Automatic Textbook Formalization
A multi-agent framework utilizing code-capable language models to translate and prove graduate-level mathematical textbooks in the Lean theorem prover.
Read Paper →Method
The formalization system treats proof construction as a software engineering task and uses a multi-agent scaffold based on a command-line interface. The system relies on standard collaborative software engineering practices, utilizing git for version control, a trunk-based development model with short-lived feature branches, continuous integration (CI), and a file-system-based issue tracker.
The pipeline isolates specific tasks by deploying concurrent sub-agents with well-defined roles:
- Sketcher agents: Process chunks of the source material (e.g., chapters) to generate Lean formalizations of definitions and theorem statements. Proofs are omitted using the
sorrykeyword. - Prover agents: Receive theorems containing
sorrystatements and attempt to construct complete Lean proofs. They can also directly resolve or escalate issues regarding missing helpers or incorrect statement formalizations. - Reviewer agents: Evaluate pull requests (PRs) submitted by sketcher and prover agents. Reviews are divided into a mathematical review (verifying semantic equivalence to the source text) and an engineering review (checking formatting, naming conventions, and API design). PRs require approval from both reviewers, a successful merge without conflicts, and a passing repository build.
- Maintainer agents: Process active files in the issue tracker to unblock formalization paths, often refactoring code or writing helper lemmas.
