Hilbert Recursively Building Formal Proofs with Informal Reasoning
A multi-agent framework that orchestrates general-purpose reasoning models and specialized prover models to recursively decompose and solve formal mathematical theorems.
Read Paper →Method
HILBERT is a multi-agent system that connects informal mathematical reasoning with formal verification. It applies recursive subgoal decomposition to divide complex theorems into simpler subgoals. The system coordinates four components:
- Reasoner: A general-purpose large language model (LLM) (e.g., Gemini 2.5 Pro, gpt-oss-120b) used to write informal proofs, generate proof sketches in Lean 4, and occasionally write formal proofs.
- Prover: A specialized LLM (e.g., DeepSeek-Prover-V2-7B, Goedel-Prover-V2-32B) optimized for writing formal proofs given a formal theorem statement.
- Verifier: A formal language verifier (Kimina Lean Server with Lean v4.15.0 and Mathlib v4.15.0) used to check the syntactic and mathematical correctness of theorem statements and proofs.
- Retriever: A semantic search engine utilizing sentence transformers and FAISS indexing to fetch relevant theorems from the Mathlib library.
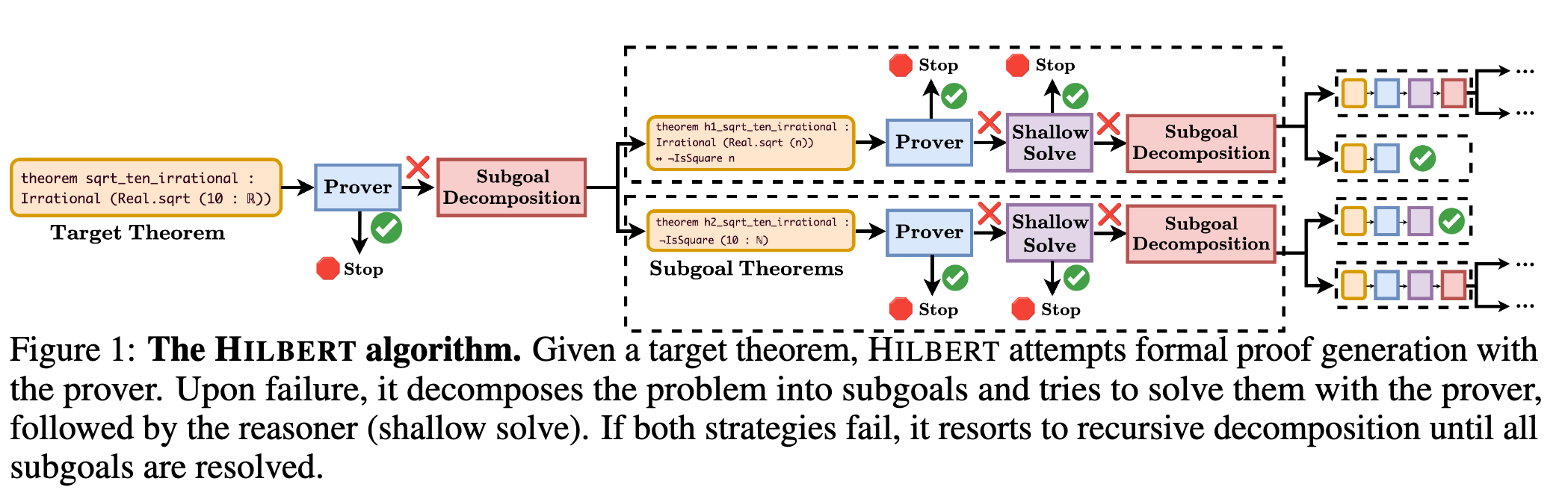
Given a formal theorem statement in Lean 4, the system first attempts a direct proof using the Prover. The Prover generates \(K_{\text{initial proof}} = 4\) candidate proofs. These are checked by the Verifier. If any proof is valid, it is returned. If all direct attempts fail, the system employs the Reasoner to execute the subgoal decomposition algorithm.
Subgoal Decomposition
The subgoal decomposition process breaks the problem into subproblems and assembles a proof strategy.
