APOLLO Automated LLM and Lean Collaboration for Advanced Formal Reasoning
A modular framework that coordinates large language models, the Lean compiler, and automated solvers to repair and verify formal mathematical proofs.
Read Paper →Method
Apollo is an automated system that directs a process in which a Large Language Model (LLM) generates formal proofs, and a set of agents analyzes these proofs to correct syntax errors, isolate failing sub-lemmas, utilize automated solvers, and recursively query the LLM to resolve open goals. The pipeline relies on the Lean REPL, which provides a list of compilation errors, warnings, and source locations used to drive dynamic code repair and sub-problem extraction.
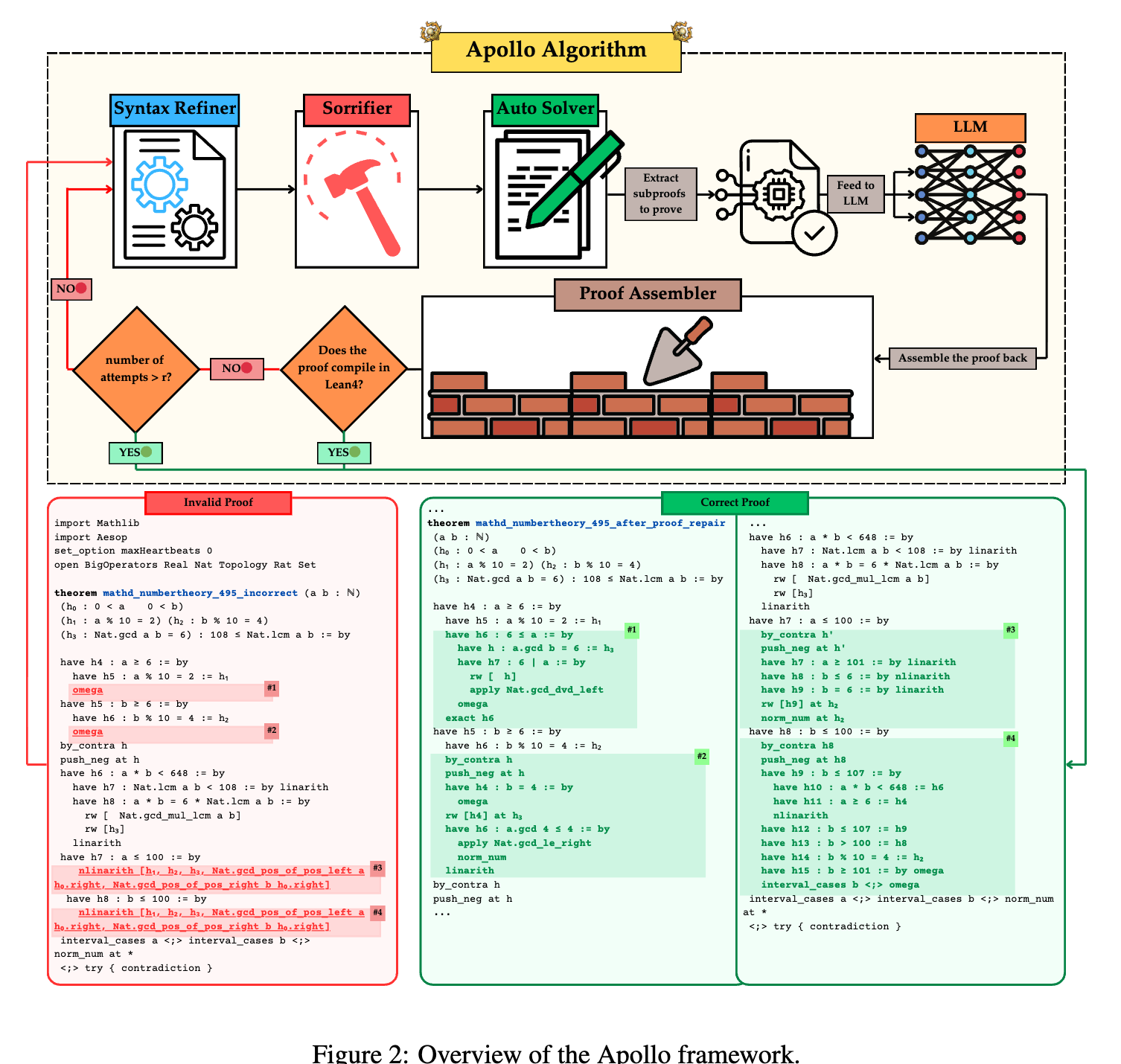
The framework consists of five primary components:
Syntax Refiner
The Syntax Refiner catches and corrects superficial compilation errors in LLM-generated Lean code, such as missing commas, incorrect keywords (e.g., Lean 3’s from vs. Lean 4’s := by), and misplaced brackets. This module uses rule-based corrections and regular expressions to normalize common formatting mistakes, ensuring that subsequent stages operate on syntactically valid code.
