2510.01346v2.pdf
Aristotle is an automated theorem proving system that integrates a Lean proof search algorithm, an informal reasoning pipeline, and a dedicated geometry solver.
Read Paper →Method
The Aristotle system is composed of three primary subsystems: a Lean proof search algorithm, a lemma-based informal reasoning system, and a geometry solver. They did not publish any code and are a bit secrative about their methods, which is expected from a company.
Search Algorithm
The proof search algorithm is based on Monte Carlo Tree Search (MCTS) with a learned value function, adapted for the Lean 4 environment. The system uses a generative policy to sample actions from the space of Lean tactics, progressively widening the samples. The policy and value function condition on the Lean proof state, proof history, and an informal proof if available.
States and Actions Search is initialized from a collection of Lean states generated by an initial code snippet. States are split by goals, provided no metavariables are present across multiple goals. An action consists of a text string representing a fragment of Lean code (tactics and informal comments). Because actions can result in multiple states, the search space forms a hypertree.
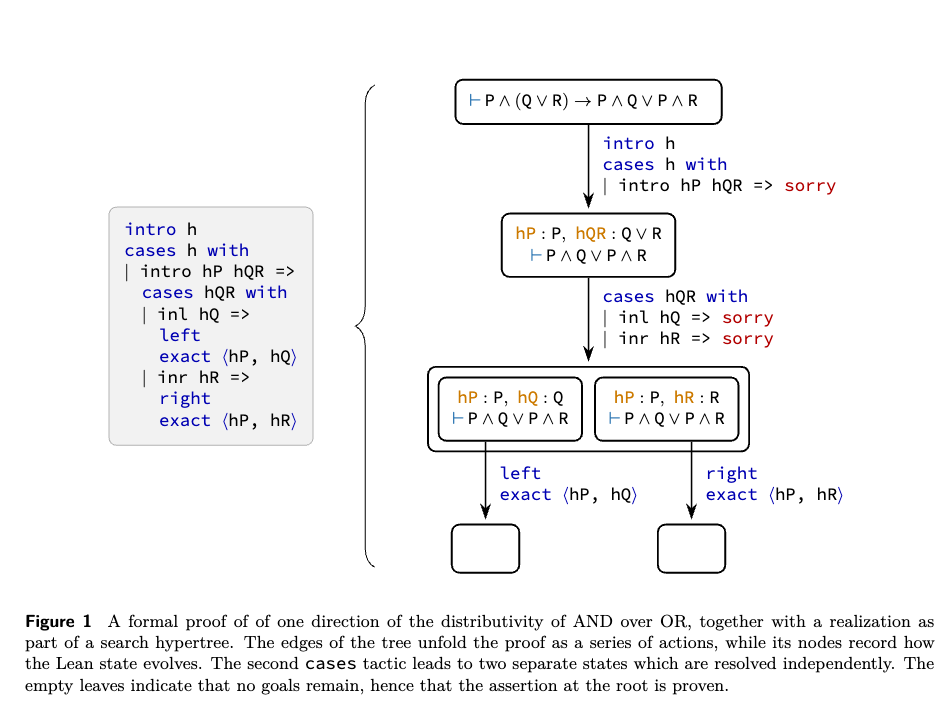
Equivalences and Graph Search States are treated as equivalent if their goal expressions, local context expressions, and local variable names match. Actions are equivalent if they produce equivalent state transitions. This equivalence collapses the search hypertree into a search hypergraph, allowing the system to operate via Monte Carlo Graph Search (MCGS).
Search Strategy The search applies a variant of the Predictor Upper Confidence bound applied to Trees (PUCT) formula, using the empirical distribution of actions sampled from the generative model as a prior policy. The search resolves an AND/OR structure: an action is successful only if all its resulting states are proven (AND), while a state is proven if any single action succeeds (OR). The search allocates budget by exploring actions with the highest upper-confidence bound and prioritizing the resulting states with the lowest lower-confidence bound. To facilitate pruning, each single-goal state is augmented with a state transition representing the logical negation of the goal.
Interleaving Informal Reasoning The model outputs formal Lean code alongside informal comments and a hidden chain of thought. The chain of thought uses a dynamic compute budget before predicting an action. These elements are co-evolved using reinforcement learning (RL).
Reinforcement Learning and Test-Time Training A single pretrained large language model serves as both the policy and value function. It is trained via expert iteration on a dataset of formalized mathematical statements. The generative policy is trained on proofs found by search, while the value function is trained on proven states and heavily explored unproven/disproven states.
During inference, Test-Time Training (TTT) is applied iteratively:
- The system attempts to solve the main problem and generated lemmas.
- If unresolved, the model is retrained on the search traces from these attempts.
Lemma-based Reasoning
To leverage higher-level informal reasoning, the search algorithm is embedded within a lemma generation pipeline that interfaces with the Lean REPL.
