Chain of Images for Intuitively Reasoning
This paper proposes a Chain-of-Images (CoI) method for multimodal models to solve reasoning problems by generating a series of images as intermediate representations, using a Symbolic Multimodal Large Language Model (SyMLLM).
Read Paper →Method
The proposed method, named Symbolic Multimodal Large Language Model (SyMLLM), is designed to generate images step-by-step to assist in reasoning tasks. The system is composed of a Large Language Model (LLM), a symbol-to-image decoder, and an image encoder.
Instead of generating bitmap images directly, the LLM is prompted to produce symbolic representations in Scalable Vector Graphics (SVG) format. SVG is an XML-based format that can be losslessly converted into bitmap images. These generated images are then passed to an image encoder, and the resulting image embeddings are concatenated with text embeddings to predict the subsequent token.
This process allows the model to interleave text and image generation as intermediate steps in its reasoning chain.
For geometric problems, the LLM outputs SVG code that draws shapes based on textual descriptions. The output includes special comment tokens like <!--Image-->. When this token is generated, the SVG content up to that point is rendered into a pixel image and fed into the model’s image encoder. The model can then visually inspect the generated image to determine properties like the number of intersections.

For chess problems, the model uses SVG to define chess piece shapes, draw an 8x8 board, and place the pieces according to a given game state. Similar to the geometry task, an <!--Image--> token triggers the conversion of the current board state into an image, which is then used by the model to predict the next best move, such as a checkmate.

Experiments
The Chain of Images (CoI) approach was evaluated on three tasks: Geometry, Chess, and Commonsense reasoning.
Geometric Task
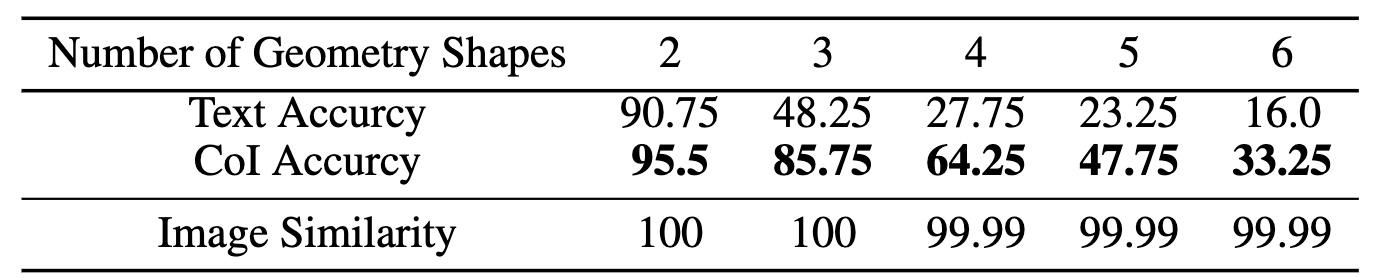
Task and Data: The evaluation used the “Intersect Geometric” task, which requires counting the intersection points among a set of geometric shapes (line segments, circles, polygons). The task has five difficulty levels, defined by the number of shapes (from 2 to 6). The evaluation set contained 1,000 examples for each difficulty level, and the training set contained 10,000 examples per level, with no overlap.
Model and Training: The model used was Vicuna-7B-v1.5 with a CLIP-ViT-L/14 image encoder. The LLM was trained using 4-bit quantization and a rank-16 LoRA. A text-only baseline model was trained with identical hyperparameters for comparison.
Results: The SyMLLM framework achieved nearly 100% image similarity, indicating high accuracy in converting coordinates to images. The model using CoI consistently outperformed the text-only baseline in counting intersection points. For problems with 4 shapes, accuracy increased from 27.75% to 64.25%. For problems with 6 shapes, accuracy increased from 16.0% to 33.25%.
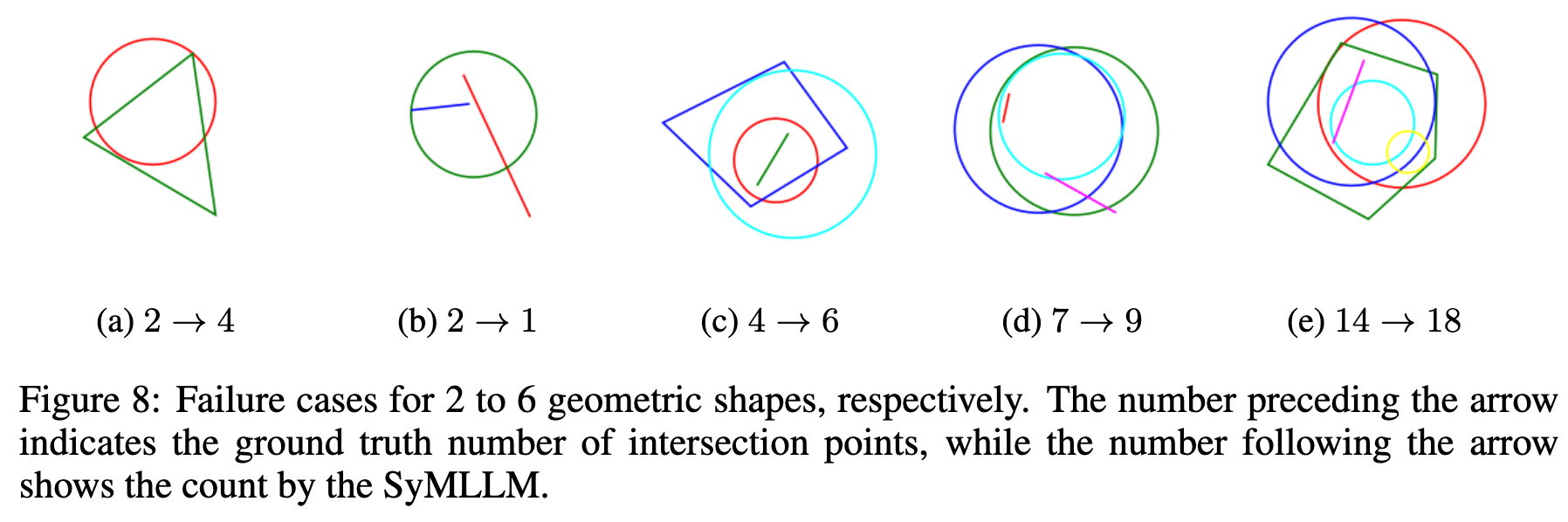
The failier case analysis shows that these failed cases are hard for human eyes as well.
