CriticLean Critic-Guided Reinforcement Learning for Mathematical Formalization
A reinforcement learning framework that explicitly trains a critic model to evaluate and improve the semantic fidelity of natural language to Lean 4 mathematical formalizations.
Read Paper →Method
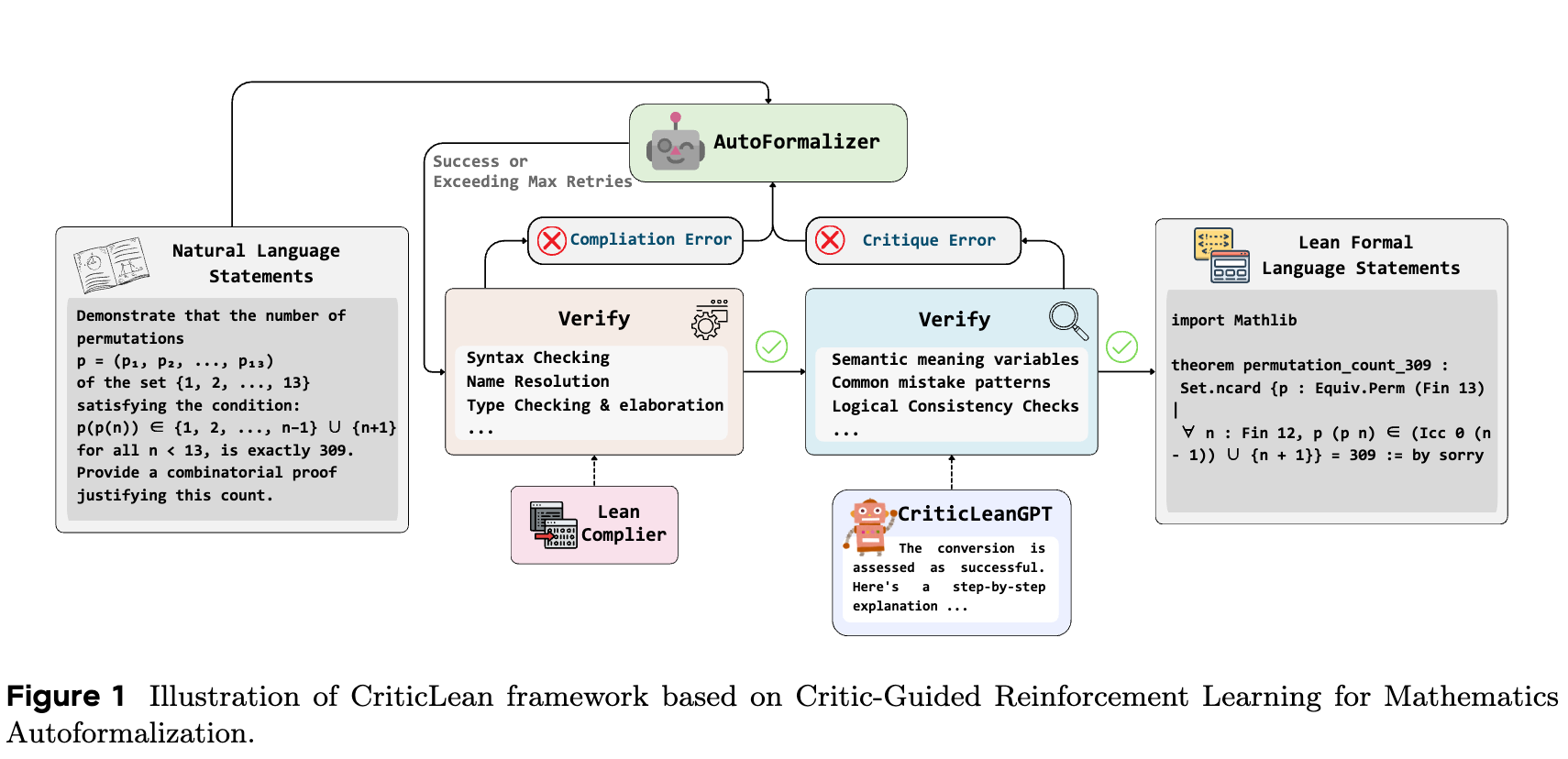
The CriticLean framework treats the evaluation of semantic correctness as an active component in the mathematical formalization pipeline. It utilizes an iterative process where natural language statements are translated into Lean 4 code, guided by feedback from the Lean compiler and a trained critic model (CriticLeanGPT). The critic assesses whether the generated formalization accurately preserves the semantic intent of the original mathematical statement or not.
