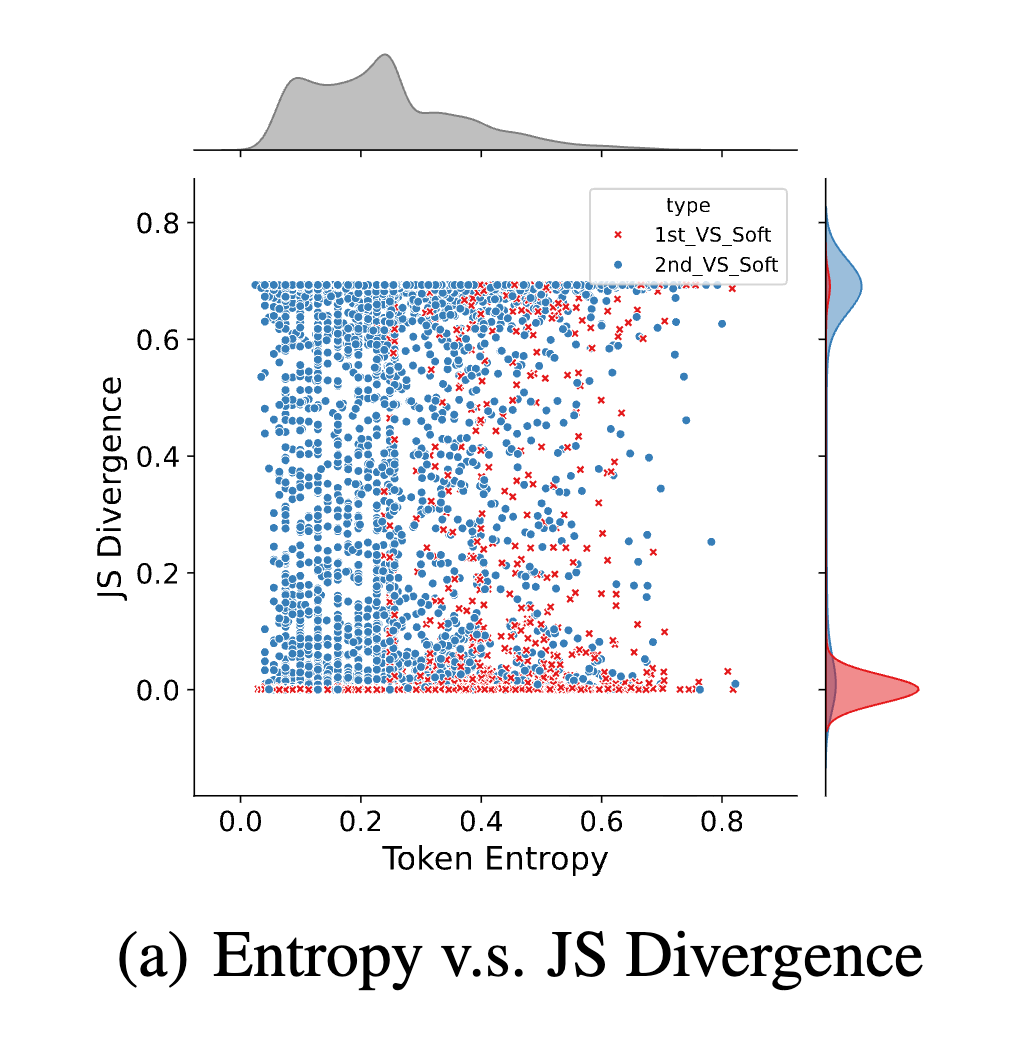
Then they try to figure out where the model ignores other tokens and starts to only consider the most dominant token. They find some soft thinking reasoning tokens that have two different dominant tokens, \(T_i^1\) and \(T_i^2\) for instance. Then they make a soft thinking token consist only of those two tokens: \(S_i=0.6 T_i^1 + 0.4 T_i^2\). They again test
1) \([X, S_1, S_2, \cdots, S_{i-1}, T_i^1]\)
2) \([X, S_1, S_2, \cdots, S_{i-1}, T_i^2]\)
3) \([X, S_1, S_2, \cdots, S_{i-1}, S_i]\)
They get the top 5 predicted tokens for the first two lines. Then they investigate the behaviour of the soft thinking (third line). They see that when the model goes deeper into layers, the predicted tokens have less and less intersection with the second dominant token prediction and more intersection with the first dominant token prediction.
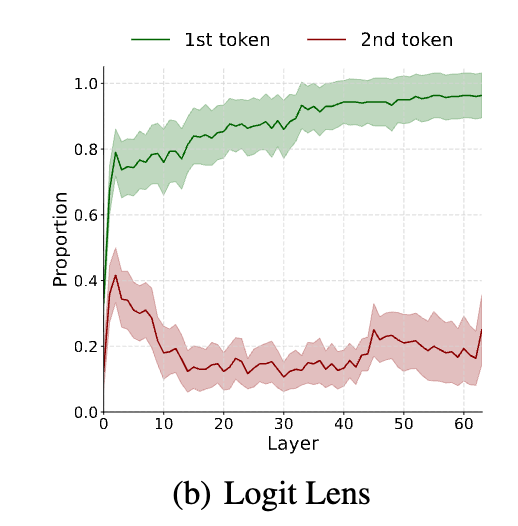
They ignored the fact that the second dominant token continues to have 0.2 intersection until the end. Is it possible that the soft thinking top 10 guesses consist of 9 from the most dominant token and 1 from the less dominant token?
Finally, they also take a soft thinking reasoning path and extract the most dominant token at each position to form an explicit reasoning path. They see that it is more aligned with greedy decoding (taking the token with the highest probability at each step) than with normal decoding (sampling tokens randomly based on model logits).
Methods
They investigate two types of noise they can add to logits:
-
Dirichlet sampling: First multiply probabilities by a constant \(0 < \gamma < < 1\). Then get the probabilities from \(Dir(\gamma p)\). The Dirichlet sampling works as follows: sample \(Y_i\sim gamma(\alpha_i, \text{scale}=1)\). Then \(\hat{\pi}_i= \frac{Y_i}{\sum_j Y_j}\).
-
Gumbel-Softmax Trick: Assume we have probabilities \(\pi_i\). We want to make it noisy \(\hat{\pi}_i\). We sample a noise for each element \(g_i\sim Gumbel(0,1)\), and then
They showed that Gumbel works very well and performs better than Dirichlet.
GRPO
In GRPO we need a policy ratio for each token:
\[r_t(\theta) = \frac{\pi_{\theta}(y_t \mid x, y_{<t})}{\pi_{\text{ref}}(y_t \mid x, y_{<t})}\]In soft thinking, we don’t have \(y_t\) as there is no selected token. They propose we can do this instead: define the probability of choosing that soft-thinking token as
\[p_{\pi, \tau}(y_1, \dots, y_n) = \Gamma(n) \tau^{n-1} \left( \sum_{i=1}^n \frac{\pi_i}{y_i^\tau} \right) \prod_{i=1}^n \frac{\pi_i}{y_i^{\tau+1}}\]and then for soft-thinking \(i\) we have: \(r_t(\theta) = \frac{p_{\pi_{\theta}, \tau}(y_1, \dots, y_n)}{p_{\pi_{\text{ref}}, \tau}(y_1, \dots, y_n)}\).
They did not do GRPO themselves.