A Minimal Agent for Automated Theorem Proving
An evaluation of a modular agent architecture for automated theorem proving in Lean 4 featuring iterative refinement, context management, and search tools.
Read Paper →Method
The system is structured as a modular agent architecture for theorem proving in Lean 4. It consists of a feedback loop driven by three primary components: a proposer agent, a review system, and a memory system.
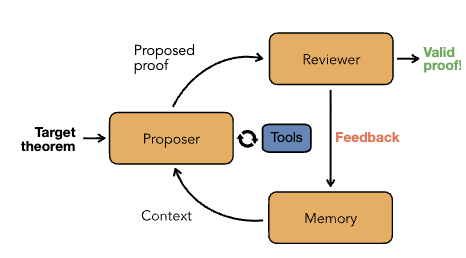
Proposer Agent The proposer is a ReAct-style agent based on a general-purpose large language model (LLM). Its objective is to output Lean code to complete a target theorem. The agent receives the target theorem, the associated file context, and the history of prior failed attempts provided by the memory module. Before generating a proof, the agent can execute parallel calls to two search tools:
- Library Search: A custom instance of LeanSearch utilizing vector embeddings to perform premise selection over Mathlib.
- Web Search: Tavily API integration to retrieve proof strategies.
Review System The review system consists of a programmatic compiler and an LLM-based reviewer agent.
- The compiler executes
lake buildon the proposed Lean code. If compilation fails, it returns the specific compilation errors. If the code compiles but containssorrytactics, the compiler extracts the intermediate goal states at those exact locations using LeanInteract and returns them to the proposer. - If the code compiles with no
sorrytactics, the reviewer agent checks the proof deterministically against known loopholes and verifies that the original theorem signature was not modified.
Memory The memory module preserves information across iterative proof attempts to prevent the proposer from repeating failed strategies. Three memory implementations are evaluated:
- No memory: The proposer receives no context from past attempts.
- History of previous \(n\) attempts: The proposer receives the reasoning, code, and compiler feedback of the \(n\) most recent attempts.
- Self-managed context: A self-reflection strategy where the agent maintains a short, persistent context block. After each iteration, the agent updates this context with technical insights and lessons learned, synthesizing the feedback without exceeding the model’s context length.
Experiments
Experiments were conducted in three phases: a component ablation study on a 100-problem subset of PutnamBench, an LLM comparison, and a final evaluation on standard mathematical benchmarks.
Bottom-up System Analysis The components of the architecture were added sequentially to measure their impact on pass@\(k\) performance.
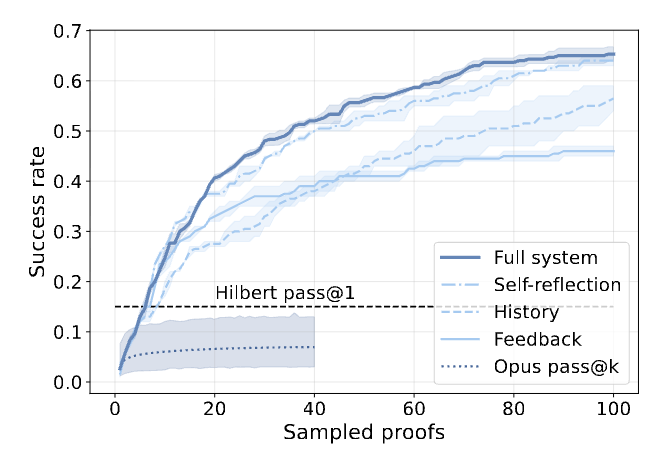
- Iterative Refinement: Replacing single-shot parallel sampling with iterative proof refinement based on compiler feedback provided the largest performance increase.
- Memory: Iterative refinement alone exhibited diminishing returns as the agent entered loops of repeated errors. Adding memory mitigated this. The self-managed context outperformed a static history of \(n=5\) attempts, yielding a 7% increase in proved theorems and a 20% reduction in total token cost.
- Tools: Providing Mathlib and web search tools yielded positive but marginal improvements compared to the introduction of feedback and memory.
Foundation Model Comparison The architecture was tested using Claude Sonnet 4.5, Claude Opus 4.5, Gemini 3 Flash, and Gemini 3 Pro, limited to 50 iterations with self-managed memory and search tools.
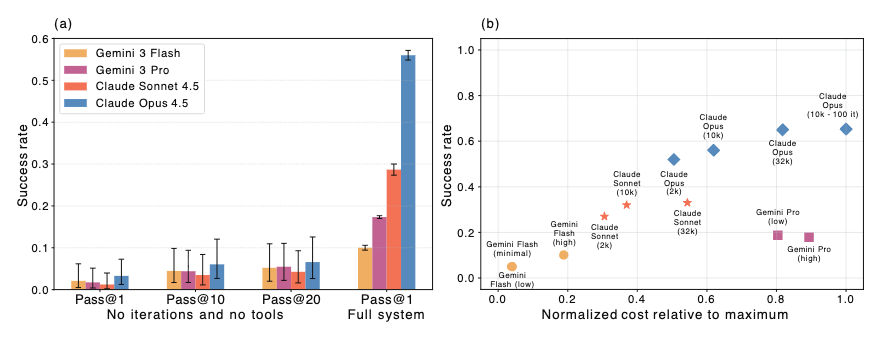
- Model Performance: The agentic framework increased performance across all models compared to single-shot generation. The Claude models solved approximately three times more theorems than their Gemini counterparts. Analysis of trace logs indicated that the Gemini models frequently hallucinated imports or referenced deprecated Lean/Mathlib versions.
- Thinking Budget: Adjusting the thinking budget (tokens allocated to chain-of-thought before answering) impacted performance and cost. Gemini 3 Pro and Gemini 3 Flash showed minimal changes across thinking modes. Claude Sonnet 4.5 saturated at higher budgets, while Claude Opus 4.5 demonstrated steady performance gains as the budget was increased to \(32,000\) tokens.
Benchmark Dataset Evaluations The optimal configuration (Claude Opus 4.5, \(32,000\) thinking tokens, maximum 50 iterations, self-managed memory, and search tools enabled) was evaluated on standard datasets measuring competition math, abstract algebra, and category theory capabilities.
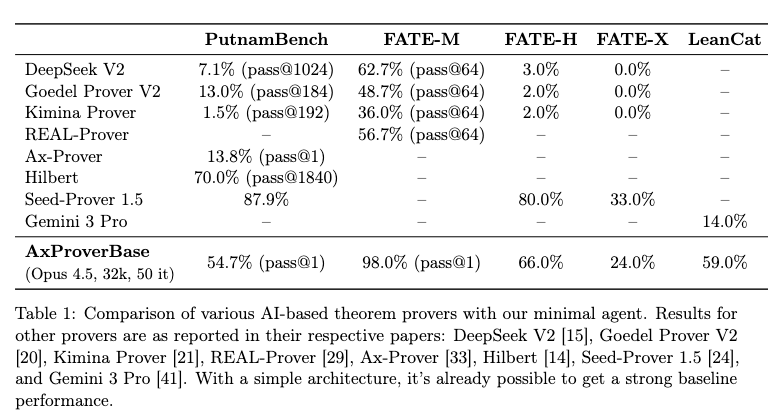
The agent achieved the following pass@1 success rates:
- PutnamBench: 54.7%
- FATE-M: 98.0%
- FATE-H: 66.0%
- FATE-X: 24.0%
- LeanCat: 59.0%
Average execution cost across datasets was recorded at $12.60 per problem.