CriticLeanBench
To evaluate the reasoning and critique capabilities of Large Language Models (LLMs) in formalization tasks, CriticLeanBench provides a dataset of 500 natural language and Lean 4 statement pairs. The dataset consists of 250 semantically correct pairs and 250 incorrect pairs.
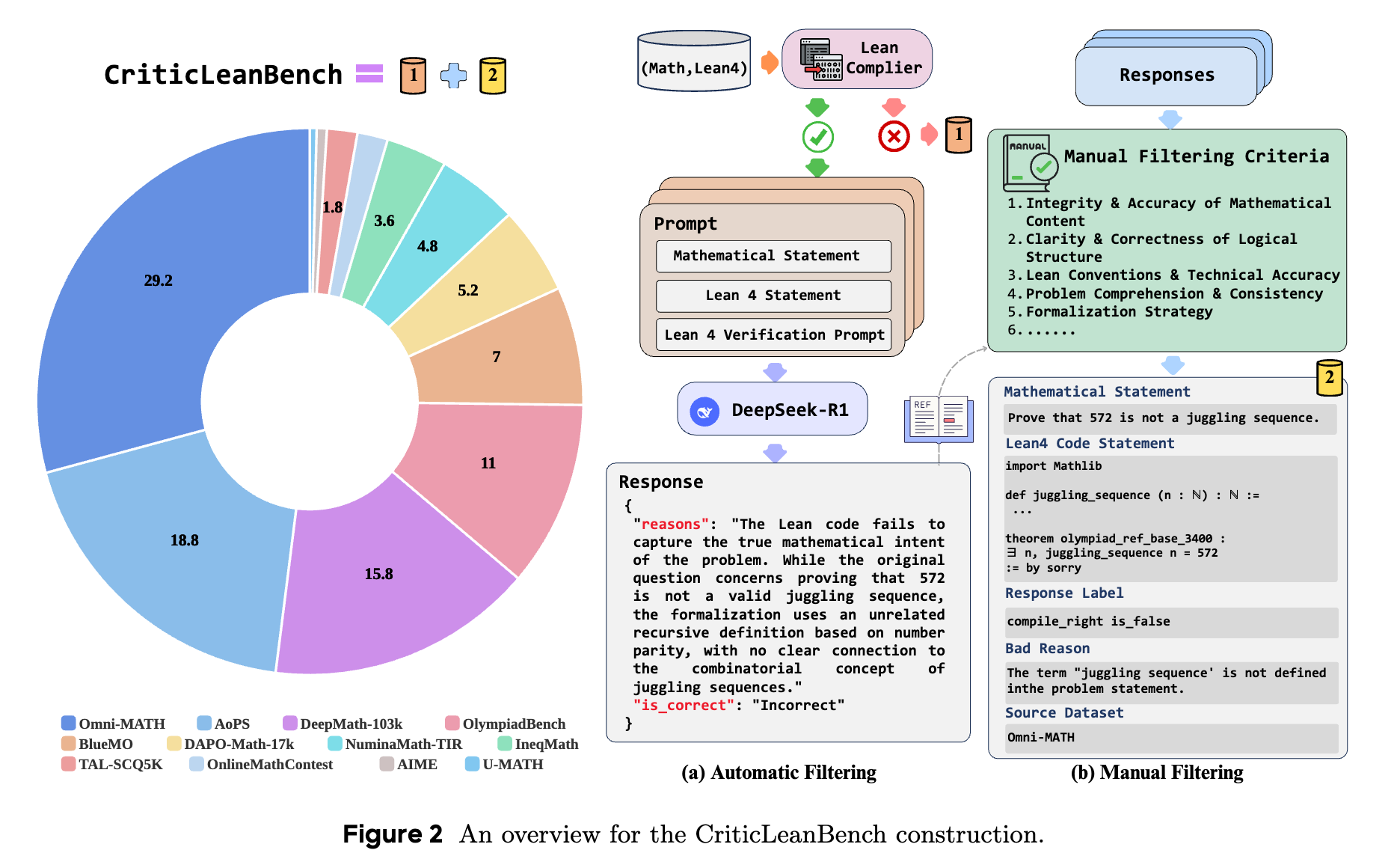
The benchmark construction involves compiling candidate Lean 4 statements. Statements that fail compilation are sampled to represent compiler feedback scenarios. Compiled statements are passed through a validation filter using a prompt template and an LLM to categorize them into semantically consistent (correct) and inconsistent (incorrect) groups. Human validation is then applied to ensure the correct subset accurately reflects the original problem semantics and the incorrect subset captures representative translation errors (e.g., premise translation errors, goal translation errors, and logical structure mismatches).