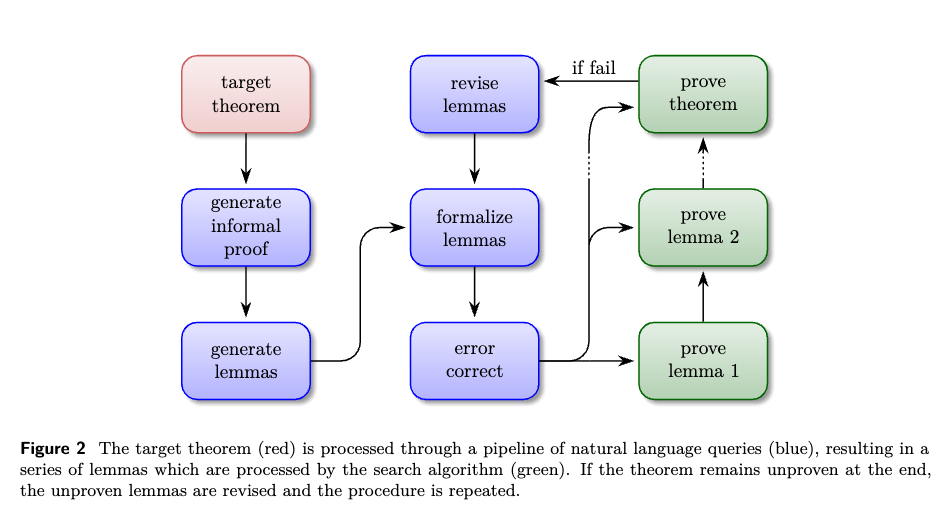
Lemma Generation Pipeline The target theorem is processed through a sequence of queries:
- Generation of an informal proof.
- Restructuring the informal proof into a sequence of granular lemmas.
- Autoformalization of the lemma statements into Lean.
- Execution in the Lean REPL, followed by error-correction queries based on the returned error messages.
Iteration with Formal Feedback If the initial attempt fails, the lemmas are annotated as proved or unproved. The pipeline is then rerun with a prompt instructing the model to revise the unproved lemmas, formulate a new strategy, and generate a new collection of lemmas, which are subsequently formalized and error-corrected.
Geometry Solver
The geometry solver operates outside of Lean using a C++ Deductive Database/Algebraic Reasoning (DD/AR) engine called Yuclid.
Optimizations and Features
- Numerical rule matcher: Identifies numerically true hypotheses and conclusions (e.g., similar triangles, midpoints) before the main DD/AR loop.
- AR optimizations: Uses Gaussian elimination with caching. The current echelon form of the linear system and reduced forms of statements are stored to prevent redundant computation.
- Squared lengths table: Introduces an AR table for squared lengths to compute generalized Pythagorean configurations efficiently:
Experiments
The system was evaluated on the 6 problems from the 2025 International Mathematical Olympiad (IMO). Informal problem statements were manually translated into formal Lean statements, while all intermediate lemmas were autoformalized by the system. The model used for these evaluations contained over 200 billion parameters and executed multiple parallel instances of the lemma-based reasoning pipeline.
Aristotle generated formally verified solutions for 5 of the 6 problems (all except Problem 6).
- Problem 1 (Sunny Lines): The system produced an algebraic proof analyzing derangements (permutations without fixed points) and explicitly checking counterexamples up to \(n = 5\) to establish the bounds, bypassing standard geometric convexity arguments.
- Problem 3 (Bonza Functions): The problem required characterizing functions \(f : \mathbb{N} \to \mathbb{N}\) obeying the congruence \(b^a \equiv f(b)^{f(a)} \pmod{f(a)}\). The system correctly defined an unprompted auxiliary set \(S = \{p \mid \text{Prime}(p) \land f(p) > 1\}\) to construct the proof.
- Problem 4 (Sums of Three Divisors): During formalization, the system identified and repaired logical inconsistencies present in its generated informal reasoning, specifically distinguishing between strictly decreasing and weakly decreasing sequences.
- Problem 5 (Inekoalaty Game): The system defined an invariant function \(f(k) := k\sqrt{2}/(2k - 1)\) to structure the proof. It utilized the
filter_upwardstactic to formalize the limit properties of the function as it approached \(1/\sqrt{2}\).
Additional Evaluations Outside of the IMO 2025 benchmark, the system was evaluated on open problems and educational materials:
- Mathlib Contributions: The system proved theorems previously absent from Mathlib, including Niven’s theorem, the Gauss-Lucas theorem, and eigenvalue properties of characteristic polynomials.
- Real Analysis Validation: The system was tested on exercises from a Lean-based real analysis textbook. It identified four exercises that were logically false as written by constructing explicit counterexamples. For two other exercises, it completed the proofs while explicitly avoiding unnecessary hypotheses provided in the text. ```