Autoformalizer with Tool Feedback
A framework that improves autoformalization by integrating syntactic compiler feedback and semantic consistency checks during the generation process.
Read Paper →Method
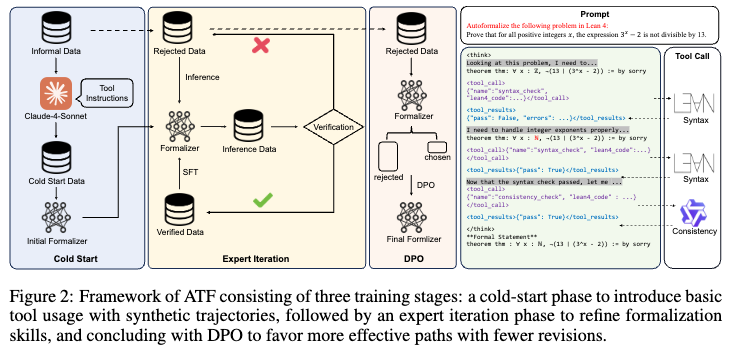
The Autoformalizer with Tool Feedback (ATF) incorporates syntactic and semantic consistency information as tools during the formalization process. The model adaptively refines generated formal statements based on feedback from these tools.
Tool Design
The framework employs two distinct tools to evaluate the validity of formal statements:
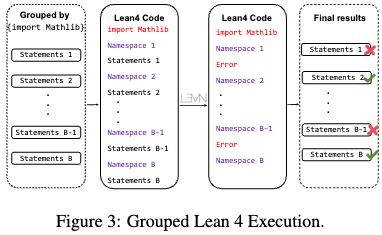
Syntax Check: This tool processes formal statements and returns compilation feedback from the Lean 4 compiler. To reduce execution overhead, it utilizes a pre-check stage to filter out statements with obvious errors, such as missing libraries or unmatched parentheses. Subsequently, it uses a grouped execution method where statements are batched based on import libraries, concatenated into a single code file, and executed simultaneously.
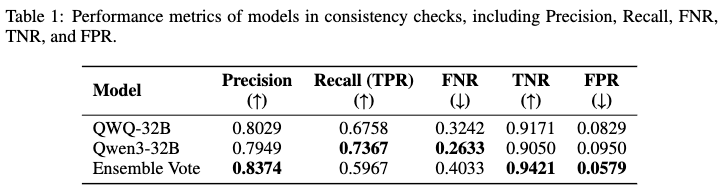
Consistency Check: This tool evaluates semantic equivalence between the informal query and the generated formal statement. It relies on a multi-LLMs-as-judge approach using an ensemble vote. Consistency is only confirmed when both evaluating models return identical conclusions, which reduces the false positive rate when identifying minor inconsistencies.
Training Pipeline
The training process for ATF utilizes a subset of the NuminaMath-1.5 dataset and consists of three stages:
- Cold Start for Tool Integration: The model is fine-tuned on synthetic multi-turn tool invocation trajectories. The data enforces specific execution rules: the syntax check must be invoked after any revision, the consistency check is only permitted after the syntax check passes, and the process stops when both checks pass.
- Expert Iteration: The model generates formalization attempts on the remaining mathematical queries. Trajectories that result in successful formalization with fewer than 8 revision attempts are collected and merged with previous training data to further refine the model’s formalization capabilities.
- Direct Preference Optimization (DPO): To reduce ineffective revisions (e.g., repeating the same syntax error), DPO is applied. For each query, a trajectory with fewer revision attempts is selected as the positive sample (\(y_w\)), and one with more attempts is selected as the negative sample (\(y_l\)). The training uses a DPO loss combined with a negative log-likelihood (NLL) loss on the chosen trajectories:
where \(\pi_\theta\) is the policy model, \(\pi_{\text{ref}}\) is the reference model, \(\beta\) is the temperature parameter, \(\alpha\) is the weighting coefficient, and \(\sigma\) represents the sigmoid function.
