Imagine while Reasoning in Space Multimodal Visualization-of-Thought
Multimodal Visualization-of-Thought (MVoT) is proposed to enable Multimodal Large Language Models (MLLMs) to generate interleaved verbal and visual reasoning traces for spatial reasoning tasks.
Read Paper →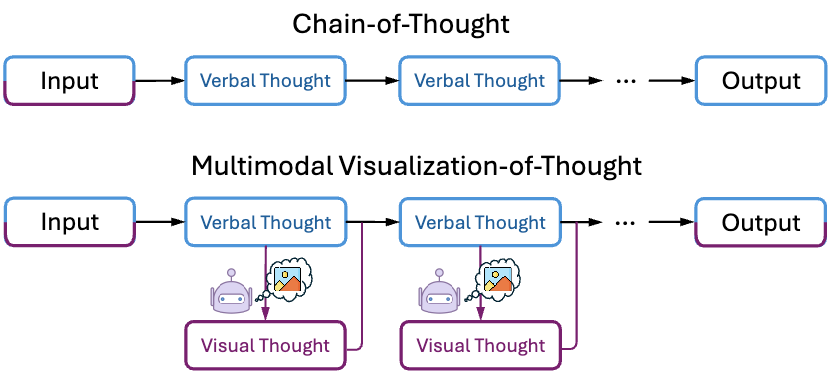
Method
They did not do GRPO. They made some data of question, text, image, text, image, text, image and did sft on it.
The proposed method, Multimodal Visualization-of-Thought (MVoT), enables a model to generate interleaved verbal and visual thoughts as part of its reasoning process. Given a multimodal input \(x\), the model produces sequences of verbal thoughts \(z\) and visual thoughts (image visualizations) \(\hat{v}\) before arriving at a final answer.
Formulation
MVoT extends the Chain-of-Thought (CoT) process, which generates a sequence of textual intermediate steps \(z_1, \dots, z_m\). MVoT adds an image visualization \(\hat{v}_i\) after each verbal step \(z_i\). The subsequent verbal step \(z_{i+1}\) is then conditioned on all prior verbal steps and visual thoughts. A visual thought \(\hat{v}_i\) and a subsequent verbal thought \(z_{i+1}\) are sampled as follows:
\[\hat{v}_i \sim P_{\theta}(v_i \mid z_1, \hat{v}_1, \dots, \hat{v}_{i-1}, z_i)\] \[z_{i+1} \sim P_{\theta}(z_{i+1} \mid x, z_1, \hat{v}_1, \dots, z_i, \hat{v}_i)\]The model is trained on multimodal inputs and corresponding outputs that include the full sequence of multimodal rationales \((z_1, \hat{v}_1, \dots, z_n, \hat{v}_n)\) and the final answer.
Training with Autoregressive MLLMs
The implementation uses an autoregressive MLLM based on the Chameleon architecture, which processes both image and text tokens within a unified Transformer. This architecture employs separate tokenizers for text and for images, the latter of which converts images into sequences of discrete tokens from a visual codebook \(C \in \mathbb{R}^{N \times D}\).
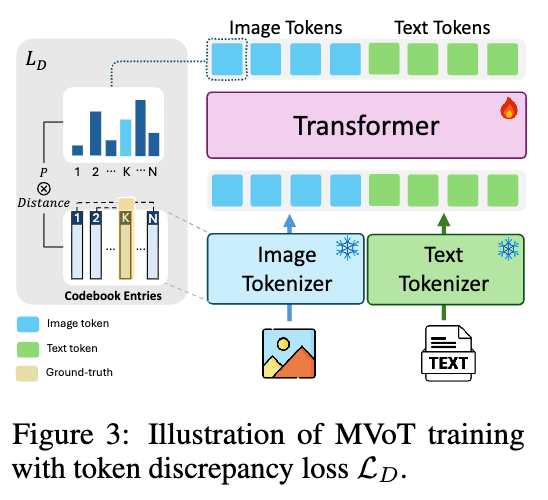
To address the issue of degraded image quality arising from the discrepancy between the separately trained tokenizers, a token discrepancy loss (\(L_D\)) is introduced. This loss operates in the visual embedding space to align the language model’s predictions with the visual tokenizer’s embeddings.
First, for each ground-truth image token \(t_{\text{vis}_i}\), a similarity matrix \(S_{t_{\text{vis}_i}}\) is computed. This matrix measures the similarity between \(t_{\text{vis}_i}\) and all other tokens in the codebook based on the mean squared error (MSE) of their corresponding visual embeddings \(e_{\text{vis}}\).
\[S_{t_{\text{vis}_i}} = [\text{MSE}(e_{\text{vis}_i}, e_{\text{vis}_1}), \dots, \text{MSE}(e_{\text{vis}_i}, e_{\text{vis}_N})] \in \mathbb{R}^{1 \times N}\]The token discrepancy loss \(L_D\) then penalizes the model for assigning high probabilities \(P(t_i)\) to tokens that are distant from the ground-truth token \(t_{\text{vis}_i}\) in the visual embedding space.
\[L_D = \sum_{i=1}^n S_{t_{\text{vis}_i}} P(t_i)\]The model is fine-tuned with a total loss function that combines the standard cross-entropy loss \(L_C\) for next-token prediction (applied to both text and image tokens) and the token discrepancy loss \(L_D\) (applied only to image tokens).
\[L = L_C + L_D\]During this fine-tuning process, the image and text tokenizers remain frozen.
