Dream 7B Diffusion Large Language Models
Dream 7B is a 7-billion parameter diffusion language model that refines text in parallel, initialized from an autoregressive model and trained using context-adaptive noise scheduling.
Read Paper →Standard diffusion models corrupt an input sequence by masking some tokens with noise. The model is then trained to predict the original tokens at the masked positions, effectively denoising the sequence.
The authors of Dream 7B modify this process. Instead of predicting a masked token at its own position, the model uses the hidden state from the previous position (i) to predict the original token for the next position (i+1). This shift allows the model to be initialized with weights from a pretrained autoregressive (causal) decoder.
Method
The method for Dream 7B is based on discrete diffusion modeling with two primary modifications to the training process: initialization from a pre-trained autoregressive model and a context-adaptive noise scheduling mechanism.
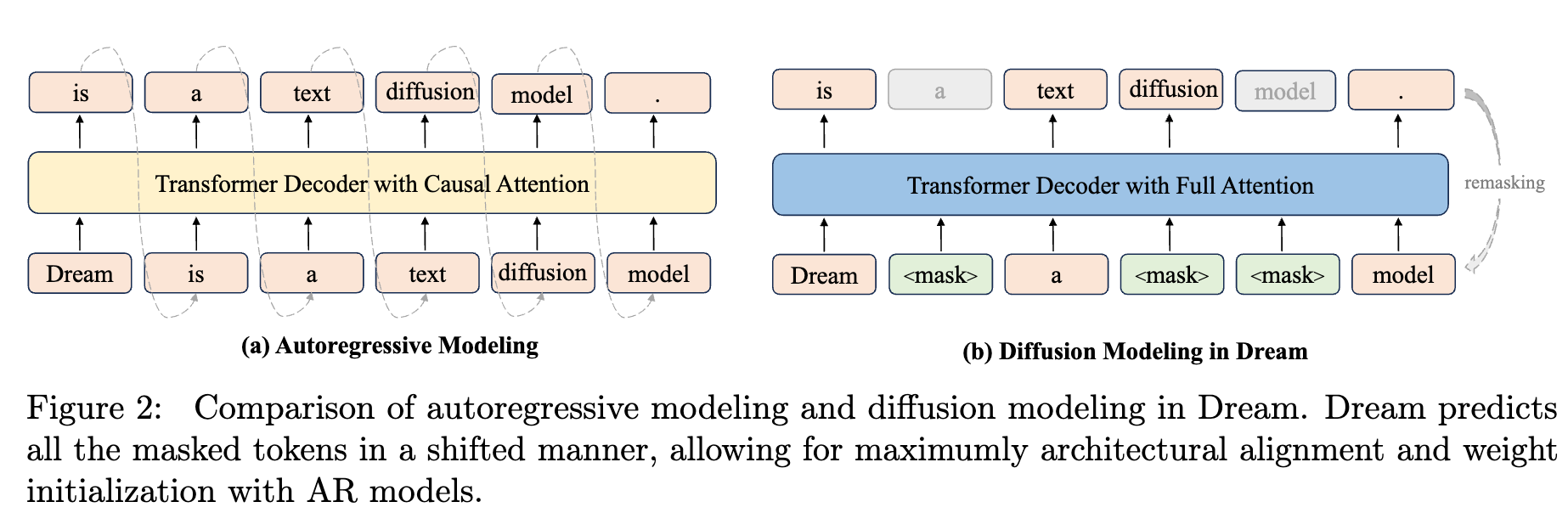
AR-based LLM Initialization
The model is initialized with weights from a pre-trained autoregressive (AR) model. To accommodate the architectural patterns of AR models, a “Shift Operation” is adopted. In this operation, the hidden state at position \(i\), denoted \(h_i\), is used to predict the token at position \(i+1\). This preserves the positional prediction mechanism learned by the AR model during its original training. The objective is to align the diffusion training process with the existing representations within the pre-trained weights, rather than learning sequence representations from scratch.