Experiments
Experimental Setup
Models were trained using full-parameter fine-tuning. Evaluations were conducted on three Automated Theorem Proving (ATP) datasets: FormalMath-Lite, ProverBench, and CombiBench. Metrics include Syntactic Validity (SC) and Semantic Consistency (CC). Generated statements were sampled 16 times per query to report Pass@1, Pass@8, and Pass@16 rates.
Main Results
ATF was compared against baseline formalizer models across the three benchmarks. The evaluation indicates higher pass rates for both syntax and consistency metrics across all three datasets.
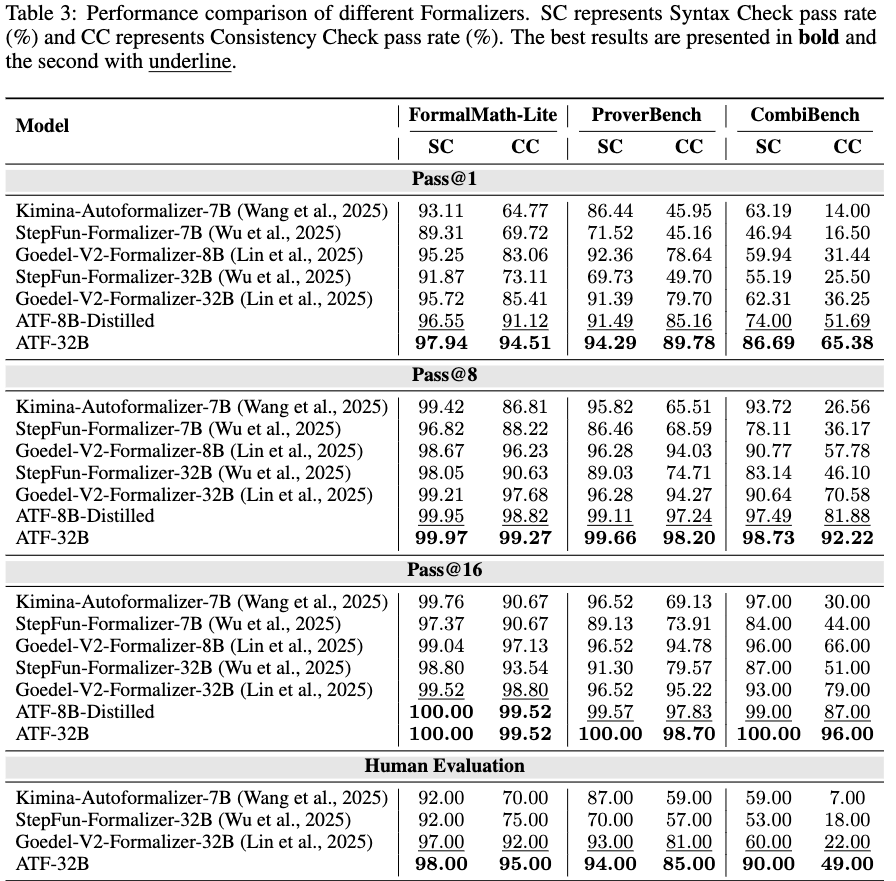
On the out-of-distribution CombiBench dataset, which features combinatorial mathematical problems, the ATF-32B model maintained a Pass@1 consistency score of \(65.38\%\). Increased sampling rates (Pass@16) yielded consistency scores of \(100\%\) on CombiBench and \(99.52\%\) on FormalMath-Lite for the 32B model. The distilled 8B version of the model yielded a Pass@1 consistency of \(91.12\%\) on FormalMath-Lite.
Ablations
Ablation studies were conducted by systematically removing the consistency check or both tools entirely.