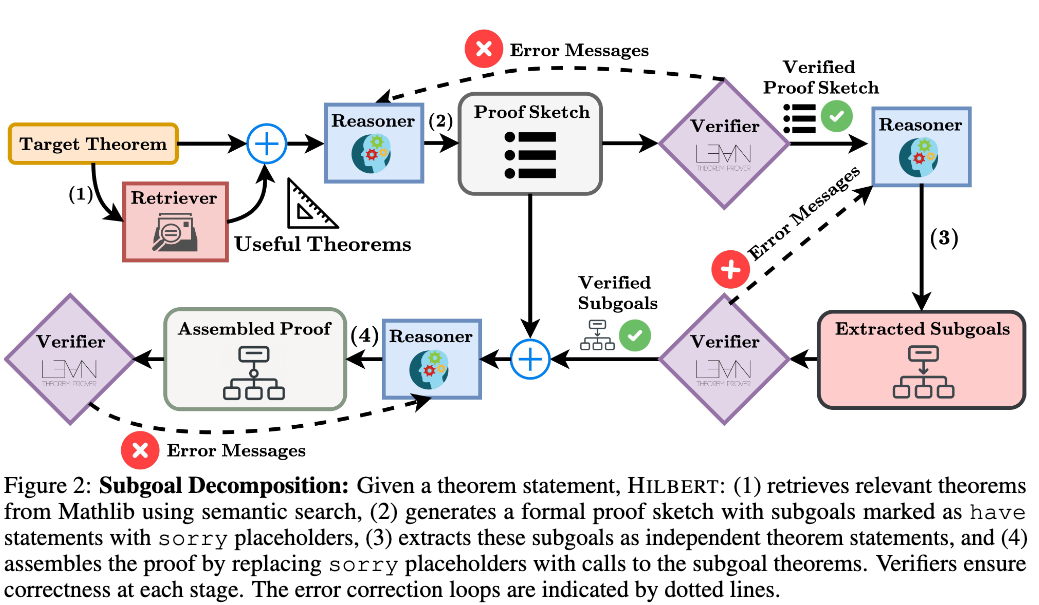
- Theorem Retrieval: The Reasoner generates \(s = 5\) search queries related to the formal statement. The Retriever fetches the top \(m = 5\) most semantically similar theorems and tactics from Mathlib per query. The Reasoner filters these results to retain only relevant theorems.
- Formal Proof Sketch Generation: The Reasoner writes a detailed informal proof using the retrieved theorems. Using this as context, the Reasoner generates a Lean 4 proof sketch, breaking the problem into subproblems represented as
havestatements. Subgoals are initially filled with thesorryplaceholder keyword. The Verifier checks the sketch. In case of errors, Verifier feedback is used to correct the sketch. The system allows up to \(K_{\text{sketch attempts}} = 4\) attempts per theorem. - Subgoal Extraction: The Reasoner converts the
havestatements from the proof sketch into independent theorem statements, carrying over relevant context from the original problem and preceding subgoals. The Verifier checks the syntax of each extracted theorem, and errors are fed back to the Reasoner for correction. - Sketch Assembly from Subgoals: The Reasoner receives the extracted subgoal theorem statements and the validated proof sketch. It produces an assembled proof by replacing each
sorryplaceholder with calls to the corresponding extracted subgoal theorem. The Verifier checks both the assembled proof and the subgoal statements together to confirm structural validity.
Subgoal Verification
Once the proof structure is validated, the system verifies the mathematical correctness and provability of the individual subgoals.
- Prover Attempts: The Prover attempts to solve each subgoal directly, generating \(K_{\text{formal proof}} = 4\) candidate proofs. Valid proofs are accepted.
- Correctness Verification: For subgoals the Prover cannot solve, the Reasoner evaluates whether the subgoal is mathematically correct, properly formulated, and provable. If identified as incorrect or unprovable, the subgoal is flagged, and the system returns to the proof sketch generation step, incorporating the identified issues as feedback.
- Shallow Solve: For subgoals that pass correctness verification but fail Prover attempts, the Reasoner attempts a “shallow solve”. After retrieving relevant Mathlib theorems, the Reasoner writes a short formal proof. It refines the proof using Verifier feedback for up to \(K_{\text{proof correction}} = 6\) passes. The step terminates early if an incorrect proof exceeds \(K_{\text{max shallow solve length}} = 30\) lines. The shallow solve process repeats for up to \(K_{\text{informal passes}} = 6\) attempts.