Sorrifier
The Sorrifier patches remaining compilation failures by inserting Lean’s sorry placeholder. The module parses the failed proof into a tree of nested proof-blocks (with sub-lemmas as children). It compiles the proof using the Lean REPL, detects the offending line or block, and applies one of three structural repairs:
- Line removal, if a single tactic is invalid but the surrounding block is viable.
- Block removal, if the entire sub-proof is malformed.
- Inserting
sorry, if the block compiles but leaves unsolved goals open.
This process repeats until the file compiles without errors. Each remaining sorry marks a specific sub-lemma that the model failed to prove.
Auto Solver
The Auto Solver targets each sorry block sequentially. It first invokes Lean 4’s hint function to identify candidate tactics that fully discharge the goal. If open goals persist, it systematically applies built-in Lean solvers (e.g., nlinarith, ring, simp, norm_num) wrapped in try statements to test tactic combinations. Sub-goals that remain open after this step are left marked with sorry.
Recursive Reasoning and Repair
If a proof contains sorry statements after the Auto Solver stage, Apollo extracts the local context for each statement—including hypotheses, definitions, and prior proved lemmas. It treats each unsolved block as a new lemma and recursively prompts the LLM to generate a sub-proof. This generated sub-proof is then passed through the verification, syntax refining, sorrifying, and Auto Solver stages. This recursive decomposition continues up to a user-specified recursion depth \(r\).
Proof Assembler
The Proof Assembler splices all repaired blocks back into a single file and verifies the absence of sorry or admit commands. If the combined proof fails compilation, the entire pipeline repeats (bounded by the recursion depth \(r\)), allowing for additional rounds of refinement.
Experiments
Apollo is evaluated on the miniF2F-test dataset, which contains 244 formalized problems from AIME, IMO, and AMC competitions, as well as the PutnamBench dataset. Experiments utilize Lean v4.17.0 and are executed on NVIDIA A5000 GPUs. Unless otherwise stated, a top-\(K\) sampling budget of \(K=32\) is used for sub-proof generation.
Performance on Base Models
Apollo was applied to two whole-proof generation models: Goedel-Prover-SFT and Kimina-Prover-Preview-Distill-7B.