Training data
question, (text + image) -> (text + image) -> ... for three tasks in the experiemnts.
Experiments
The effectiveness of MVoT is evaluated on three dynamic spatial reasoning tasks in grid-based environments.
Tasks:
- MAZE: The model must determine an agent’s final destination in a maze after following a given sequence of actions.
- MINIBEHAVIOR (InstallingAPrinter): The model predicts the outcome of an action sequence where an agent must locate a printer, pick it up, place it on a table, and toggle it on.
- FROZENLAKE: The model determines the outcome of an agent’s navigation across a frozen lake, where the agent must reach a destination without falling into holes.
Experimental Setup
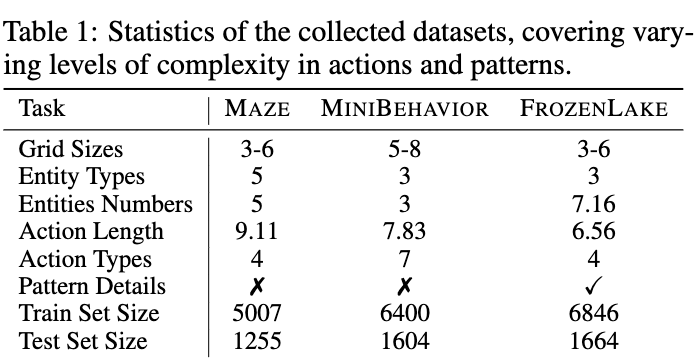
Datasets were constructed for each of the three tasks.
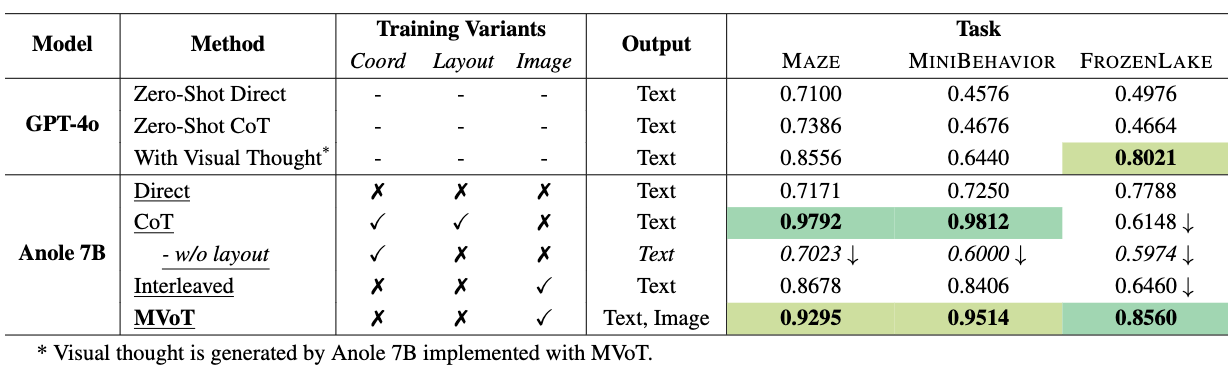
The backbone model is Anole-7B, which is fine-tuned using LoRA. MVoT is compared against several baselines:
- Direct Prompting (Direct): The model generates the final answer directly without intermediate reasoning steps.
- Chain-of-Thought (CoT): The model generates step-by-step textual reasoning before the final answer.
- Interleaved: A standard MLLM training approach where text and image data are interleaved, but the loss is computed only on text tokens.
- GPT-4o: Evaluated in zero-shot, CoT, and a setting where it uses visual thoughts generated by the fine-tuned MVoT model.
The primary evaluation metric is the accuracy of the final answer in the multiple-choice format.
Results
Ablations and Analysis
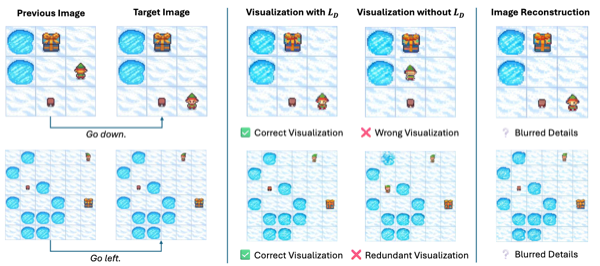
Visualization Quality: The contribution of the token discrepancy loss (\(L_D\)) was evaluated.