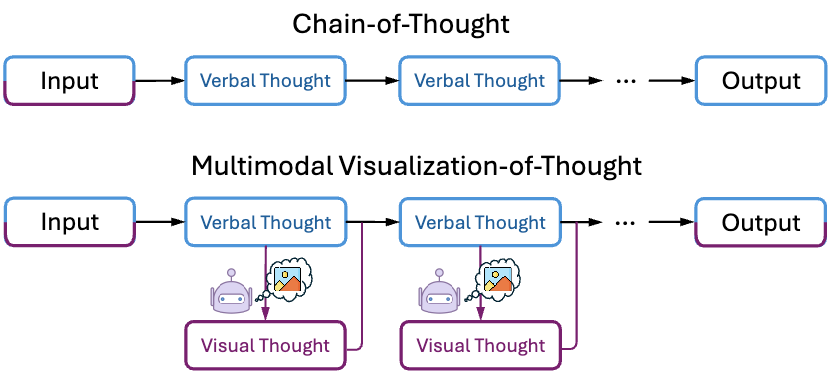
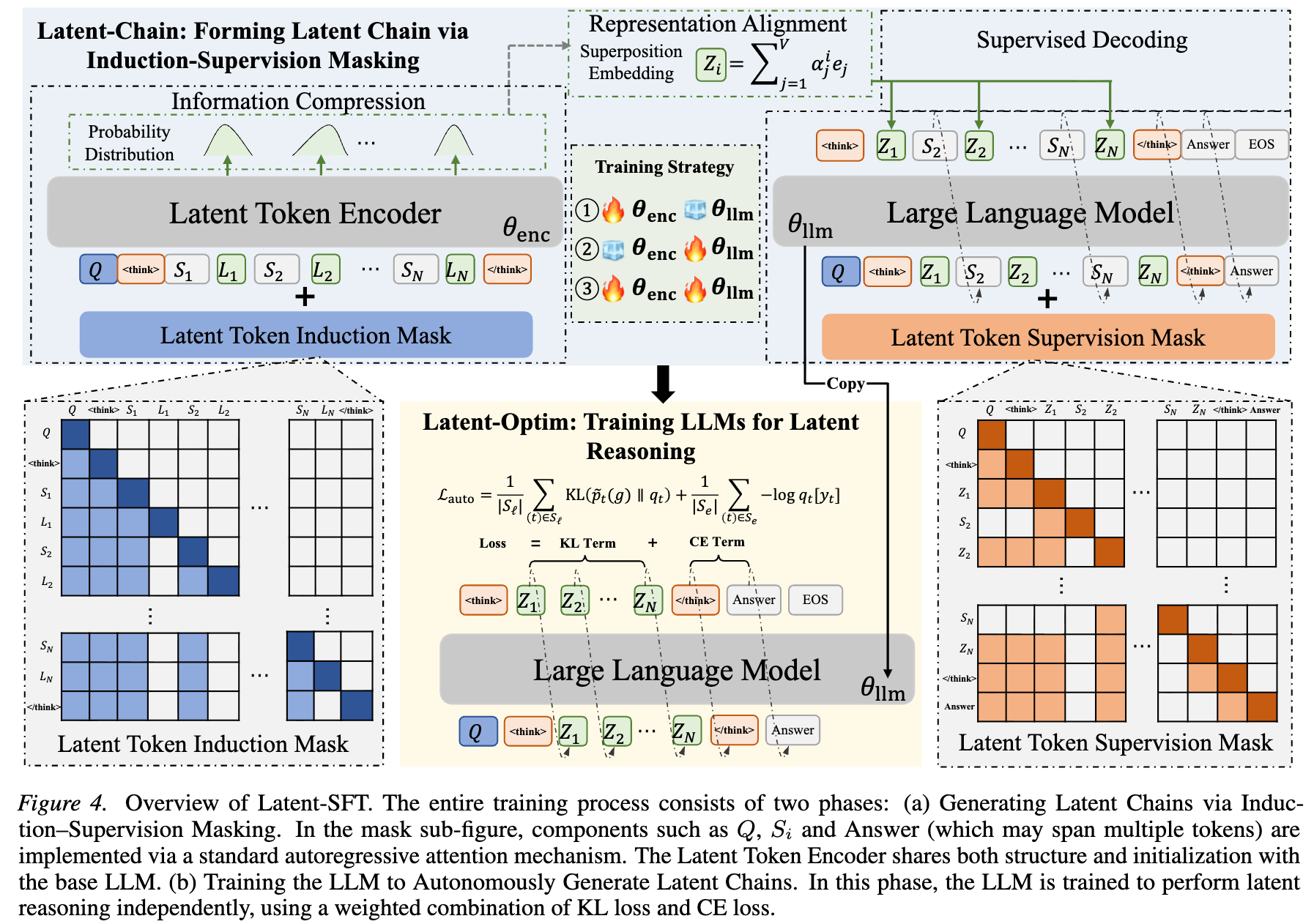
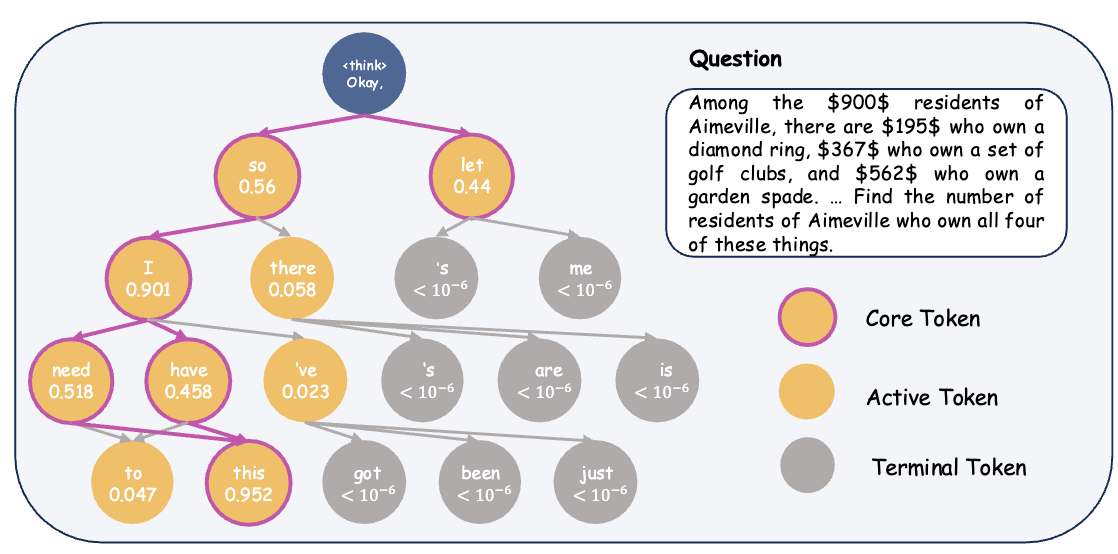
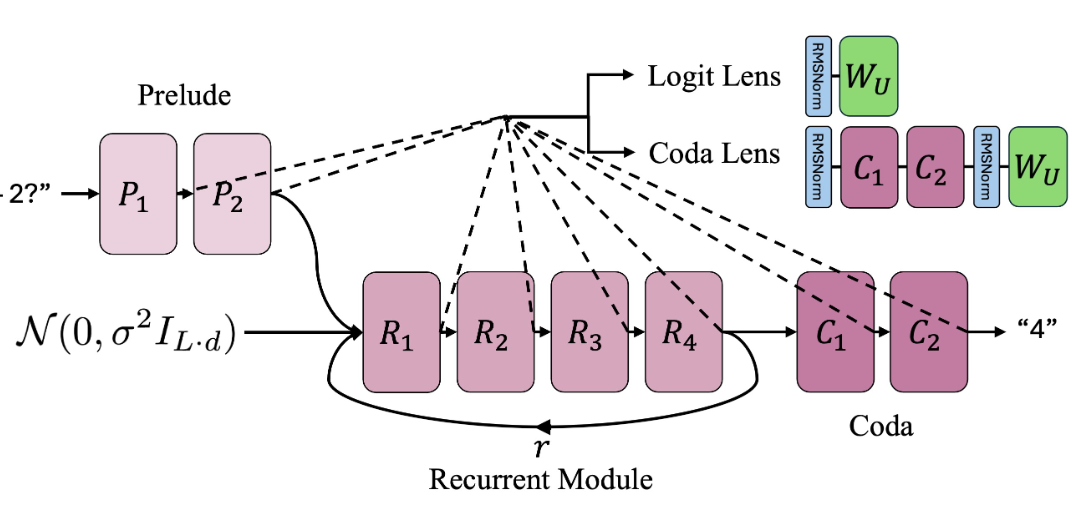
Chain of Images for Intuitively Reasoning
This paper proposes a Chain-of-Images (CoI) method for multimodal models to solve reasoning problems by generating a series of images as intermediate representations, using a Symbolic Multimodal Large Language Model (SyMLLM).