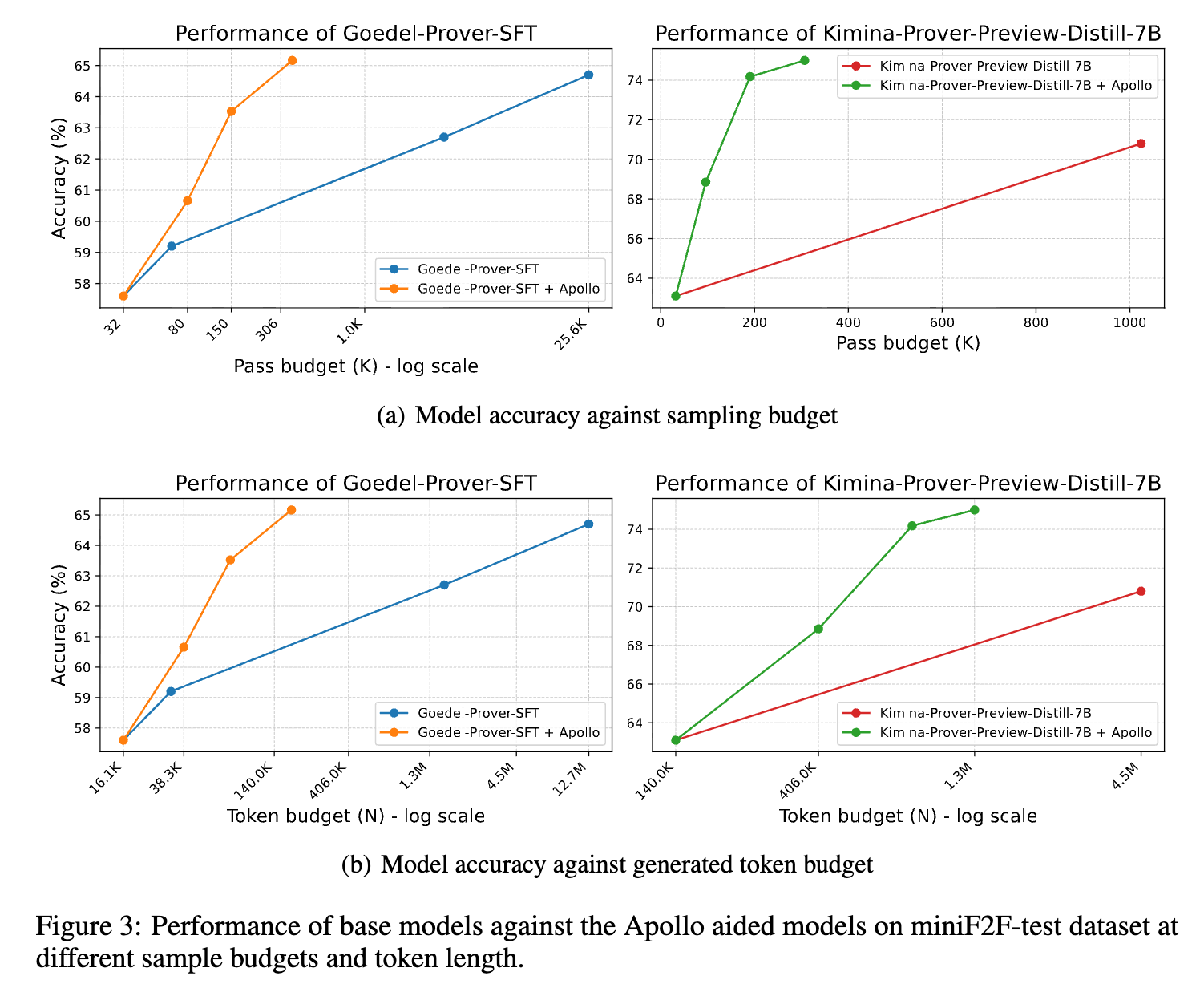
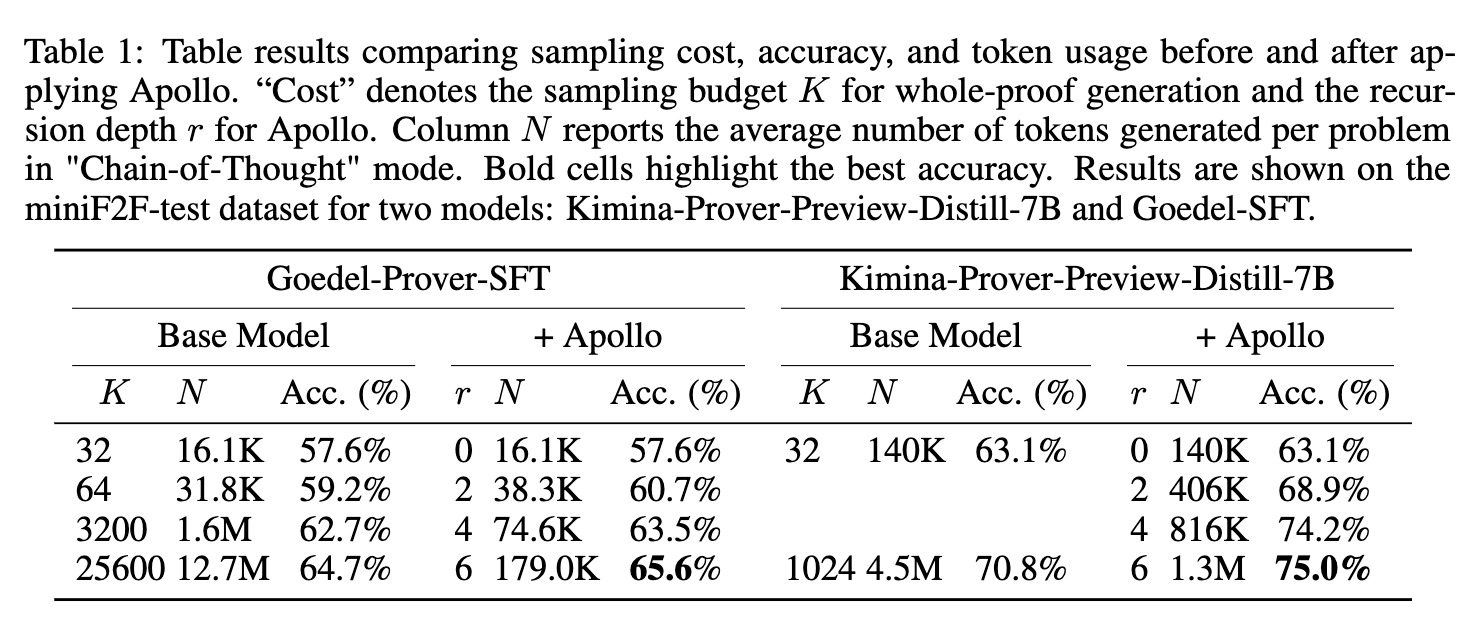
Applying the Apollo pipeline to Goedel-Prover-SFT yields an accuracy of 65.6% using an average of 362 generated samples per problem. By comparison, the standalone base model reaches 64.7% accuracy utilizing a sample budget of 25,600. For Kimina-Prover-Preview-Distill-7B, Apollo produces an accuracy of 75.0% using an average of 307 samples, compared to the base model’s 70.8% at a sample budget of 1,024. Table 1 details the accuracy and token usage scaling.
Comparison with LLMs
Apollo’s token efficiency and accuracy were evaluated against whole-proof generation and tree-search methods (e.g., BFS, MCTS) on the miniF2F-test partition. Token budgets are calculated over all generated tokens.