- Triage agents: Assess open issues to determine if they have been resolved by other PRs and mark them accordingly.
- Scan and Progress agents: Monitor the repository for global engineering issues (e.g., code duplication, mismatched conventions) and track the completion status of the designated target theorems.
Agents are granted access to predefined tools:
- File tools: Functions to read chunks, edit via line numbers or search-and-replace, and list files.
- Lean tools: Snippet execution using the Lean REPL,
mathlibfile/declaration search, andgreputilities. - Git tools: Restricted version control commands (
status,add,commit,rebase,diff) limiting write access to an agent’s specific branch. - Bash tool: An allowed list of shell commands for text processing (
cat,awk,grep) and Lean compilation (lake). - Issue tracker tools: Utilities to create and list issues using UUIDs.
Experiments
The system was evaluated on a 500-page graduate-level algebraic combinatorics textbook. The source text was selected due to its conceptual reliance on, but lack of direct inclusion in, Lean’s mathlib. To quantify completion, 340 specific theorems and definitions were manually labeled as targets.
The experiment ran on eight machines distributing the build processes, with git status synchronized via a shared Network File System (NFS) directory.
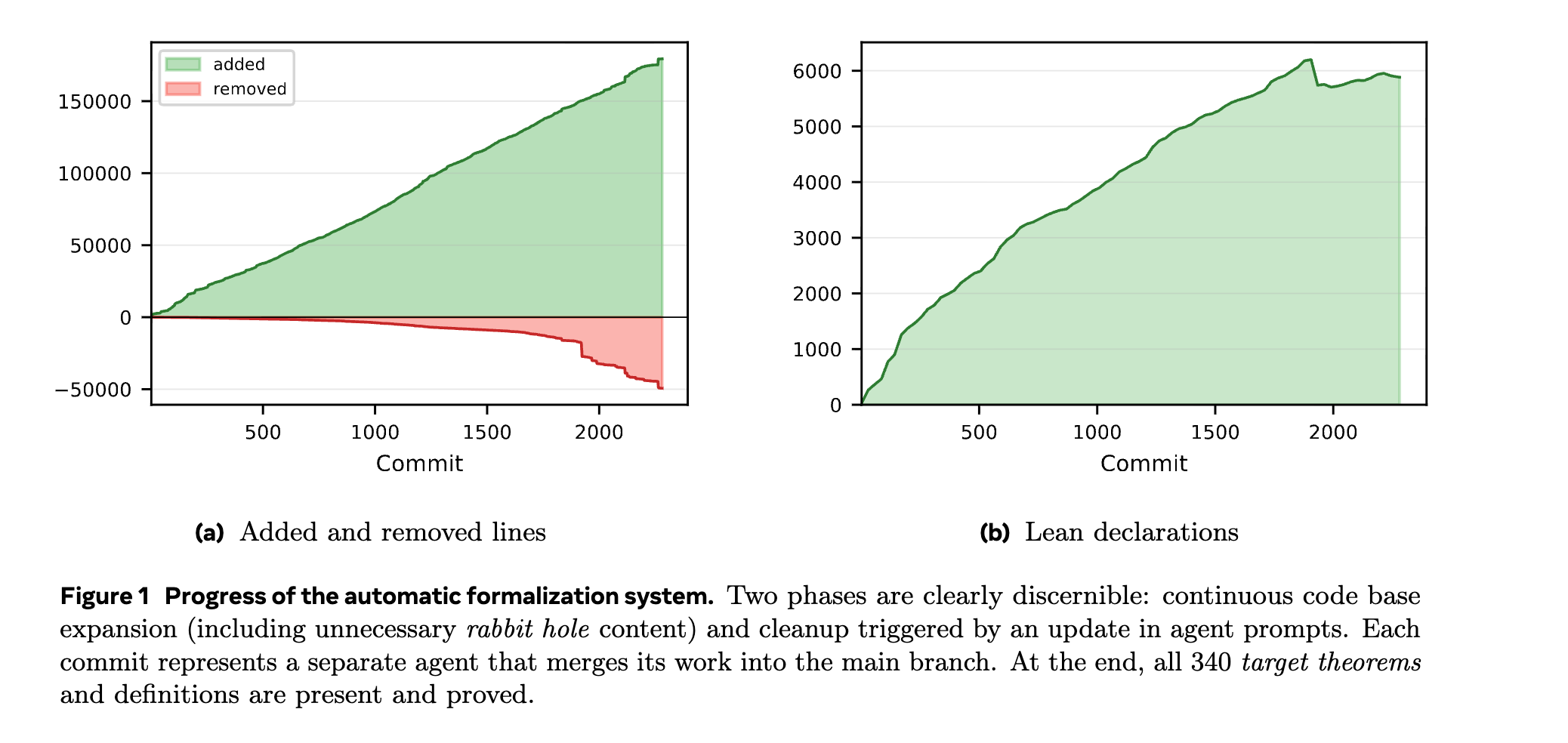
Results and Volume The formalization resolved all 340 target theorems and definitions over a runtime of one week. The final output consisted of roughly 130,000 lines of Lean code and 5,900 Lean declarations.

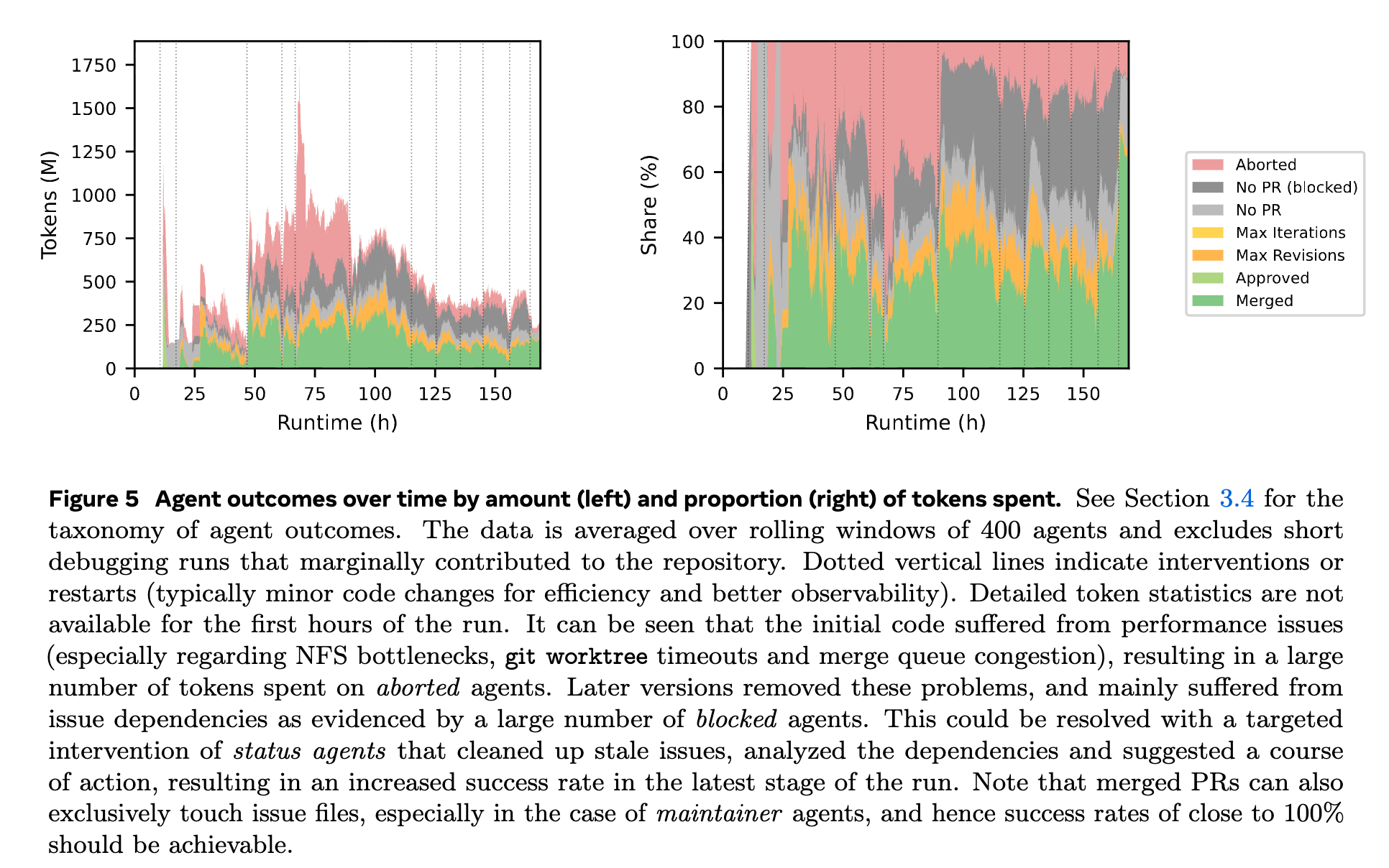
Agent Execution and Outcomes The orchestration utilized approximately 30,000 agents. Execution tokens totaled 83 billion for input and 561 million for output.