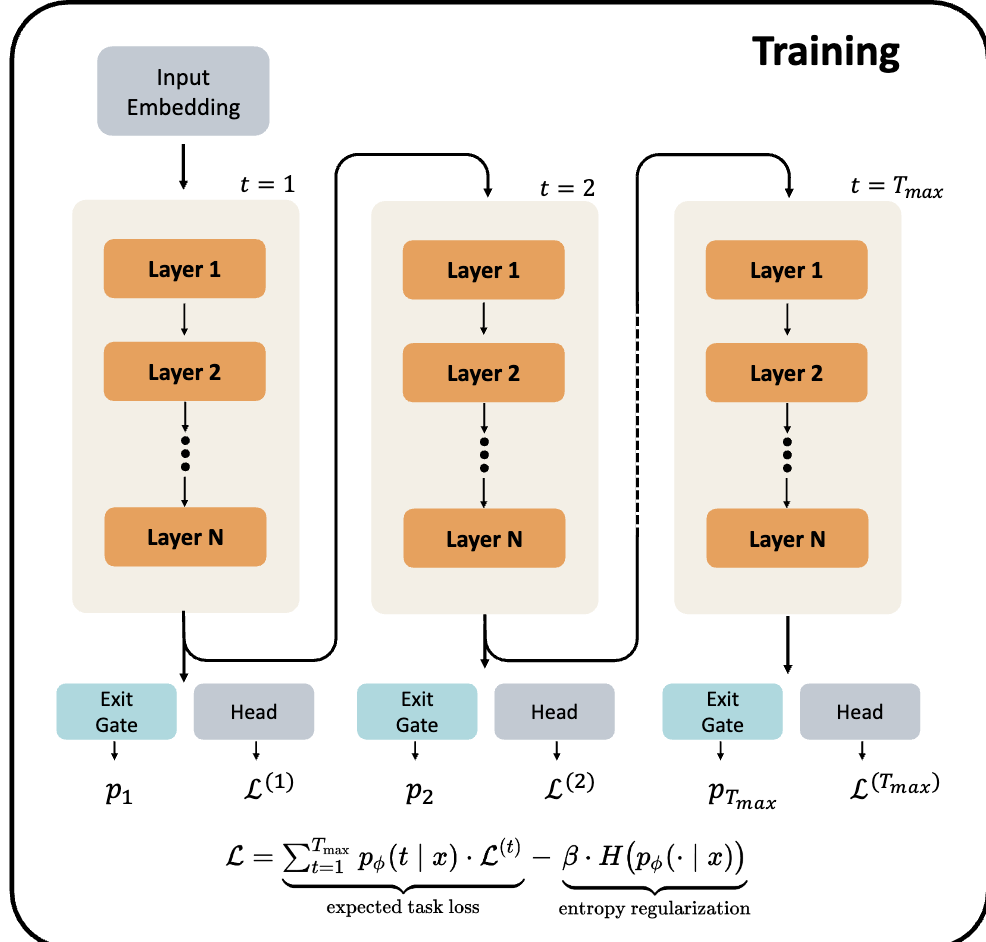
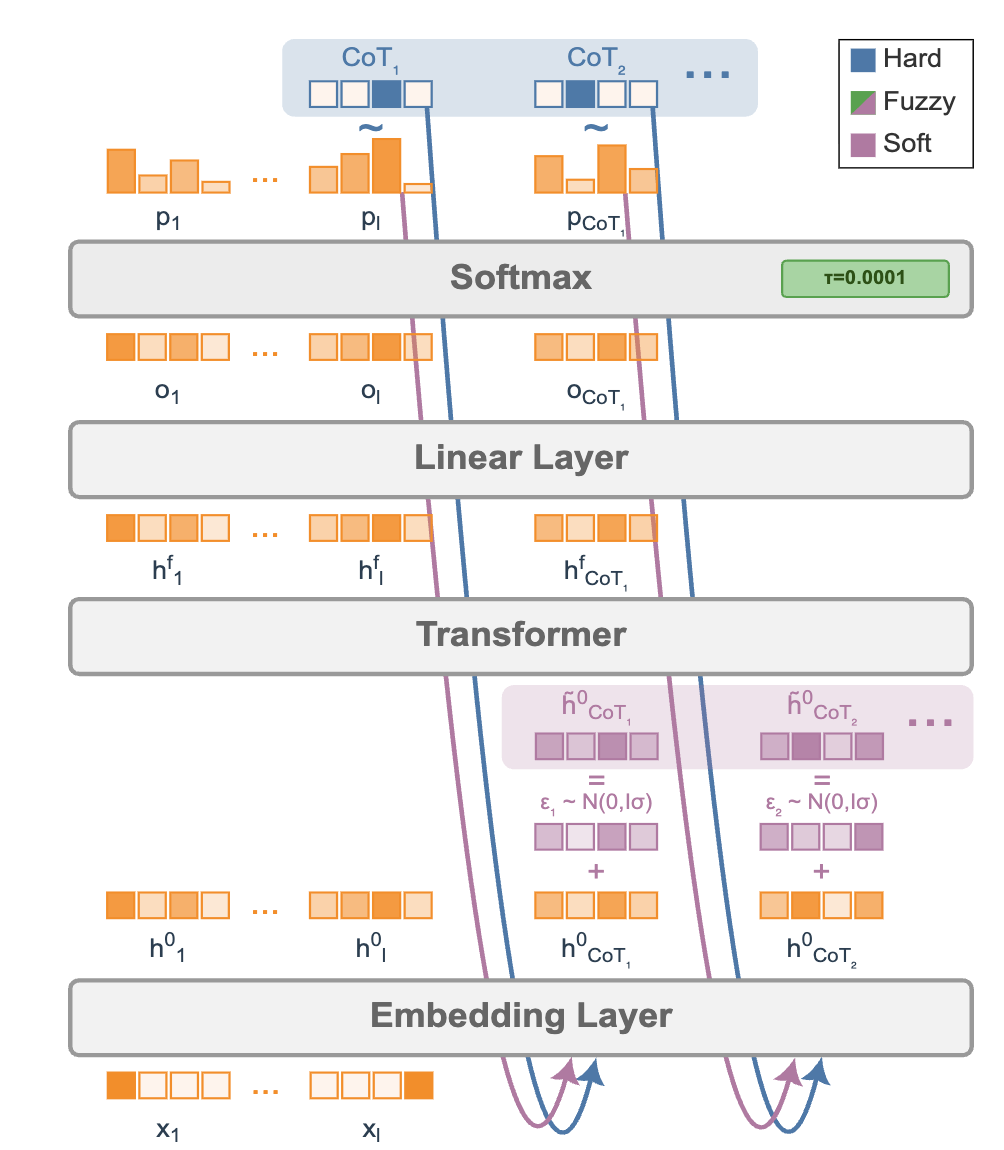