CriticLeanInstruct Dataset
CriticLeanGPT models are trained on CriticLeanInstruct, a dataset containing 48,000 samples. The dataset construction includes:
- Seed Data: 4,000 samples (2,000 correct, 2,000 incorrect) equipped with chain-of-thought (CoT) explanations detailing the presence or absence of errors. Incorrect samples incorporate Lean 4 compiler error messages.
- Data Augmentation:
- Correct pairs are sourced from the FormalMATH dataset and verified using an LLM to generate evaluation reasoning.
- Incorrect pairs are generated via two methods: preserving formalizations that fail compilation during autoformalization processes, and synthetically injecting contextually relevant semantic errors into correct FormalMATH samples using an established error taxonomy.
Training Paradigm
CriticLeanGPT variants are developed using the Qwen2.5 and Qwen3 architectures.
Supervised Fine-Tuning (SFT) The base checkpoints undergo instruction tuning on the CriticLeanInstruct dataset. The training mixture includes the mathematical formalization critique data combined with supplementary code and mathematics datasets at a 1:3 ratio.
Reinforcement Learning (RL) Optimization Further refinement is conducted using rule-based online reinforcement learning, specifically the Group Relative Policy Optimization (GRPO) algorithm. The optimization objective is:
\[J_{\text{online}}(\pi_\theta; \mathcal{D}) = \mathbb{E}_{x \sim \mathcal{D}, \{y_i\}_{i=1}^G \sim \pi_{\theta_{\text{old}}}(y|x)} \left[ \frac{1}{G} \sum_{i=1}^G \min \left( \frac{\pi_\theta(y_i|x)}{\pi_{\theta_{\text{old}}}(y_i|x)} A_i, \text{clip}\left(\frac{\pi_\theta(y_i|x)}{\pi_{\theta_{\text{old}}}(y_i|x)}, 1 - \epsilon, 1 + \epsilon\right) A_i \right) - \beta D_{\text{KL}}(\pi_\theta || \pi_{\text{ref}}) \right]\]where \(G\) is the group size and \(A_i\) is the advantage. The model receives discrete rewards based on format adherence and judgement consistency against ground-truth labels. The reward functions are:
\[r_{\text{accuracy}} = \begin{cases} 1, & \text{if judgement = label} \\ 0, & \text{if judgement} \neq \text{label} \end{cases}\] \[r_{\text{format}} = \begin{cases} 1, & \text{if format is right} \\ 0, & \text{if format is wrong} \end{cases}\] \[r_{\text{final}} = \min(r_{\text{accuracy}}, r_{\text{format}})\]FineLeanCorpus
The CriticLean pipeline is used to process a heterogeneous collection of math problems (from olympiads, high school curricula, and undergraduate levels) into the FineLeanCorpus. This dataset comprises 285,957 verified Lean 4 statement pairs. The corpus construction applies an iterative generation process gated by both Lean 4 syntactic compilation and CriticLeanGPT semantic validation. A subset named FineLeanCorpus-Diamond isolates 36,033 problems classified at a high difficulty level for advanced reasoning tasks.
Experiments
Experimental Setup
Evaluations are conducted on CriticLeanBench. The baseline models include closed-source APIs (Claude 3.5 Sonnet, Doubao-1.5-pro, Gemini 2.5 Pro, GPT-4o) and open-source models (DeepSeek-R1, QwQ-32B, Qwen3 variants, DeepSeek-Prover, Llama-3.3-70B-Instruct, and Qwen2.5 variants). CriticLeanGPT models consist of Qwen2.5 and Qwen3 variants tuned via SFT and RL.