- Recursive Decomposition and Proof Assembly: Subgoals remaining unproven after the previous steps undergo recursive subgoal decomposition. Each subgoal is subdivided until it is proven or the process reaches the maximum recursion depth \(D\). If all subgoals are proven, the system concatenates the subgoal proofs with the assembled proof outline to yield the complete proof. If any subgoals remain unsolved, the current proof attempt fails, prompting a restart of the decomposition process for the parent theorem.
Experiments
The system is evaluated on two formal mathematical reasoning benchmarks: MiniF2F and PutnamBench. In all experiments, the maximum recursion depth is set to \(D = 5\).
Main Results
MiniF2F: The test split of MiniF2F contains 244 high-school mathematics competition problems. Performance is evaluated using combinations of formal Provers (DeepSeek-Prover-V2-7B, Goedel-Prover-V2-32B) and informal Reasoners (Gemini 2.5 Flash, Gemini 2.5 Pro, gpt-oss-120b).
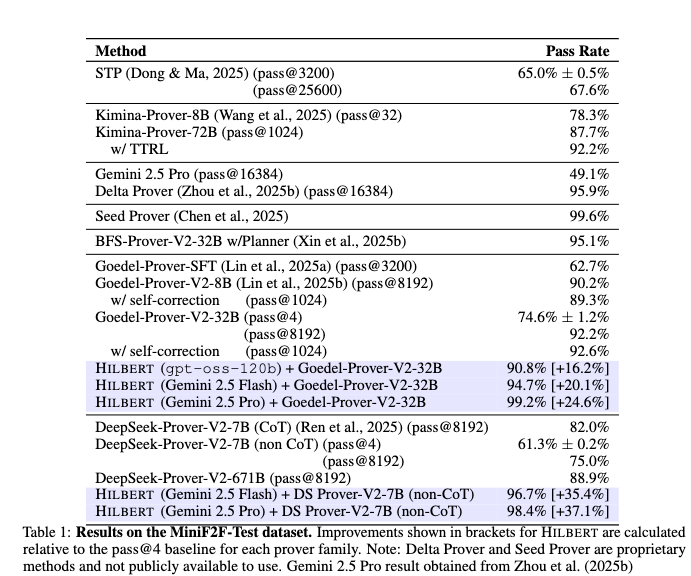
The configuration combining Gemini 2.5 Pro with Goedel-Prover-V2-32B achieves a 99.2% pass rate, failing on two problems. Combining DeepSeek-Prover-V2-7B with Gemini 2.5 Pro yields 98.4%, while pairing it with Gemini 2.5 Flash yields 96.7%. Using the open-weights model gpt-oss-120b alongside Goedel-Prover-V2-32B results in a 90.8% pass rate.
PutnamBench: This benchmark consists of 660 undergraduate-level problems from the William Lowell Putnam Mathematical Competition. The system was tested using the Goedel-Prover-V2-32B Prover.
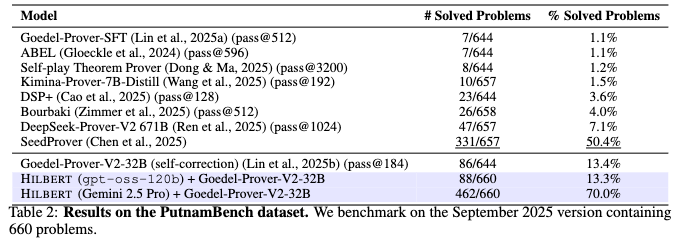
The configuration using Gemini 2.5 Pro solves 462 out of 660 problems (70.0% pass rate). The configuration using gpt-oss-120b solves 88 out of 660 problems (13.3%).
Scaling Behavior with Inference-Time Compute
The system adapts inference-time compute across multiple interconnected stages based on problem difficulty. Figure 3 plots the pass rate on MiniF2F as a function of the number of calls to the Reasoner and the total number of LLM calls (Reasoner + Prover).