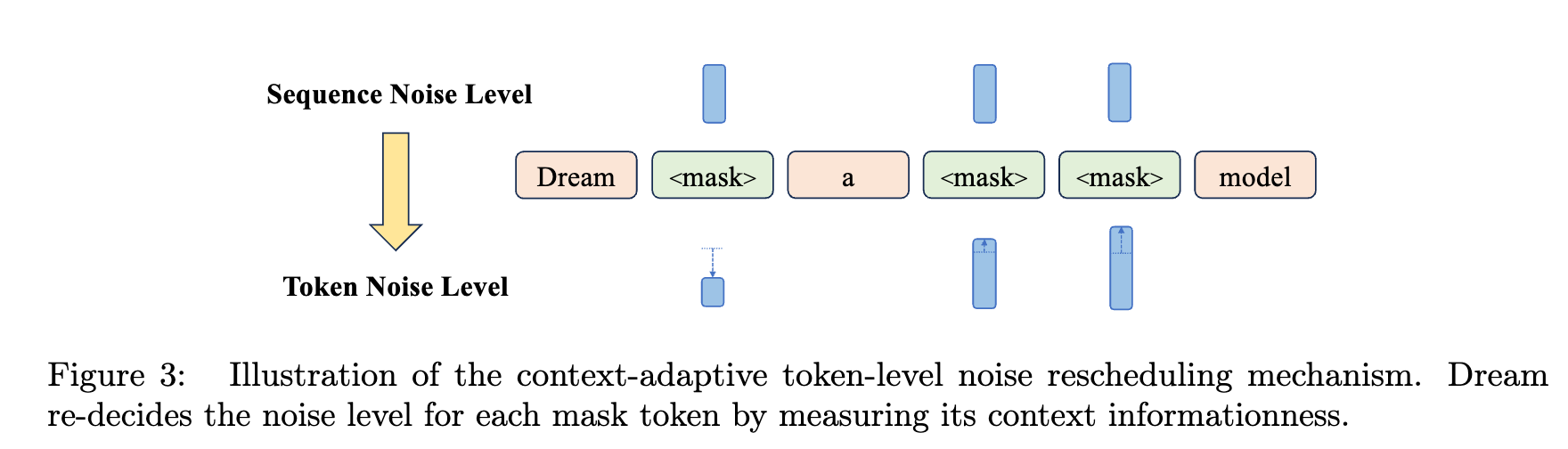
Context-Adaptive Token-Level Noise Rescheduling
Standard diffusion training applies a uniform noise level across all tokens in a sequence for a given timestep. To account for varying contextual dependencies of individual tokens, a technique named Context-Adaptive noise Rescheduling at Token-level (CART) is introduced. CART moves from sequence-level to token-level noise scheduling by assigning noise levels to each token based on its context. This allows the model to differentiate between tokens with rich context and those with sparse context.
The training objective with CART is formulated as:
\[L(\theta) = -\mathbb{E}_{x_0 \sim q(x), t \sim U(0,1), x_t \sim q(x_t \mid x_0)} \sum_{n=1}^{N} \mathbf{1}[x_t^n=\text{MASK}] w(t, x_t, n) \log p_\theta(x_0^n \mid x_t)\]\(\mathbf{1}[x_t^n=\text{MASK}]\) means we only calculate loss for masked tokens. \(x_0\) is the original sequence (without noise). \(x_t\) is the noisy version. \(p_\theta(x_0^n \mid x_t)\) measures the model prediction of the original token given the noisy input \(x_t\). The weighting term \(w(t, x_t, n)\) is a generalized function that can be designed to reflect contextual information. The implementation uses a mixture of geometric distributions to measure the information contribution from each unmasked token to a given masked token:
\[w(t, x_t, n) = \sum_{i=1}^{N} \mathbf{1}[x_t^i \neq \text{MASK}] \text{Geo}(p, \mid n-i\mid-1)\]Here, \(p \in (0, 1)\) controls the sharpness of the distribution, determining the influence of nearby versus distant unmasked tokens.
Masking in detail
They choose a random variable \(t\) uniformly from \([0, 1]\) and then mask each token randomly with probability \(t\). When they want to add noise they replace that token with [MASK] token.
Training
Model Architecture: Dream 7B uses a Transformer architecture with the same model configuration as Qwen2.5-7B.
Pretraining: The model is pre-trained to model the data distribution \(p_\theta(x_0)\) by optimizing the weighted cross-entropy objective using stochastic gradient descent. The training corpus consists of 580 billion tokens of text, mathematics, and code from open-source datasets including Dolma v1.7, OpenCoder, and DCLM-Baseline.
Supervised Fine-Tuning: For instruction following, the model is fine-tuned to model the conditional distribution \(p_\theta(r_0\mid p_0)\), where \(p_0\) is the prompt and \(r_0\) is the response. During this stage, noise is applied only to the response tokens. The fine-tuning dataset contains 1.8 million instruction-response pairs from Tulu 3 and SmolLM 2.