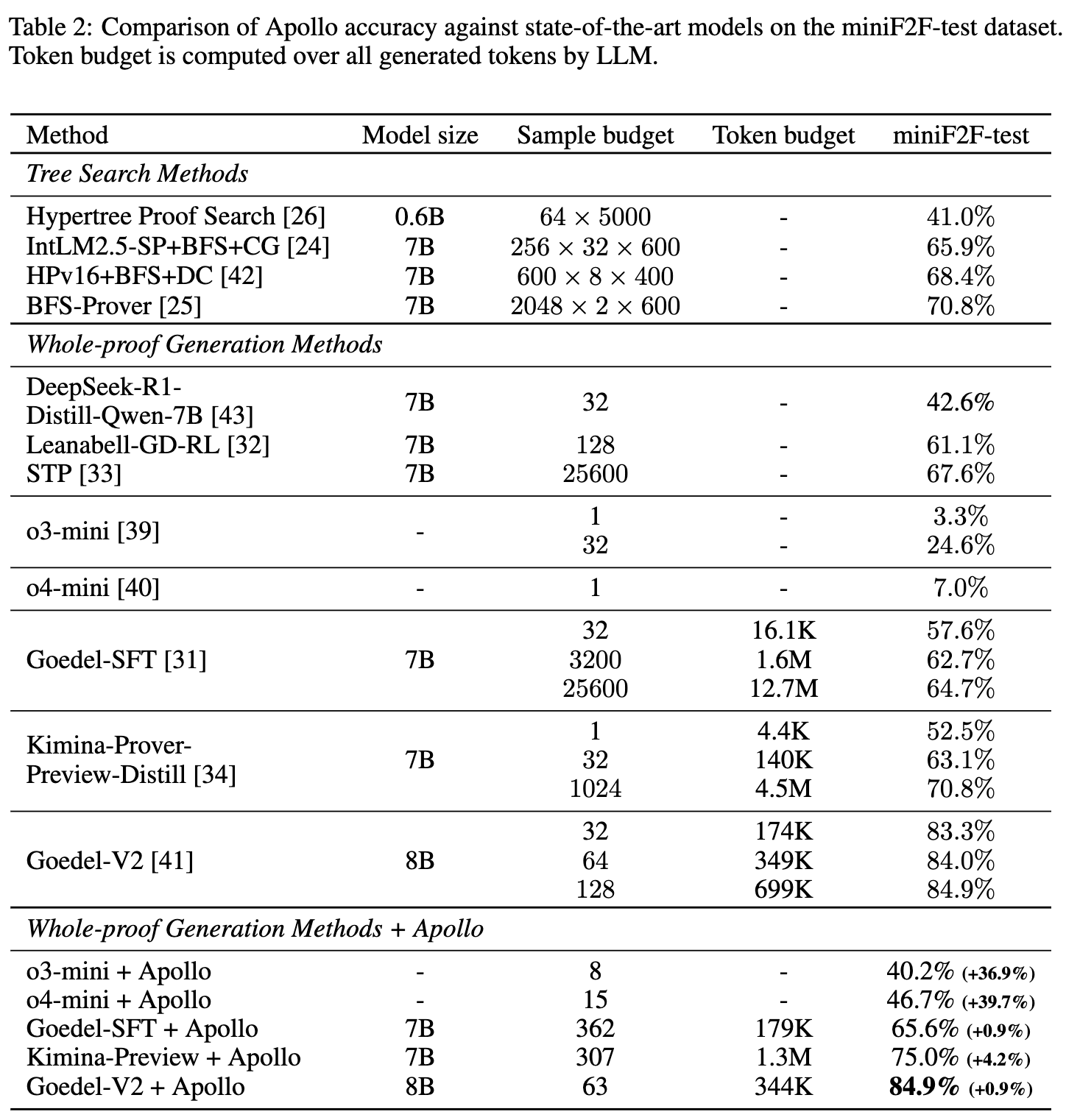
When integrated with the Goedel-V2-8B theorem prover, Apollo yields an accuracy of 84.9% with an average sampling budget of 63, whereas the standalone model requires a budget of 128 to reach the same accuracy. On general-purpose models not explicitly trained for Lean 4 (OpenAI o3-mini and o4-mini), base accuracies of 3.3% and 7.0% increase to 40.2% and 46.7%, respectively, after applying Apollo’s syntax corrections and solver-guided refinements.