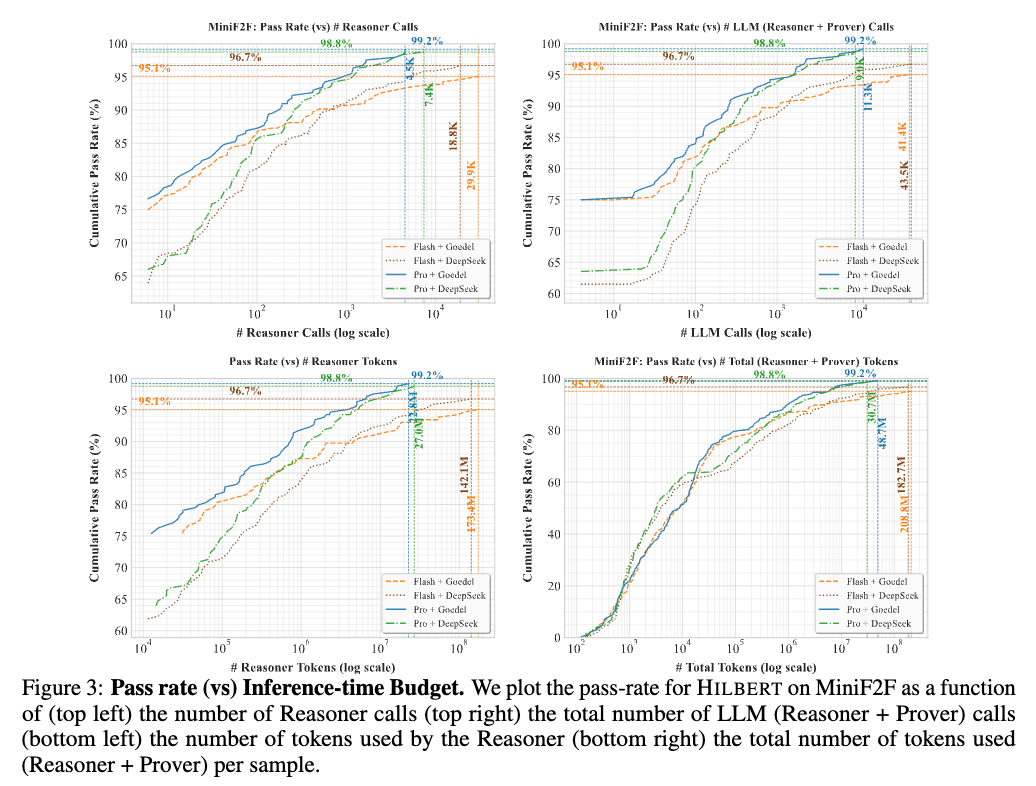
Pass rates scale continuously with the number of calls. The Gemini 2.5 Pro with Goedel Prover configuration reaches its peak pass rate utilizing a maximum of 4.5K Reasoner calls and 11.3K total LLM calls per sample. Models with weaker Reasoners (Gemini 2.5 Flash) require higher inference budgets to reach their respective peak pass rates. Token consumption increases in tandem with pass rate improvements; on MiniF2F, the most challenging problems consume up to 27.0M tokens for the Gemini 2.5 Pro + DeepSeek-Prover-V2 configuration.
Ablation Studies
Performance vs Depth: The effect of the recursive depth \(D\) on subgoal decomposition is evaluated on MiniF2F using Gemini 2.5 Pro and Goedel-Prover-V2-32B. A baseline of \(D=0\) (standalone Prover at pass@4) achieves a 75% pass rate.
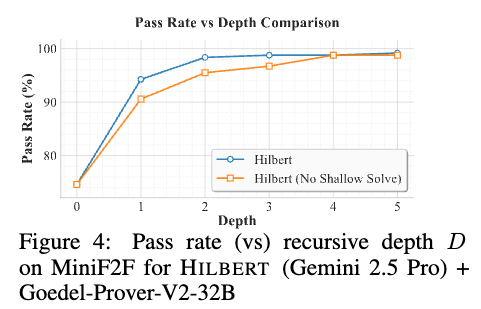
Performance increases monotonically with depth. The full system reaches a 98.36% pass rate at \(D=2\) and 98.7% at \(D=3\). An ablated version with the shallow solve mechanism disabled (\(K_{\text{informal passes}} = 0\)) requires a greater recursion depth to reach comparable performance.
Retrieval Ablation: The impact of the Retriever component is tested by comparing the full system against a variant without retrieval.

Including retrieval increases the pass rate and decreases inference-time compute utilization. For the DeepSeek-Prover-V2-7B configuration, retrieval increases the pass rate from 97.1% to 98.4%, reduces average Reasoner calls per problem from 426 to 420, and lowers average Reasoner tokens from 2.1M to 1.9M. For the Goedel-Prover-V2-32B configuration, retrieval increases the pass rate from 97.9% to 99.2%, while decreasing average Reasoner calls from 862 to 548 and average Reasoner tokens from 4.0M to 2.3M.