Evaluation of Critic Capability
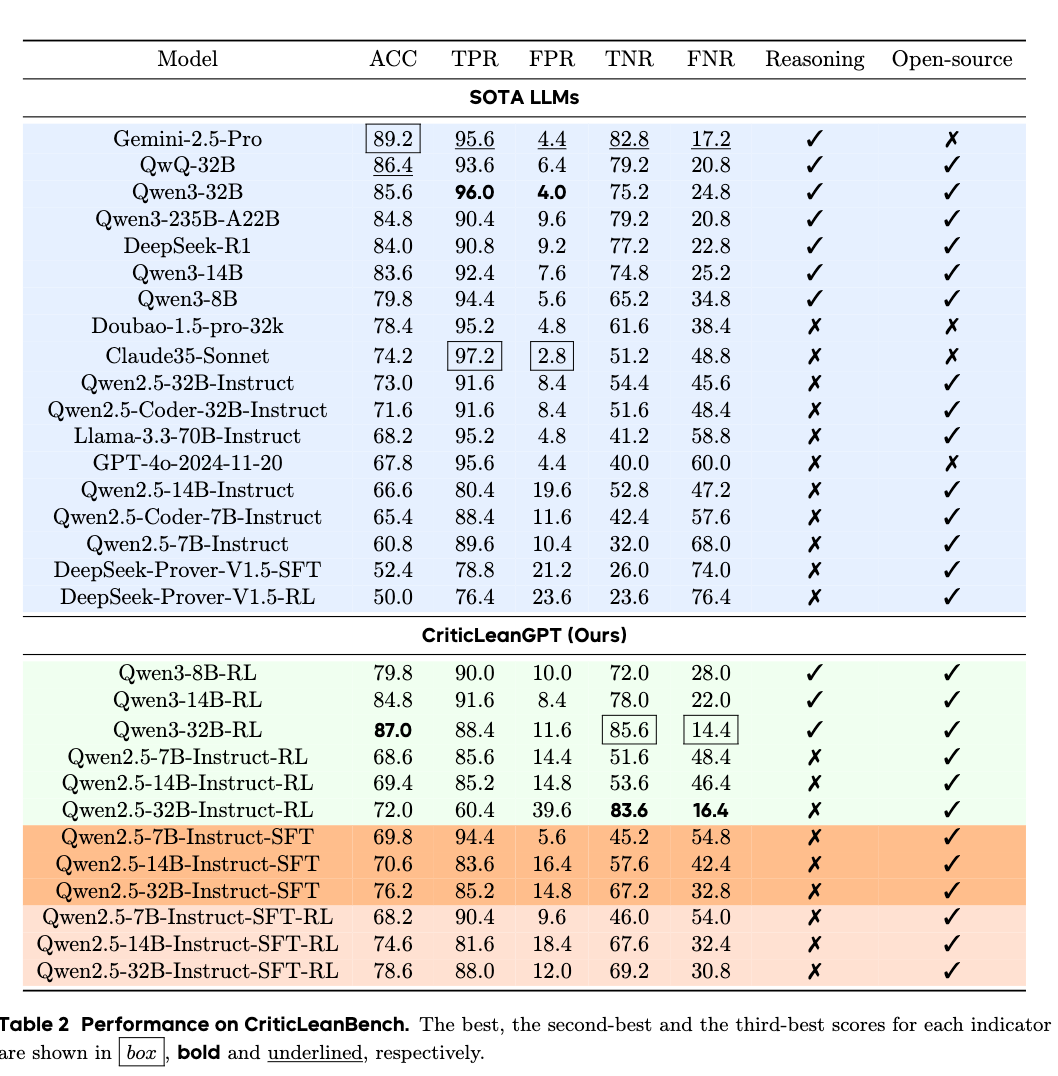
On the CriticLeanBench, reasoning-focused baseline models exhibit strong critical evaluation performance. CriticLeanGPT models optimized through RL (e.g., Qwen3-32B-RL) achieve higher True Negative Rates (TNR) and lower False Negative Rates (FNR) compared to base models, indicating an improved capability to identify incorrect mathematical formalizations.