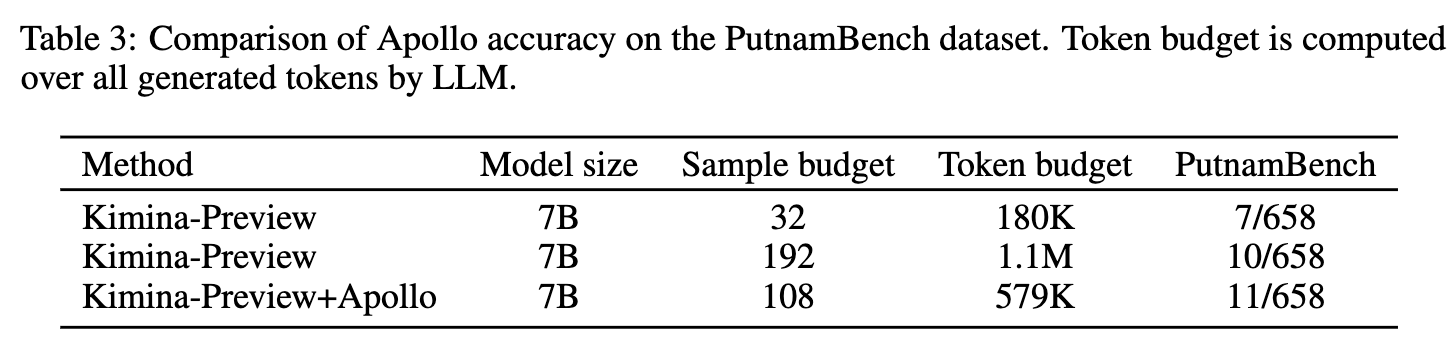
Evaluation on PutnamBench using Kimina-Prover-Preview-Distill-7B as the base model shows that Apollo produces 11 valid proofs using 579K tokens, whereas the standalone model produces 10 valid proofs using 1.1M tokens.
Distribution of Proof Lengths
The effect of Apollo on proof structure is measured using proof length, defined as the total number of tactics in a valid proof.
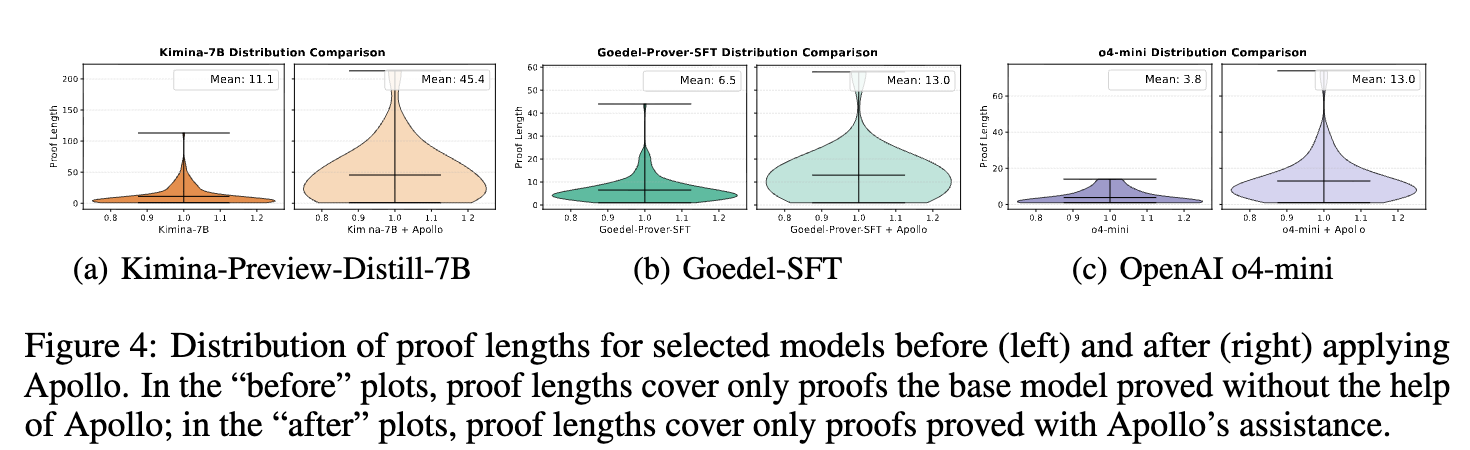
For proofs generated with Apollo’s assistance, the mean proof length increases by at least a factor of two across all tested base models (Kimina-Prover-Preview-Distill-7B, Goedel-Prover-SFT, and o4-mini) compared to proofs generated independently by the base models.