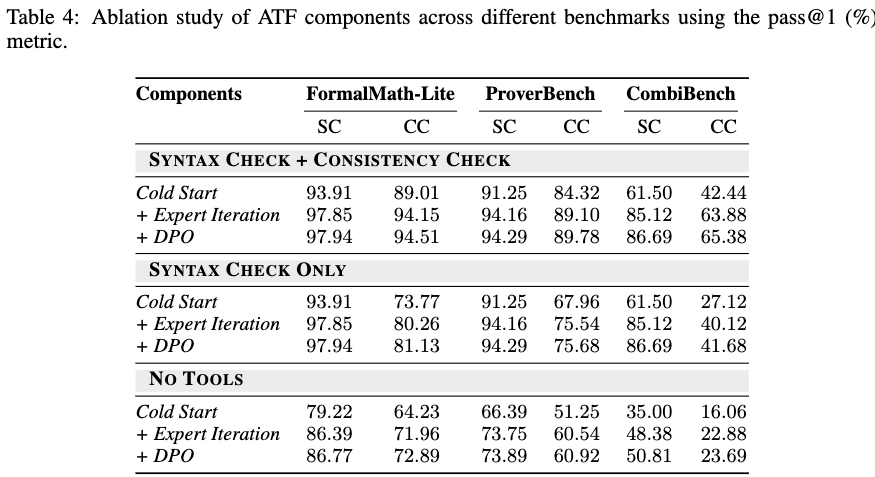
Removing tool guidance entirely results in a decrease in consistency check pass rates across all benchmarks. Including only the syntax check provides partial improvements, while combining both tools yields the highest semantic consistency. The staged training approach (Cold Start \(\rightarrow\) Expert Iteration \(\rightarrow\) DPO) shows cumulative pass rate increases at each phase.
Scaling and Tool Analysis
Inference scaling properties were tested by extending the maximum allowed revision attempts and parallel sampling counts (\(k\)).
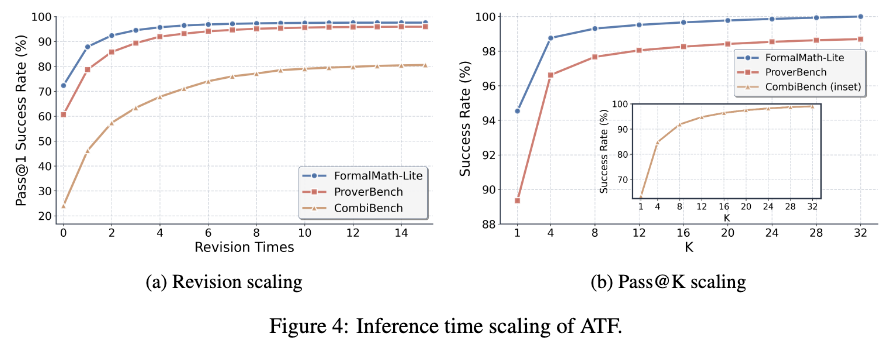
Pass rates on consistency checks continue to scale as the number of revision attempts increases, despite the model being trained with a strict limit of fewer than 8 revisions. Parallel sampling further increases the overall pass rate.
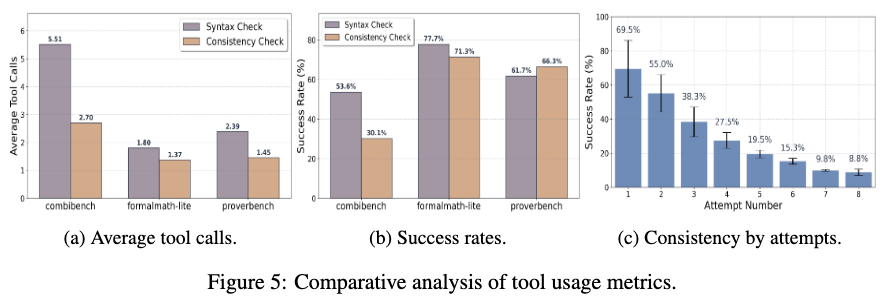
Tool usage frequency varies depending on the dataset; combinatorial queries in CombiBench required more tool calls on average than queries in FormalMath-Lite. Analysis of revision efficiency indicates that the success rate of the consistency check decreases with each subsequent revision attempt, dropping from \(69.5\%\) on the first attempt to \(8.8\%\) on the eighth attempt.