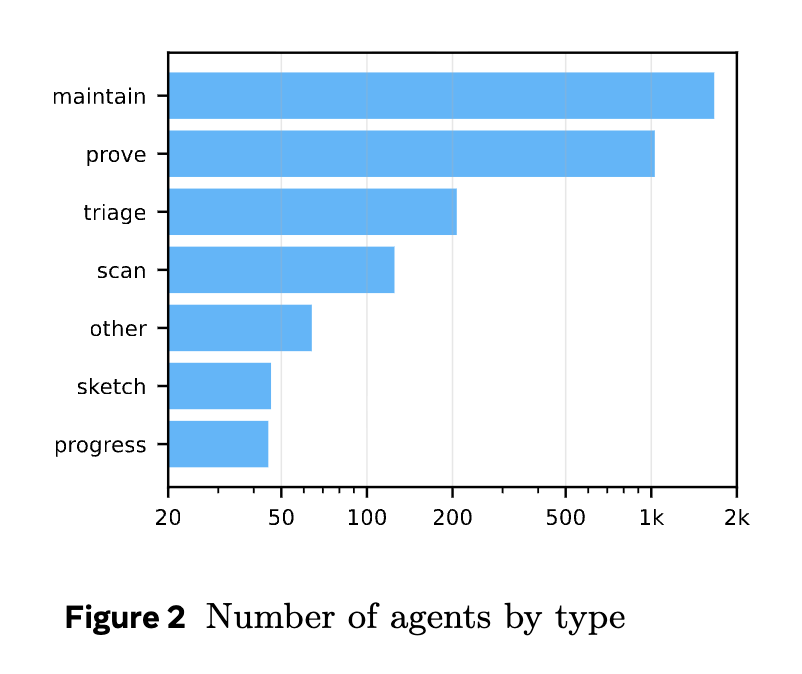
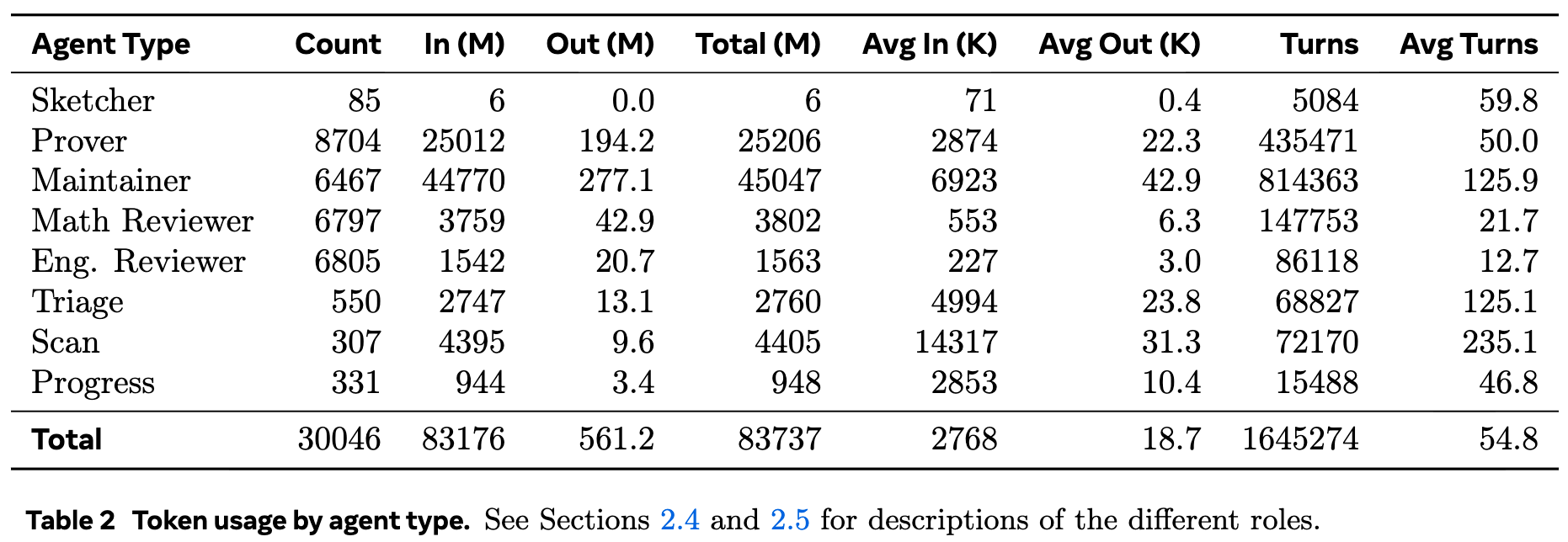
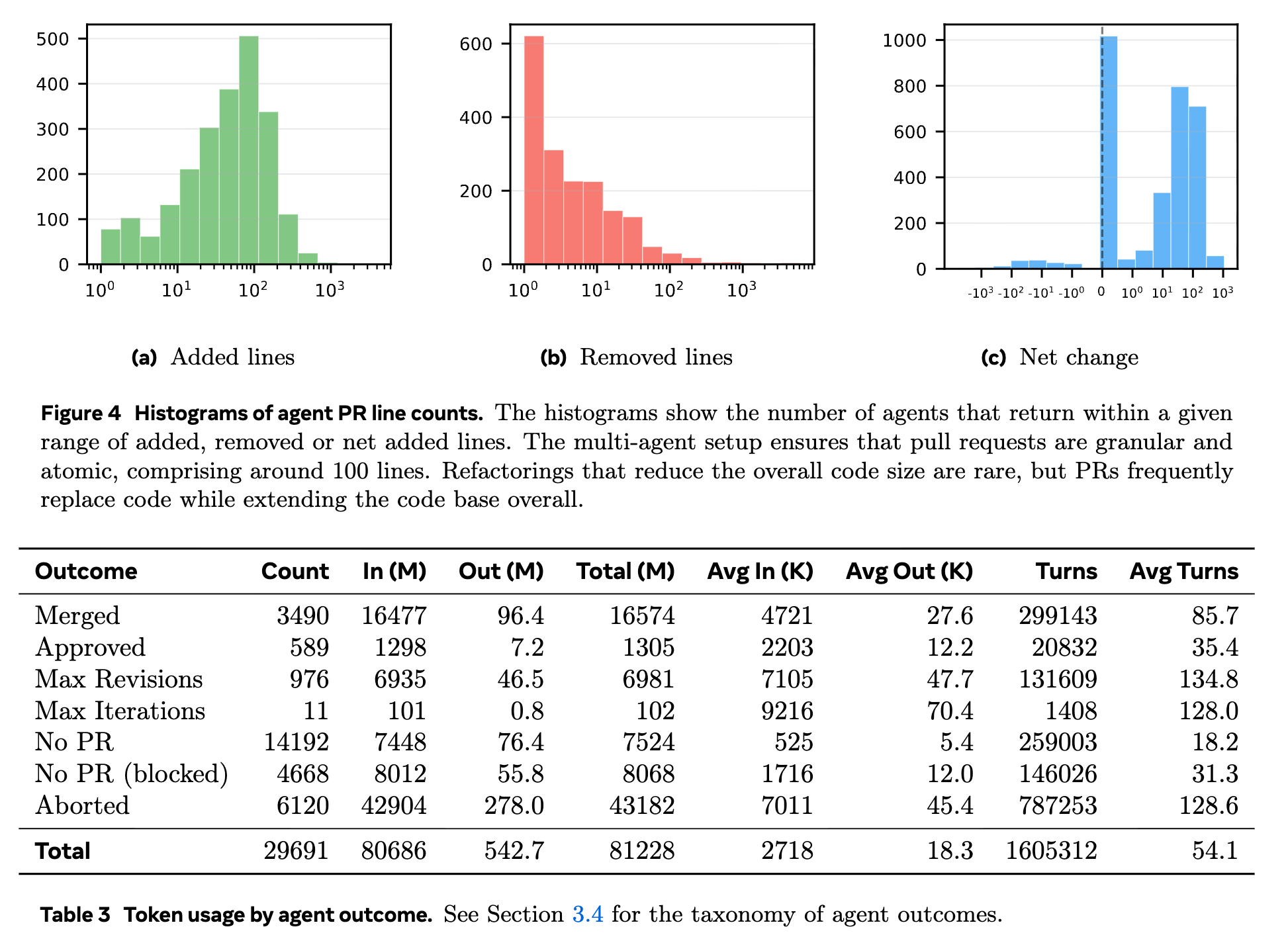
Of the executed agents, Provers and Maintainers accounted for the majority of actions and token consumption. Agents modifying files submitted PRs that were constrained in size, generally hovering around 100 net lines of code.
Cost Estimation Calculation Total compute costs were modeled using prompt caching parameters. Assuming \(N\) agents, \(T\) average turns per agent, \(m\) average token length per turn, and \(C\) total tokens processed in inputs:
\[C = Nm \sum_{i=1}^{T} i = Nm \frac{T(T + 1)}{2}\] \[m = \frac{2C}{NT(T + 1)}\] \[L = Tm = \frac{2C}{N(T + 1)}\]Using this cache ratio, the estimated inference cost for the entire textbook completion was approximately $100,000.