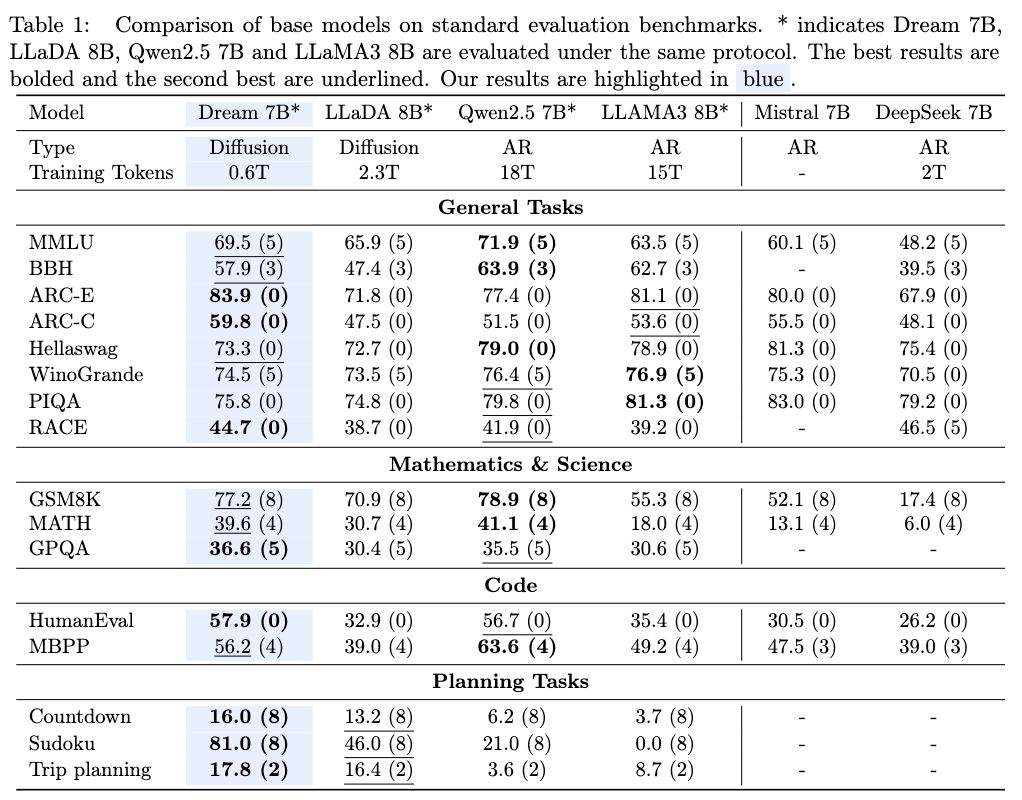
Results of Dream-Base
Results of Dream-Instruct
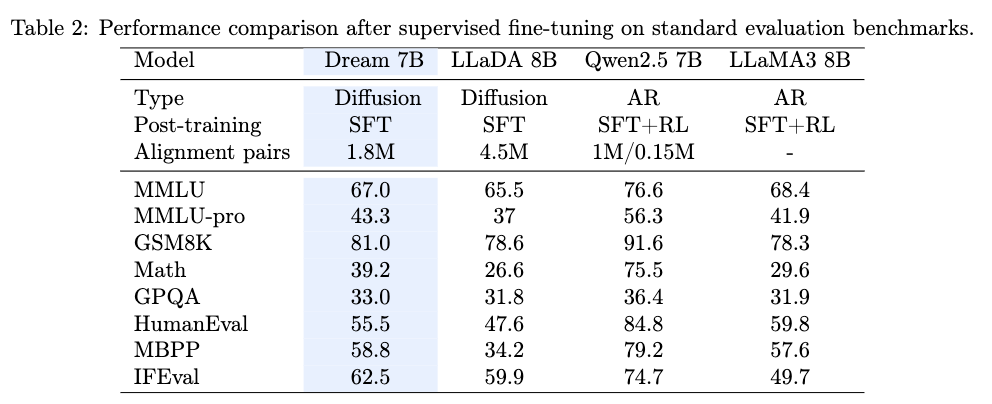
After supervised fine-tuning on 1.8M instruction-response pairs for 3 epochs, the resulting model, Dream-Instruct, demonstrates that diffusion language models can achieve performance comparable to AR-based models on instruction-following tasks.
Effect of AR Initialization
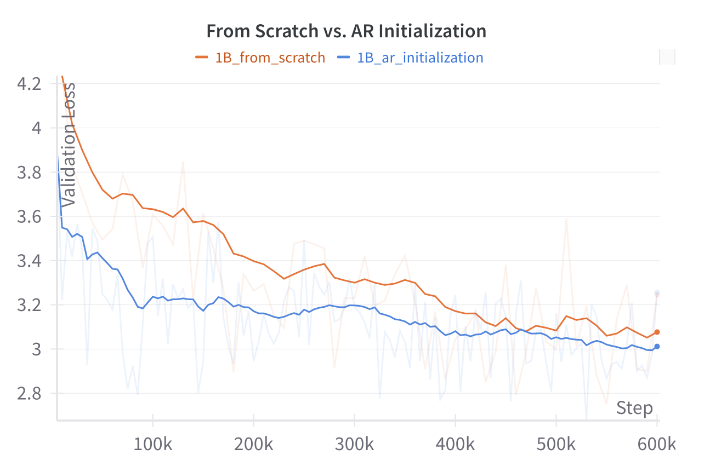
Experiments adapting a 1B parameter model from LLaMA3.2-1B show that AR initialization leads to lower validation loss in the early stages of training compared to training from scratch. The learning rate was found to be a critical parameter to calibrate to retain the benefits of the pre-trained weights while learning the diffusion process.
Arbitrary Order Generation
Dream 7B supports flexible generation orders without specialized training, unlike fixed left-to-right AR models. These capabilities include:
- Completion: Continuing a given piece of text.
- Infilling: Filling in missing segments within a text, with or without constraints on the ending.
- Configurable decoding order: Adjusting decoding hyperparameters allows for generation that can range from structured left-to-right to partially or fully random-order synthesis.