Construction-Verification A Benchmark for Applied Mathematics in Lean 4
A Lean 4 evaluation framework and benchmark requiring explicit solution construction prior to logical verification.
Read Paper →This paper is suggested a dataset for numerical tasks on lean4. In each task you should write two lean4 code. One Construction lean4 code that solves the numerical task and one Verification lean4 code that shows the constuctor is correct.
Method
The framework establishes a two-stage formalization pattern in Lean 4 to evaluate problem-solving in applied mathematics. Instead of evaluating problems solely as existential propositions, the system enforces a construction-verification workflow. The agent must first explicitly define a solution structure and subsequently prove its correctness, preventing the use of non-constructive shortcuts.
The framework is structured around three primary constructive task categories:
Evaluation Problems Evaluation problems require the synthesis of an explicit solution (numerical or symbolic) derived from given parameters. For example, solving the quadratic optimization problem:
\[f(x) = \frac{1}{2} x^T A x - b^T x\]The formalization separates this into:
- Construction: An explicit function definition (
def) computes the solution term \(x(V)\) from parameters \(V\). The function signature strictly accepts only raw parameters as inputs, structurally preventing the model from using the target property or existence proofs to construct the solution. - Verification: A theorem proves that the constructed term satisfies the target property \(Q(x(V), V)\).
Algorithm Design Problems Algorithm design tasks evaluate the synthesis of iterative state-transition rules, such as gradient descent or Newton’s method. An algorithm is defined as a sequence generator \(A : \mathbb{N} \to S\) operating on a state space \(S\) with parameters \(V\):
\[A(0) = \text{init}(V)\] \[A(n+1) = \Phi(A(n), V)\]The agent is tasked with defining the transition function \(\Phi\) by completing the recursive loop body. Following construction, the agent must verify a property of the sequence \(P(A)\), such as monotonicity or convergence.
Representation Transformation This category tests the transformation of a non-standard source problem \(\mathcal{P}_{src} = (X, C, f)\) into a tractable target problem \(\mathcal{P}_{tgt} = (Y, C', f')\), such as a linear or semidefinite program. The relationship between problems is formalized via a relaxation relation \(\preceq\):
\[\forall x \in X, C(x) \implies \exists y \in Y, C'(y) \land f(x) = f'(y)\]The agent constructs the target domain, constraints, and objective function, and then formally verifies the logical proposition \(\mathcal{P}_{src} \preceq \mathcal{P}_{tgt}\) (or mutual equivalence).
Experiments
The evaluation utilizes the AMBER (Applied Mathematics Benchmark for Reasoning) dataset, comprising 200 problems across optimization, convex analysis, numerical algebra, and high-dimensional probability.
Setup and Metrics The experiments compare general-purpose reasoning models (DeepSeek-V3.2-Thinking, GPT-5.1, Gemini-3.0 Pro) and specialized theorem provers fine-tuned for formal mathematics (Goedel Prover-32B, Kimina Prover-72B). Model performance is measured using an unbiased estimator for Pass@\(k\) (with \(k=1, 2, 4, 8, 16\)).
\[\text{Pass}@k := \mathbb{E} \left[ 1 - \frac{\binom{n-c}{k}}{\binom{n}{k}} \right]\]For each problem, models must successfully compile both the constructive definition and the verification proof without errors.
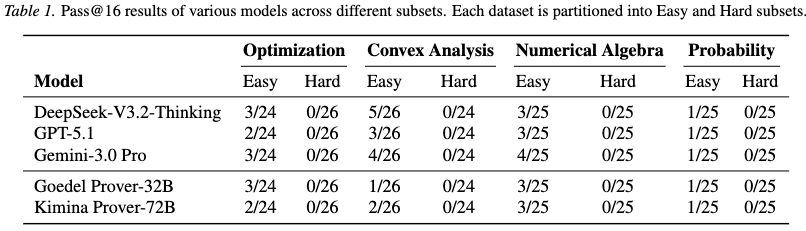
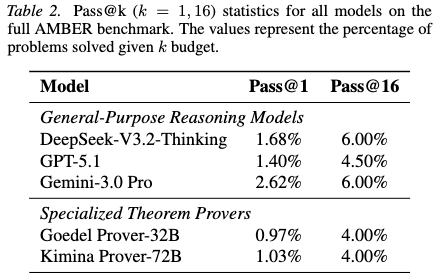
Results Overall pass rates across all models are lower than those observed on standard pure mathematics benchmarks.
General-purpose reasoning models consistently achieve higher pass rates than specialized mathematical provers. Specialized models exhibit an effect identified as “tactical overfitting.” While fine-tuning on proof corpora improves performance on standard deduction tasks, it reduces the instruction-following capabilities needed for multi-stage mathematical modeling. Specialized models frequently bypass the required definition block (def) and attempt to discharge construction goals using non-constructive proof tactics. General-purpose models retain the instruction-following skills necessary to adhere to the construction-verification template.
Ablation Study on Prompts An ablation study on a 100-problem subset from the optimization and convex analysis domains compared three prompting strategies: the proposed construction-verification structure, standard code completion, and traditional proof-only tasks.

The construction-verification prompt yielded the highest success rate (8/100). Standard completion resulted in 6/100, and traditional proof-only prompts dropped to 5/100. Without structural constraints, models frequently utilized non-constructive tactics (e.g., Classical.choice) to logically prove existence without providing the required computational solution.
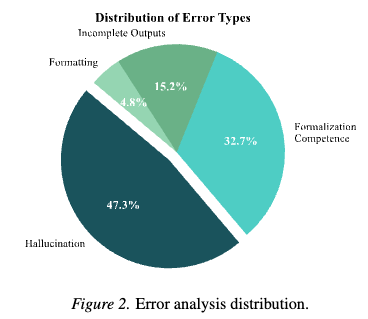
Error Analysis A manual classification of 3,189 error messages from the DeepSeek model identified four primary failure modes:
- Hallucination (47.3%): Invocation of non-existent theorems or definitions from the Lean 4 library.
- Formalization Competence (32.7%): Misapplication of valid theorems or failure to discharge necessary side-conditions for rewrite tactics.
- Incomplete Outputs (15.2%): Abandoning the proof of the inductive step and reverting to placeholders (
sorryorsubmit). - Formatting and Syntax (4.8%): Output formatting errors such as unclosed markdown blocks or syntactically malformed headers.