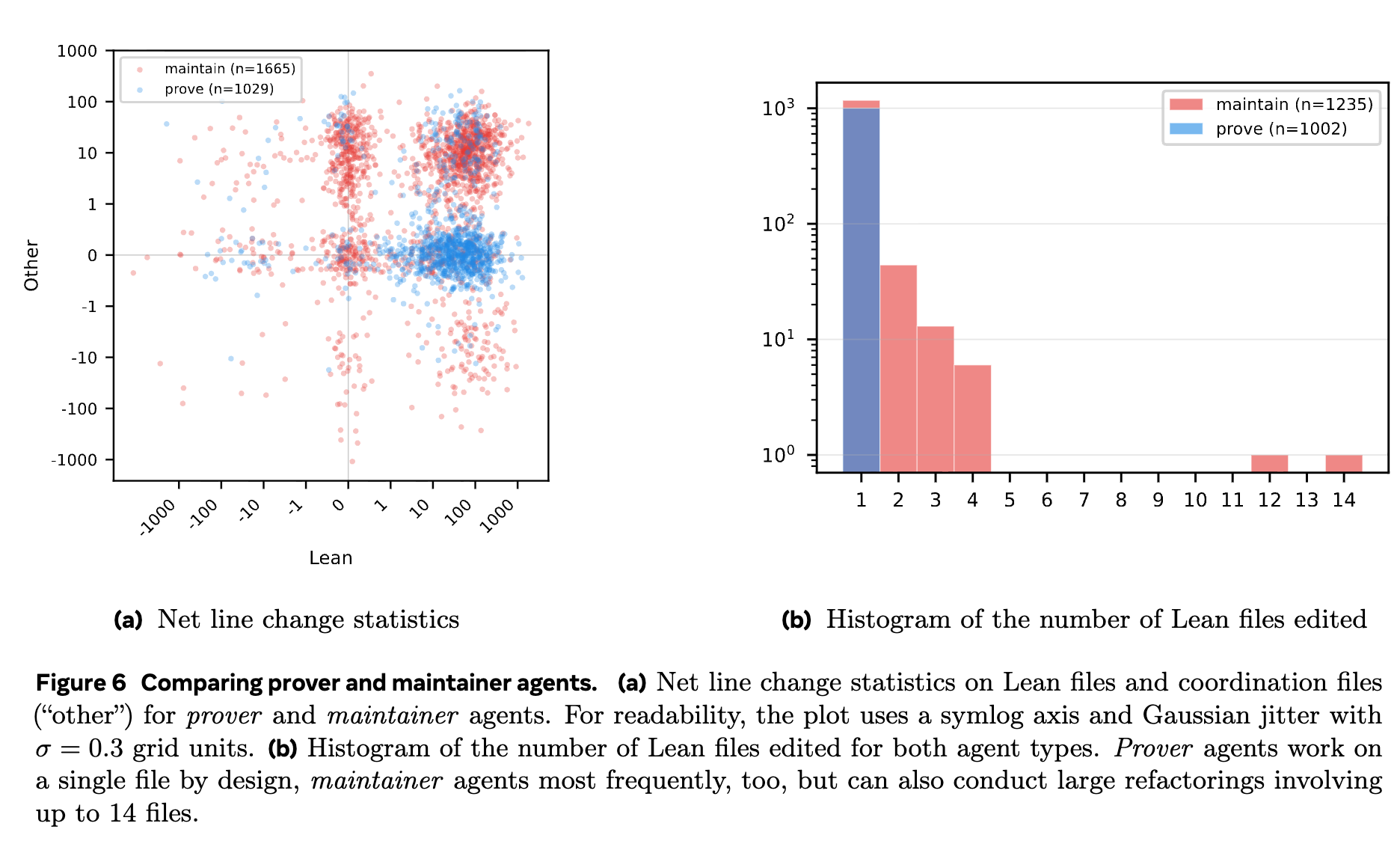
System Dynamics and Failures While Prover agents exclusively modified isolated Lean files, Maintainer agents executed repository-wide tasks impacting up to 14 files concurrently.
During execution, specific coherence and process failures were observed:
- Semantic Duplication: An \(N\)-partition data type was defined three separate times by different agents, requiring later refactoring to build a shared definition and prove equivalence between APIs.
- Mathematical Inconsistencies: Formalizations of informal combinatorial definitions (e.g., Bender-Knuth involutions) yielded competing definitions that failed on global proofs, causing Prover agents to identify counterexamples but fail to implement a root-cause refactor.
- Task Derailment: Agents occasionally ignored directives and initiated extensive proofs for standard cited theorems (e.g., constructing Pfaffians for domino tilings) instead of relying on external references.
- Infrastructure Bottlenecks: The shared NFS directory and the single-threaded merge queue produced timeouts and high resource contention during peak parallelization.