Impact of Recursion Depth
The effect of the recursion-depth parameter \(r\) on accuracy was evaluated for o4-mini (\(r = 0 \dots 4\)), Kimina-Prover-Preview-Distill-7B (\(r = 0 \dots 6\)), and Goedel-Prover-SFT (\(r = 0 \dots 6\)). A depth of \(r = 0\) represents the base model’s standalone performance.
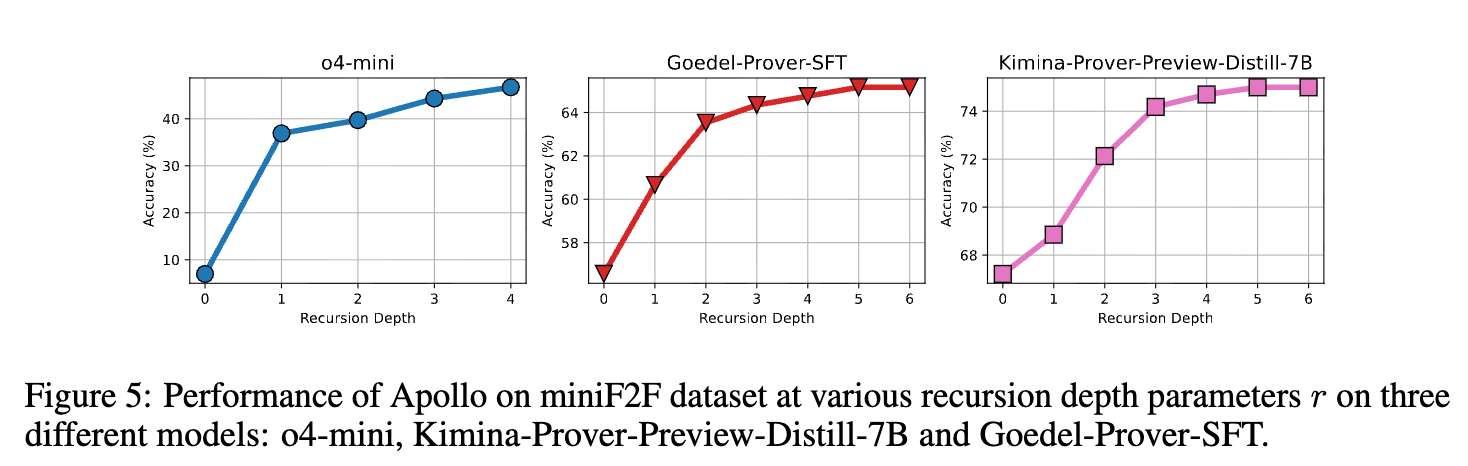
For o4-mini, the largest accuracy increase occurs between \(r = 0\) and \(r = 1\), followed by a plateau in subsequent depths. For Kimina-Prover-Preview-Distill-7B and Goedel-Prover-SFT, accuracy increases incrementally across higher values of \(r\). At \(r = 5\), the pipeline requires between 300 and 400 LLM requests on average.
Ablation Studies
An ablation study on the o4-mini and Kimina-Prover-Preview-Distill-7B base models isolated the contributions of the Syntax Refiner, Auto Solver, and LLM Re-invoker. The Sorrifier and Proof Assembler were retained in all configurations as they are required to parse and compile the file.

The Syntax Refiner provides an accuracy change for the general-purpose o4-mini model but does not alter the performance of the dedicated Kimina-Prover-Preview-Distill-7B prover. The Auto Solver produces minimal accuracy changes when used in isolation. The combination of the Auto Solver and the LLM Re-invoker yields the highest accuracy metrics for both model types.