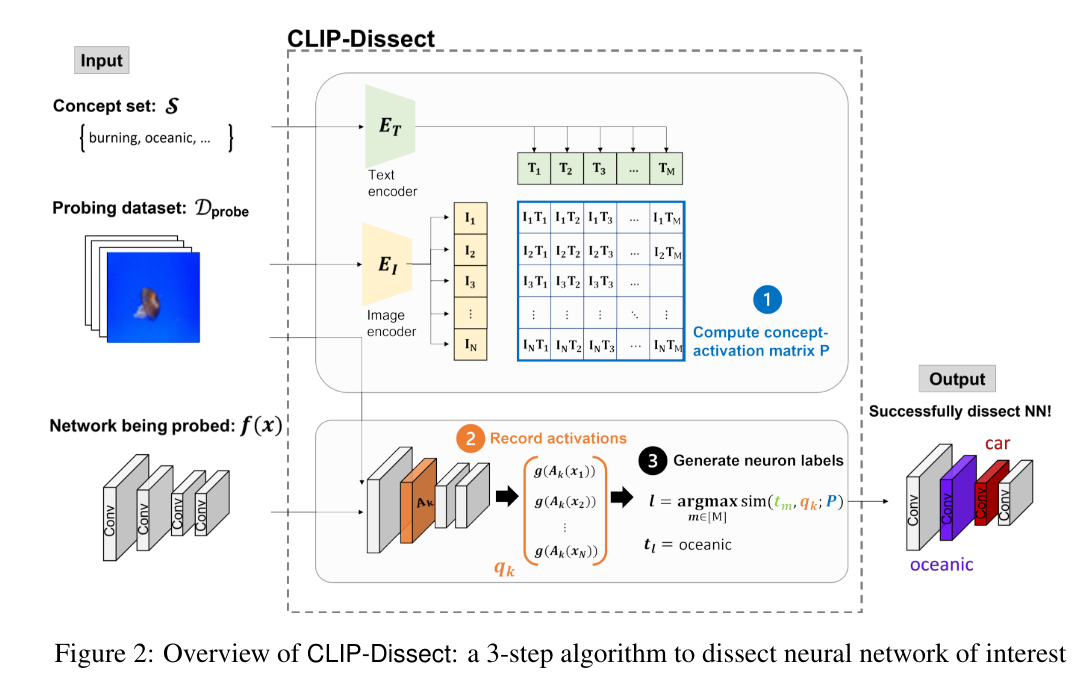




/image9.png)