Chess Task
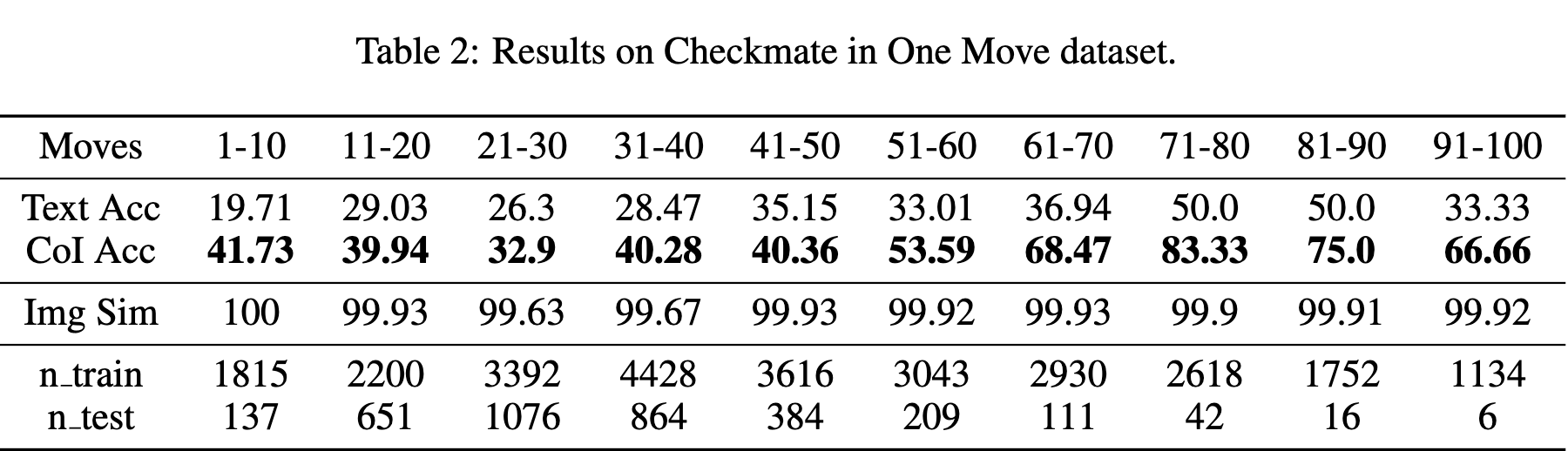
Task and Data: The model was evaluated on the “Checkmate in One Move” task. The goal is to identify the single move that results in a checkmate from a given board position. The validation data was grouped by the number of moves in the game. The training data was derived from games in Portable Game Notation (PGN) format, filtered for standard games ending in checkmate, and converted into the SVG format.
Model and Training: The model is an extension of ChessGPT (based on GPT-NeoX-3B) that incorporates a CLIP-ViT-L/14 image encoder. It was fine-tuned using 4-bit quantization and a rank-16 LoRA.
Results: The model achieved nearly 100% accuracy in generating the correct chessboard images. The CoI approach outperformed the text-only baseline across all game lengths. For games between 11-20 moves, accuracy improved from 29.03% to 39.94%. For games between 61-70 moves, accuracy improved from 36.94% to 68.47%. Performance generally improved as the number of moves increased, which corresponds to a smaller set of possible legal moves.
Commonsense Reasoning Task
Task and Data: Two tasks, “Location” and “Unusual,” were used for evaluation. Both tasks use a set of 531 event descriptions. The Location task asks for the event’s location, while the Unusual task asks what is strange about the event.
Model and Setup: Instead of training a new generative model, this experiment used existing models (SDXL and DALL-E 3) to generate images from the text descriptions. A pre-trained LLaVA-13B model was then used to reason about the generated images, prompted by “Let’s solve the problem with the help of an image.” The baseline was a text-only Vicuna-13B model.
Results: The use of images as an intermediate step improved performance on both tasks. For the Location task, accuracy increased from 73.63% (text-only) to 77.78% with SDXL images and 82.29% with DALL-E 3 images. For the Unusual task, accuracy increased from 90.4% to 100% when using images from either generator. The higher quality images from DALL-E 3 led to a larger performance gain in the Location task.
