Agentic Proof Automation A Case Study
A case study evaluating the use of large language model agents for mechanizing the semantic type soundness of a formal system in Lean 4.
Read Paper →Method
The approach utilizes general-purpose large language models (LLMs) configured as coding agents to perform proof engineering tasks in Lean 4. The setup employs models including Claude Sonnet 4.5, Claude Opus 4.5, Claude Opus 4.1, and GPT Codex 5.1, executing within standard agentic frameworks (Claude Code and Codex-CLI).
Agents are provided with four categories of tools:
- Code exploration: Searching files by pattern, grepping for definitions, and reading file contents.
- File modification: Creating and editing files at specific locations.
- Lean 4 building: A custom tool named
lean4checkthat compiles a Lean 4 module and returns the result. Upon failure, it outputs the error message accompanied by the enclosing source context.
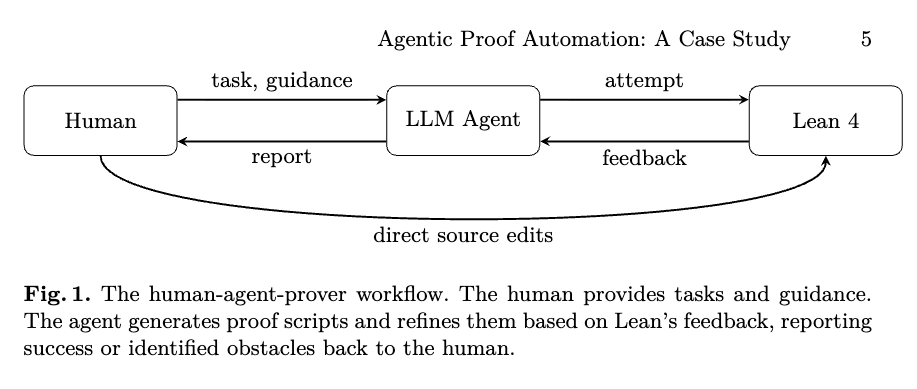
The human-agent interaction follows a continuous feedback loop. The human provides definitions, theorem statements, and informal proof strategies as comments. The agent explores the codebase to locate relevant definitions and lemmas, generates a proof script, and invokes lean4check. If the compiler returns an error, the agent interprets the message and refines the proof script. This cycle repeats until the proof compiles or the agent determines human intervention is necessary.
Human guidance is categorized into two levels:
- System-level instructions: Persistent configuration rules defining tool preferences, tactic idioms, and debugging procedures.
- Task-level prompts: Specific directives that can be directive (stating the goal), strategic (suggesting a specific lemma or approach), incremental (decomposing the proof into steps), onboarding (directing the agent to read documentation), or autonomous (delegating extended loops of error-fixing).
The target of this case study is the mechanization of semantic type soundness for System Capless, a foundational calculus for capture tracking. The system augments ordinary types with capture sets, denoted as \(S \wedge C\), where \(S\) is a shape type and \(C\) is a capture set. The core typing judgment is written as:
\[C; \Gamma \vdash t : E\]where \(C\) over-approximates the capabilities the term \(t\) may use during evaluation to an answer \(E\), and \(\Gamma\) is the typing context. The mechanization consists of over 14,000 lines of Lean 4 code. It uses a logical relations approach, interpreting types as predicates over memory states and expressions.
Experiments
Interactions between the human and the agent were recorded and segmented into 189 tasks across 58 sessions. A task is defined as a human request followed by agent responses until completion or abandonment. Tasks were classified into six categories:
- Proof: Synthesizing a proof for a provided theorem statement.
- Repair: Fixing existing proofs broken by definition changes.
- Refactor: Updating definitions and proofs based on natural language instructions.
- State and Prove: Formalizing and proving a natural language property.
- Query: Answering questions regarding the codebase.
- Chore: Routine maintenance, such as fixing style warnings.
Task outcomes were annotated as Success, Success with intervention (requiring human hints or edits), Partial, Failure, or Problem identified.
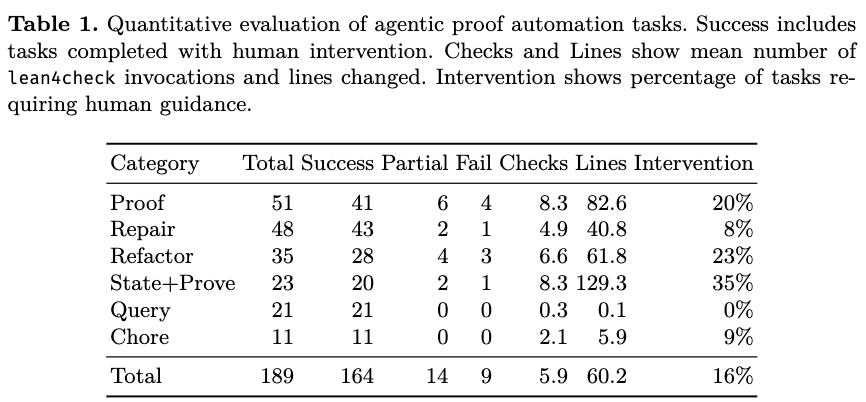
Overall, the agents completed 164 out of 189 tasks (87%). Of the completed tasks, 16% required human intervention. There were 9 total failures (5%).
Performance varied based on the task category. The agents achieved a 100% success rate on Query and Chore tasks. For proof-related tasks, the agents demonstrated the highest success rate in Repair tasks (90%, or 43/48), requiring 8% human intervention and an average of 4.9 lean4check invocations. Proof tasks required an average of 8.3 compiler invocations. State and Prove tasks recorded the highest intervention rate at 35% and produced an average of 129 lines of code, as they required the agent to resolve ambiguity during the translation of natural language into formal specifications. Refactor tasks averaged 6.6 compiler invocations.
Analysis of the interaction logs identified specific operational limitations:
- Proof state handling: Agents misused certain prover-specific idioms with non-obvious semantics. For example, Lean 4’s
rename_itactic names anonymous hypotheses starting from the bottom of the context rather than the top, which agents frequently applied incorrectly despite system-level instructions. - Context retrieval: Agents failed to retrieve relevant lemmas when the naming conventions did not closely match the active goal or when lemmas were located in unexpected modules, leading to attempts to re-prove existing theorems.
- Long-term planning: In complex proofs requiring multi-step decomposition and the introduction of non-trivial auxiliary lemmas, agents failed to synthesize the intermediate steps autonomously, requiring incremental human prompts to complete the task.