Ablation Studies
Effect of Reasoning Data
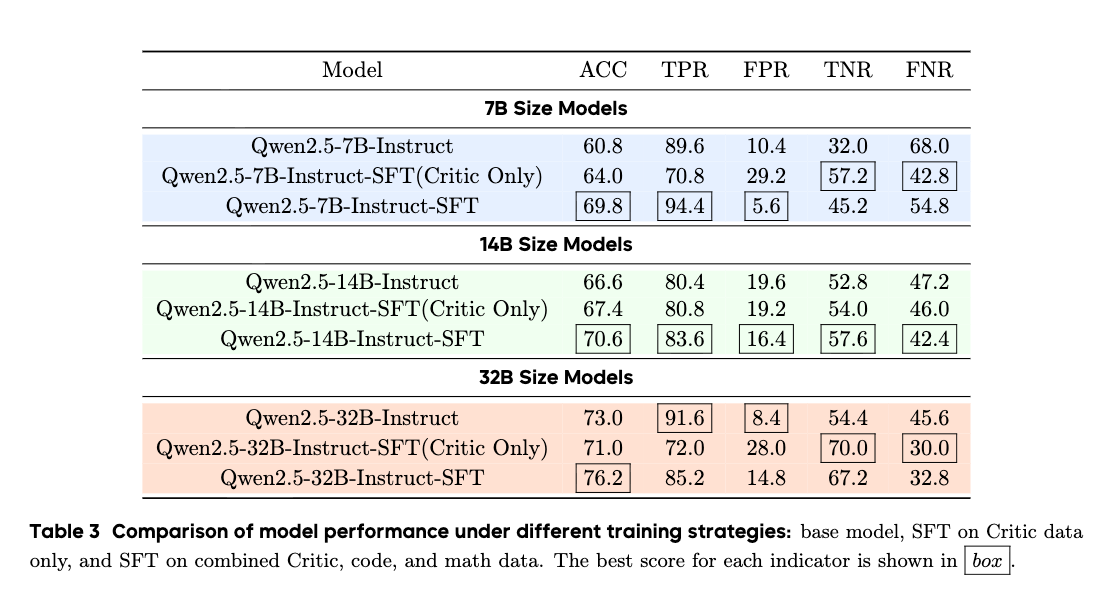
Integrating code and math reasoning data alongside critique-specific data improves evaluation metrics across 7B, 14B, and 32B model scales. The 1:3 data mixing strategy yields higher accuracy and TNR than training on the critique seed data alone.
Effect of SFT Dataset Size
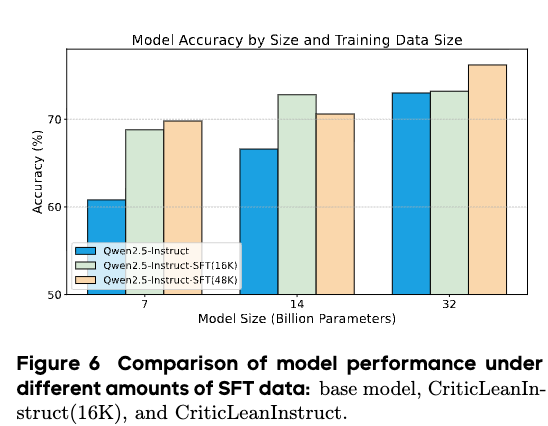
Scaling the size of the SFT dataset correlates with performance changes that depend on model parameter count. 7B parameter models display consistent gains as data volume increases. In 32B parameter models, lower data volumes yield marginal changes, whereas higher volumes lead to measurable improvements.
Effect of Pass@k Evaluation of models using the Pass@k metric (\(k=8\) and \(k=32\)) indicates that increasing the number of candidate responses improves performance metrics across tested models. SFT and RL optimization processes reduce the misclassification of incorrect samples compared to the base instruct models.
Analysis on CriticLean Pipeline

The autoformalization pipeline is assessed using a 50-problem sample set verified by manual inspection. Three strategies are compared using the same base generation model:
- Single Pass: Generates formalizations without validation loops (38.0% accuracy).
- Compiler Feedback: Regenerates formalizations upon Lean 4 compilation failure (54.0% accuracy).
- CriticLean Pipeline: Regenerates formalizations until they pass both compiler validation and the CriticLeanGPT semantic check (84.0% accuracy).
Increasing the attempt limit within the CriticLean pipeline from 1 to 200 attempts increases the cumulative yield of successfully formalized and verified problems from 12.6% to 52.8%.